Qwen 3.6 Max BS Benchmark 评测:反幻觉能力超越所有 OpenAI 模型
Qwen 3.6 Max Preview 在 BridgeBench BS Benchmark(反幻觉测试)中取得 94.5 分,排名全球第二,仅次于 Claude Opus 4.6 的 95.0 分。在拒绝生成虚假信息方面,Qwen 3.6 Max 超越了 GPT-5.4 和所有 OpenAI 模型。本文评测这一表现的意义。

全面评测主流AI模型,帮助你选择最适合的方案
Qwen 3.6 Max Preview 在 BridgeBench BS Benchmark(反幻觉测试)中取得 94.5 分,排名全球第二,仅次于 Claude Opus 4.6 的 95.0 分。在拒绝生成虚假信息方面,Qwen 3.6 Max 超越了 GPT-5.4 和所有 OpenAI 模型。本文评测这一表现的意义。
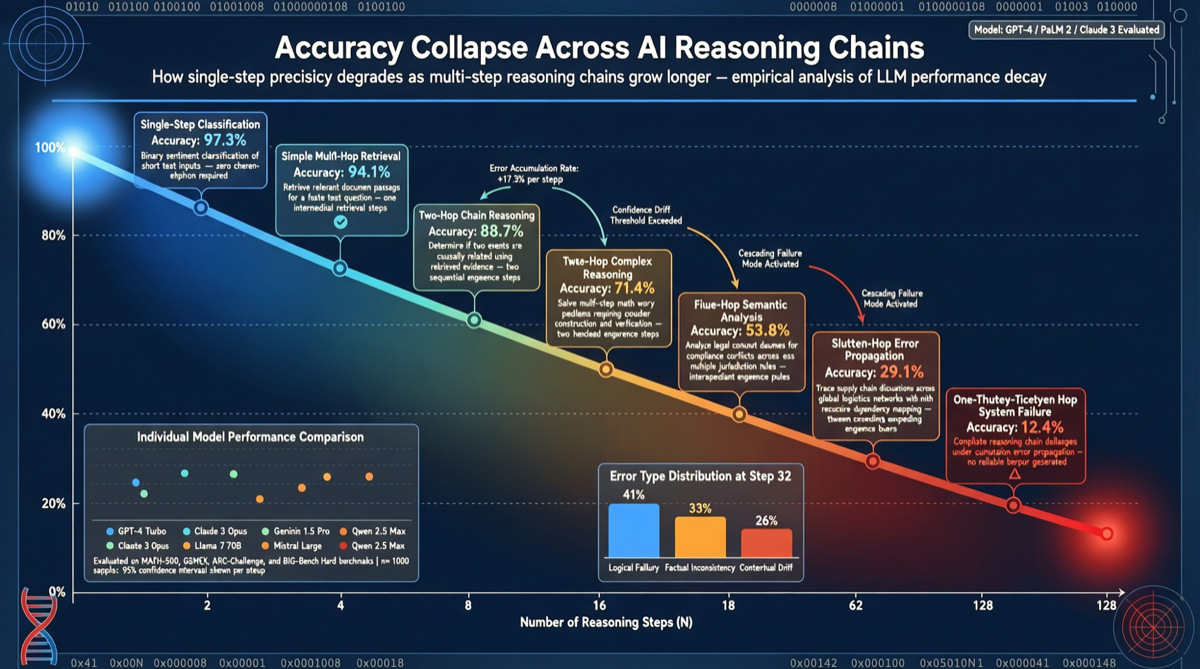
牛津大学与劳伦斯利弗莫尔国家实验室联合发布新基准,测试 AI 模型在长链条推理任务中的表现。GPT 5.2 在单项问题上的解决率达 95.7%,但将这些问题串联后准确率暴跌至 9.83%。本文评测这一发现对 AI 实际应用的深远影响。
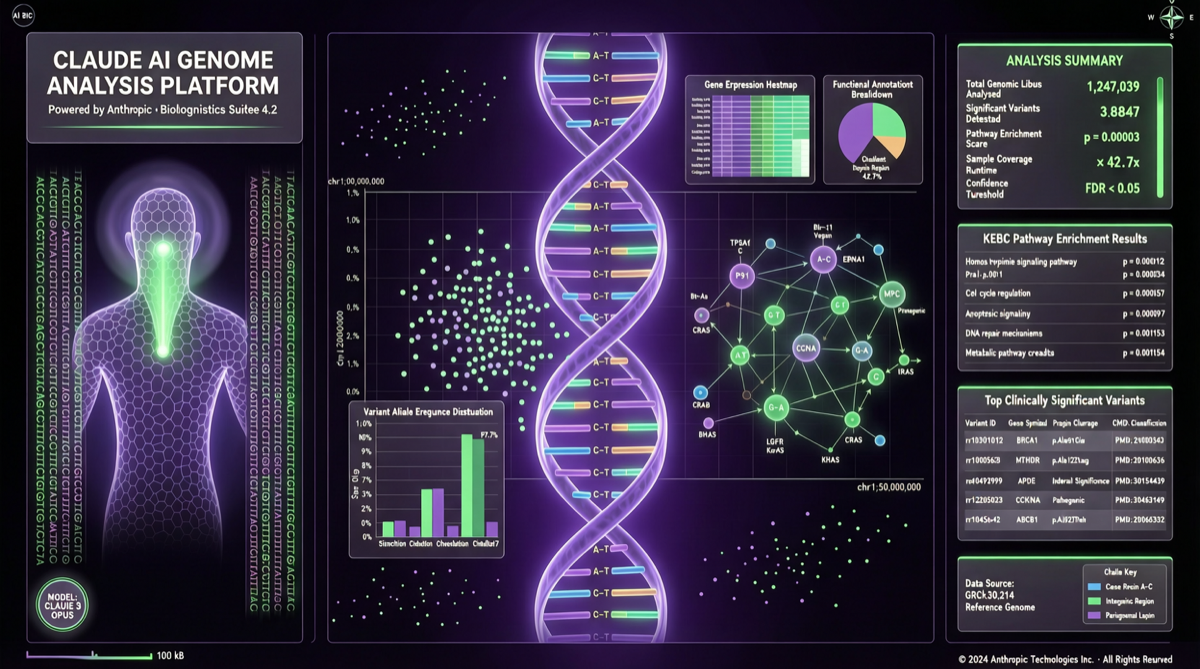
Anthropic 发布 BioMysteryBench 基准测试,用 99 个真实生物数据问题评估 Claude 的分析能力。其中 23 个问题连人类专家都束手无策,Claude 最新模型解决了约 30%。本文评测这一结果的意义与局限。
IBM 发布 Granite 4.1 系列(30B/8B/3B),Apache 2.0 许可,在 Artificial Analysis 智能指数上分别取得 15/12/9 分。本文评测该系列的 token 效率、编码能力和商用适用性。

