What Happened
DeepSeek released two visual capability updates in rapid succession at the end of April 2026, marking a differentiated approach for Chinese models in multimodal reasoning.
First: DeepSeek Vision Beta goes live. On April 30, DeepSeek introduced a native image understanding mode directly within its official chat interface. Users can now send images directly in the conversation and receive analysis without switching tools or calling third-party APIs.