GPT-5.5 Pro 在 ECI(Epoch Capabilities Index)综合指标中达到 159 分,创下该指标历史新高。本文从多维度拆解这一成绩的实际含义,对比 GPT-5.4 与 Claude Opus 4.7,给出选型建议。

Anthropic邀请Claude.ai用户分享AI使用体验,近8.1万人参与,成为迄今最大规模的多语言定性研究。调查结果揭示了用户对AI的核心期待、使用习惯和担忧,为产品选型和发展方向提供了数据支撑。
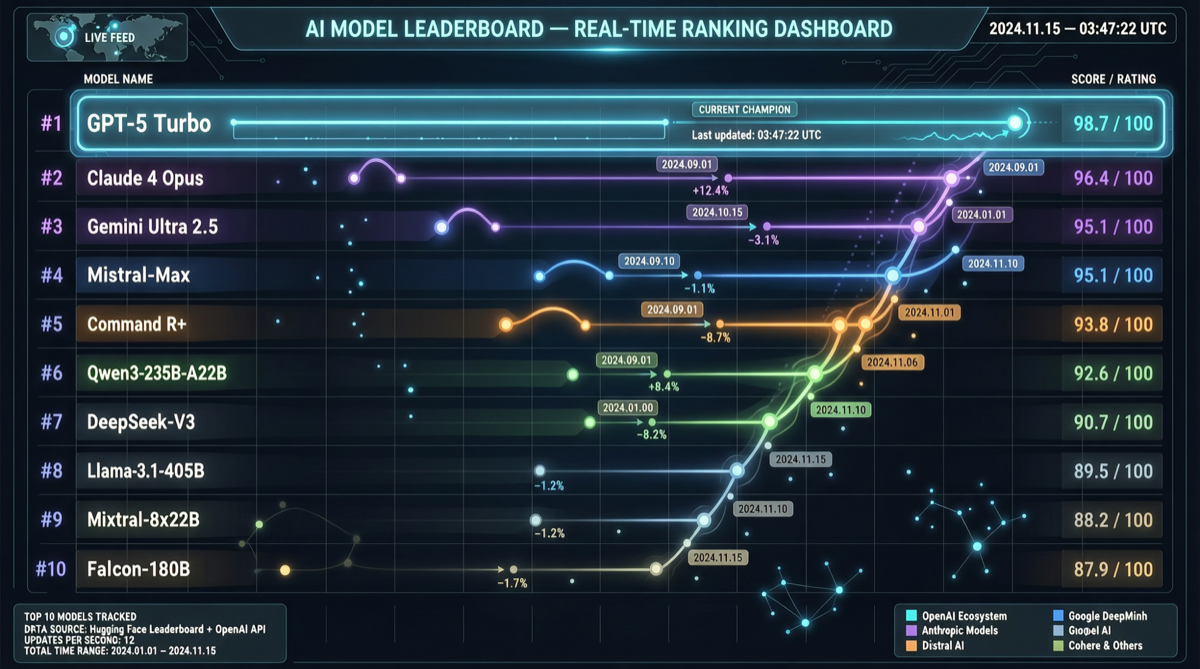
4月20日有人宣称Claude是最佳AI,5天后GPT-5.5发布,排行榜全面洗牌。2026年Q1已有4个前沿模型发布,模型间的优势差距正在缩小,"最佳"不再是稳定标签而是流动状态。
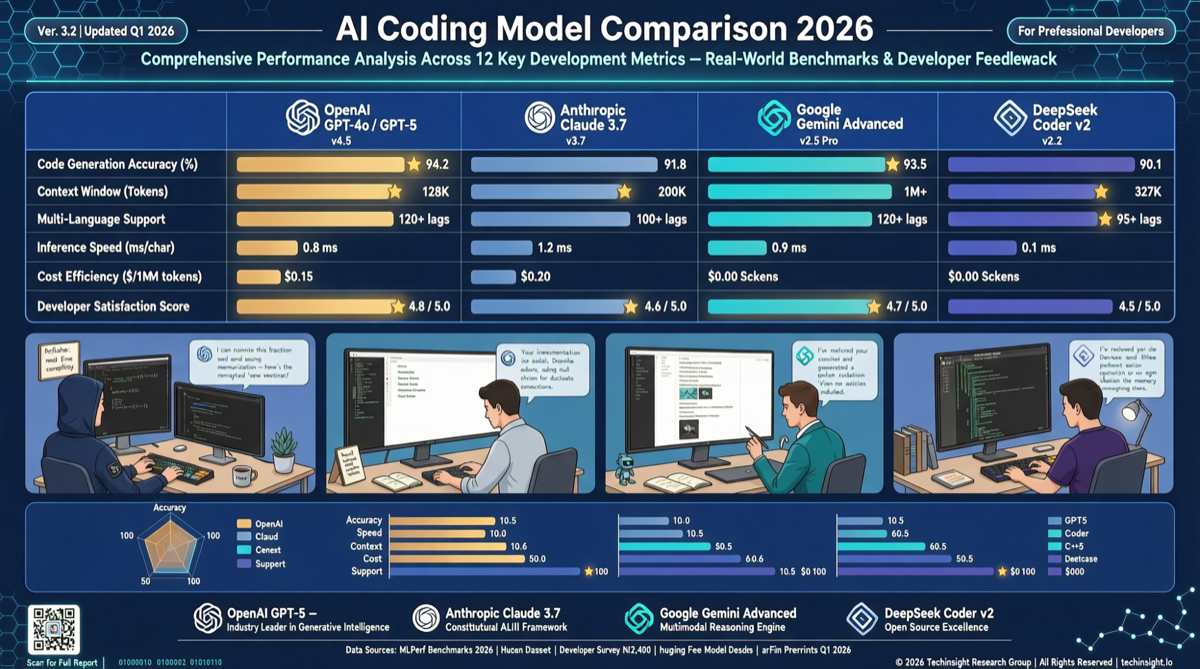
84%的开发者正在使用或计划使用AI编程工具。本文基于SWE-bench Pro、Aider排行榜和社区实测数据,对比GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro和DeepSeek V4在编程场景中的实际表现。
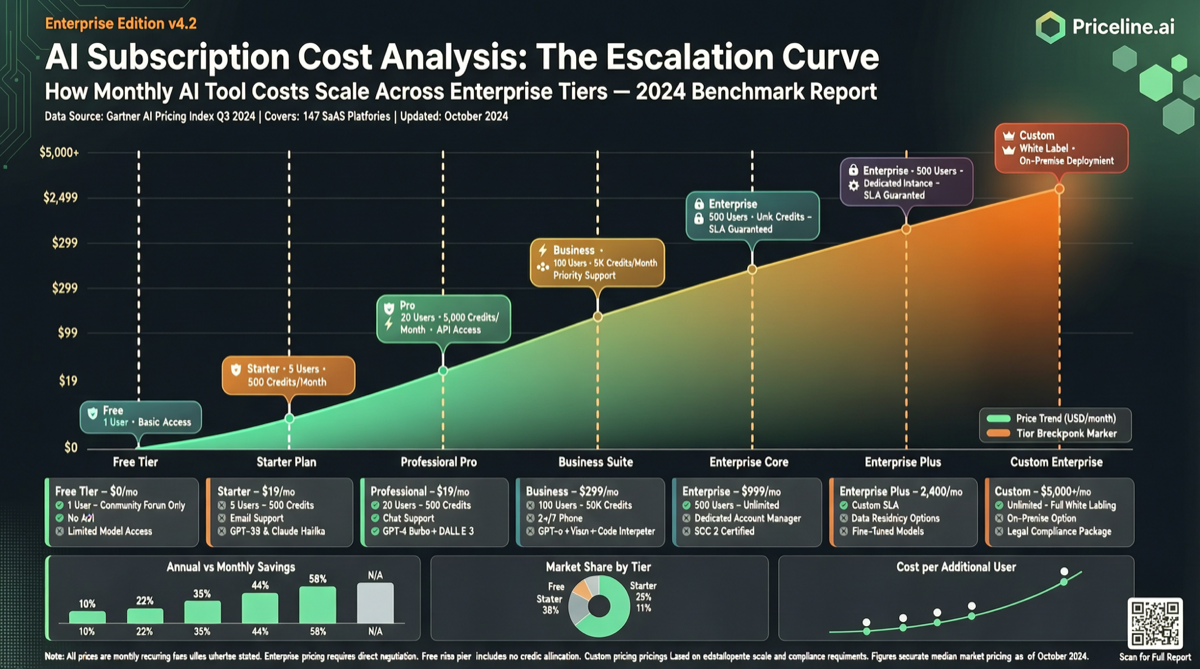
主流AI订阅服务价格跨度从$20到$200以上,模型能力也在快速分化。本文从代码生成、长文本分析、多模态和API配额四个维度评估不同价位订阅的实际使用价值,帮助不同用户群体做出最优选择。

GPT-5.5于4月23日发布,在Terminal-Bench、GDPval等基准上超越Claude Opus 4.7,但后者在SWE-bench Pro编程任务上仍保持优势。本文从五个维度对比两款旗舰模型的实际表现与适用场景。

GENERAL365 基准于 4 月 27 日发布,包含 365 道人工策划的推理难题,覆盖复杂约束、嵌套逻辑和语义干扰。当前最强模型得分不到 10%,暴露了大模型通用推理能力的真实短板。

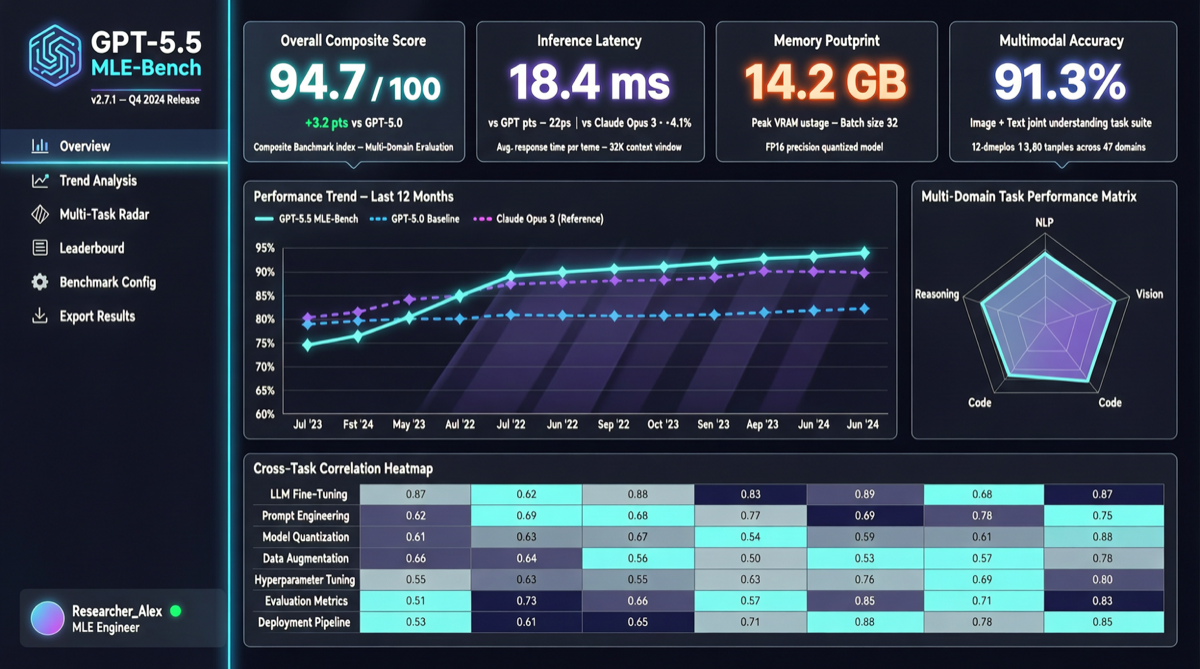
GPT-5.5 在 MLE-Bench 上得分 36%,较 GPT-5.4 的 23% 提升 13 个百分点。这一基准测试 AI 系统完成真实机器学习工程任务的能力,是衡量 AI 替代数据科学家工作进度的关键指标。
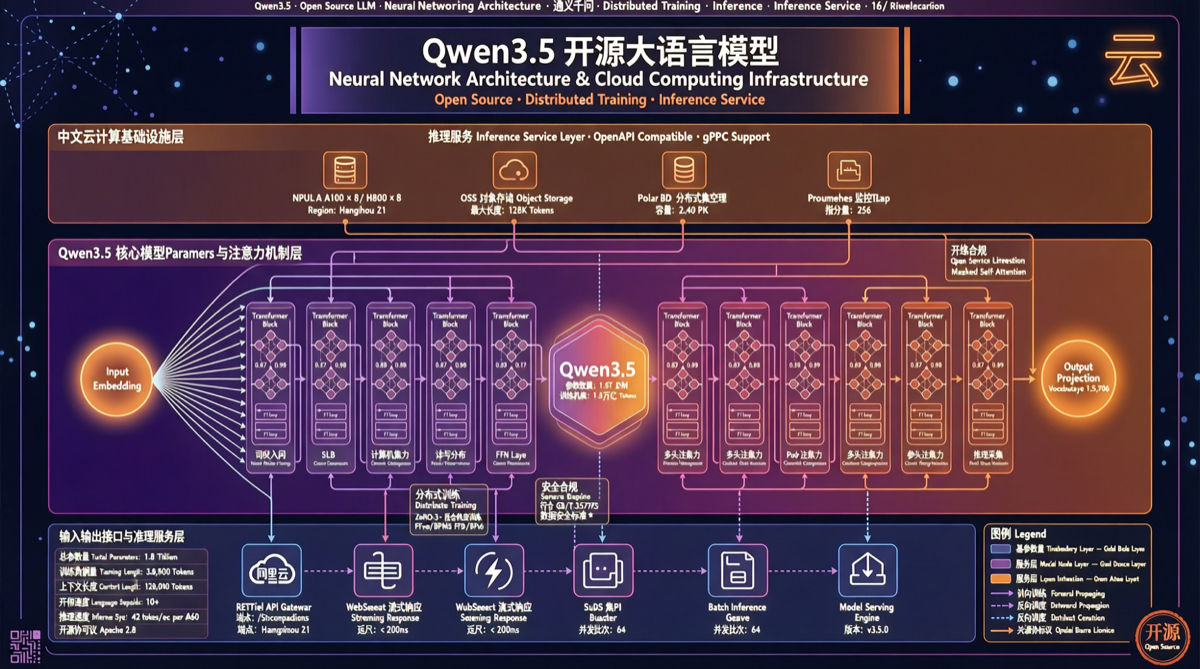
阿里 Qwen 3.5 系列覆盖从 0.8B 到 397B 的全尺寸矩阵,稀疏 MoE 架构让中等参数模型超越上一代大模型,原生多模态和 256K 上下文使其成为开发者的开源首选方案。
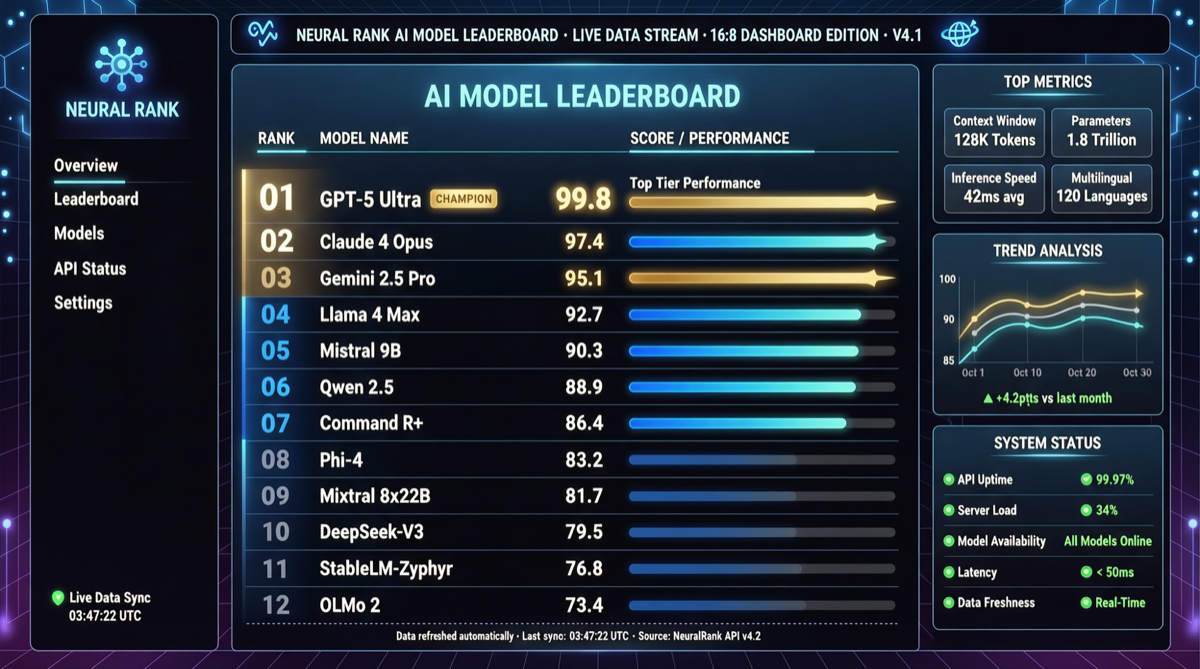
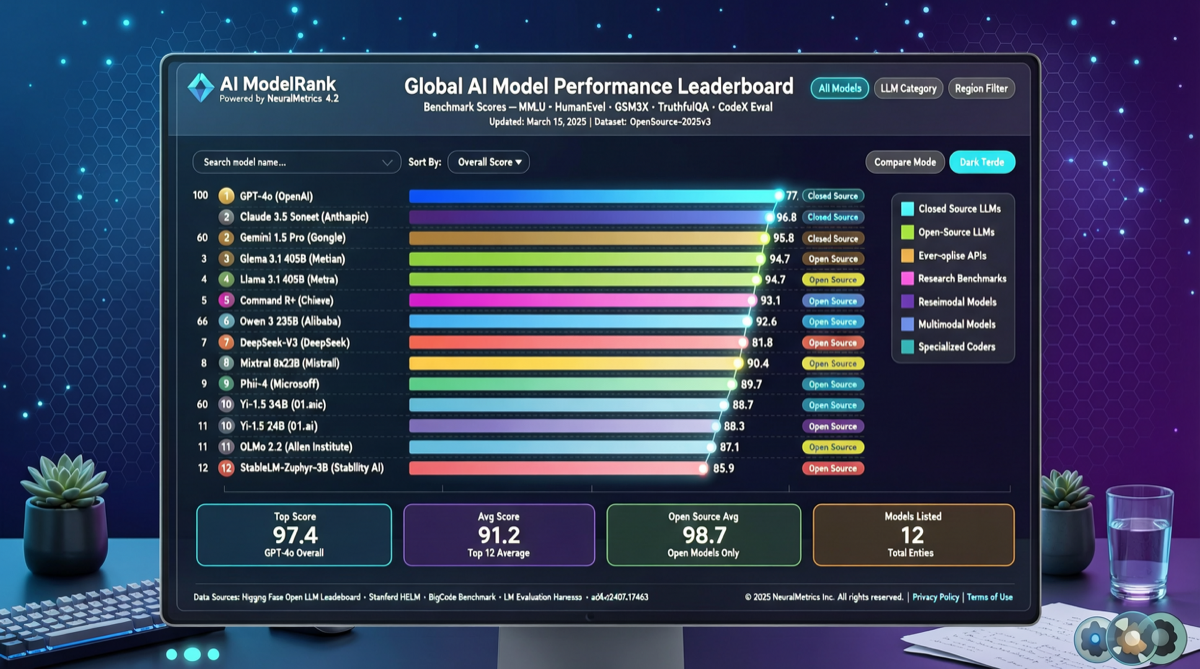
LMArena Elo 排名 Anthropic Opus 4.7 以 1503 分领跑,AA 综合指数 GPT-5.5 系列包揽前两名,Meta Muse Spark 首次进入前十。两份榜单给出不同的胜负手。
OpenAI GPT-5.5 与 Anthropic Claude Opus 4.7 同期发布,SWE-bench Pro Claude 领先 5.7%,GPT-5.5 在 MRCR 百万级上下文任务中大幅领先,选择取决于你的核心场景。

传统基准测试正在失去对 AI Agent 能力的解释力。2026 年新涌现的 Terminal-Bench、AgenticSwarmBench 等评测框架,正在定义下一代 Agent 能力评估标准。

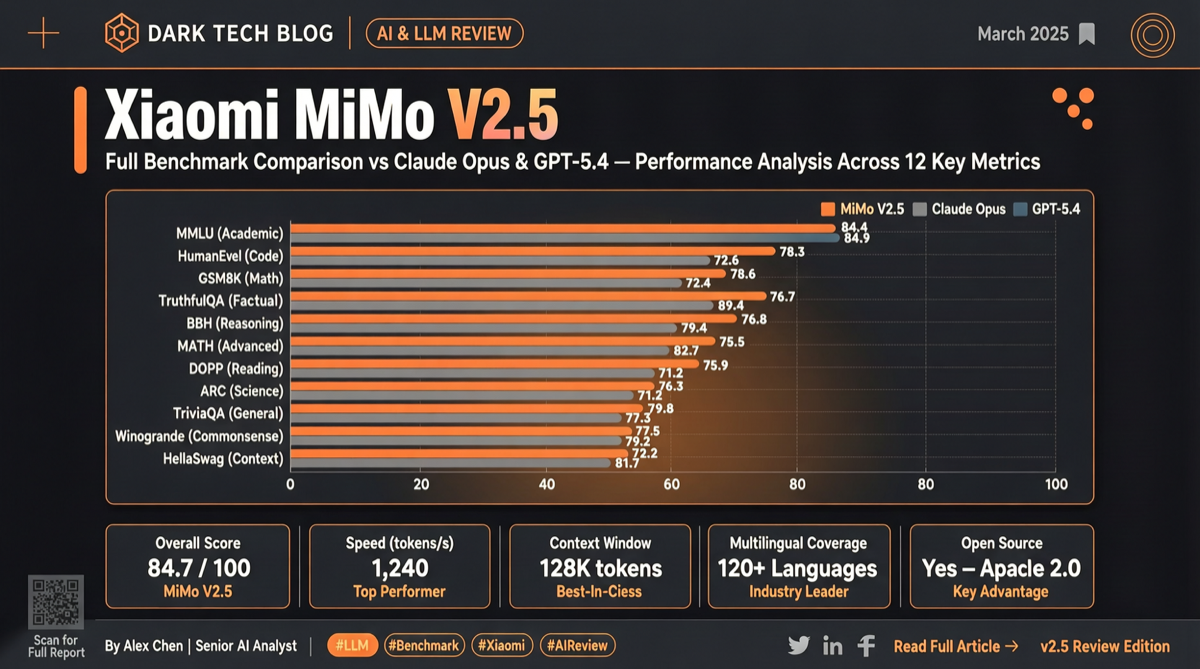
小米 MiMo-V2.5-Pro 在 Chatbot Arena 文字榜跻身全球前六、开源第一,Agent 专项指数开源第一,支持百万级长文本,并已适配几乎所有国产推理芯片。

阿里千问 Qwen3.6 系列开源,包含 27B 稠密模型和 35B-A3B MoE 模型。实测显示代码能力接近 Claude 4.5 Opus,长上下文支持百万 token,为开源社区提供了高性价比选择。
综合 SWE-bench Pro、HLE、MRCR 和 Arena 数据,Claude Opus 4.7 在代码和推理上领先,GPT-5.5 在长上下文和终端工作流上占优,Gemini 3.1 Pro 性价比突出。

2026年4月 Chatbot Arena 榜单显示,Anthropic 四款模型占据文字榜前四,但 Meta muse-spark 和小米 MiMo-V2.5-Pro 等开源模型正在缩小差距,开源第一已跻身全球前六。
MuleRun 由 Future AGI 开发,是一个完整的 AI Agent 平台。它不只是 SDK 或社区版,而是包含 UI、后端、仿真引擎、评估、优化循环和可观测性的全栈开源方案。支持 Agent 自主改进、Creator Studio 商业化部署和 Vibe Training 等创新特性。

灰度测试期间对阿里 HappyHorse 1.0 进行了多维度测试,涵盖对话表演、动作场景、世界知识理解及复杂提示词解析。模型在人物特写方面表现突出,但大场景构图仍有优化空间。

百万 token 上下文窗口已成为旗舰模型标配,但实际可用性差异巨大。GPT-5.5 在 1M 检索中达到 74%,而 Claude Opus 4.7 仅 32.2%。本文评测各模型长上下文的真实水平。
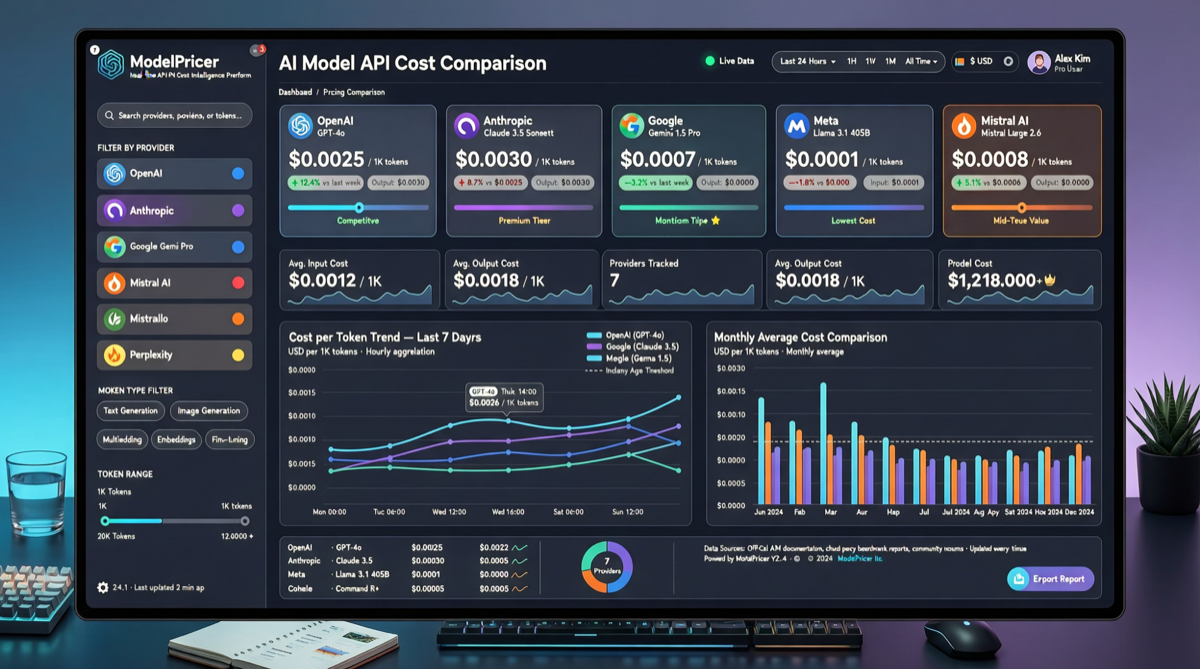
GPT-5.5 标价最贵但 token 效率最高,Gemini 2.5 Pro 标价最低但完成同样任务可能需要更多 token。本文基于 Artificial Analysis 实测数据,还原各模型的真实任务成本。
阿里巴巴 Qwen 3.6-27B 以 270 亿稠密参数在 Terminal-Bench 上追平 Claude 4.5 Opus,18GB 内存即可运行。本文评测这个"小身材大能量"模型的真实表现。

DeepSeek V4 以 1.6 万亿参数、100 万 token 上下文和 Apache 2.0 开源协议发布,首个几乎完全基于华为昇腾芯片训练的前沿模型。本文评估其实际能力与旗舰的差距。

OpenAI GPT-5.5、Anthropic Claude Opus 4.7和Google Gemini 2.5 Pro三款旗舰模型集中亮相。本文从编码能力、推理、长上下文和实际成本四个维度对比,给出场景化选择建议。

实测小米 MiMo-V2.5 系列:4 小时不间断生成 54 个应用的 macOS 复刻版,672 次工具调用写满编译器,模糊指令从一句大白话还原山野风格手账。Agent 能力追平 Claude Opus 4.6,Token 消耗省 40%-60%。
全面评测当前主流大语言模型在推理、编程、创作、多模态等维度的表现,帮助你选择最适合的模型。
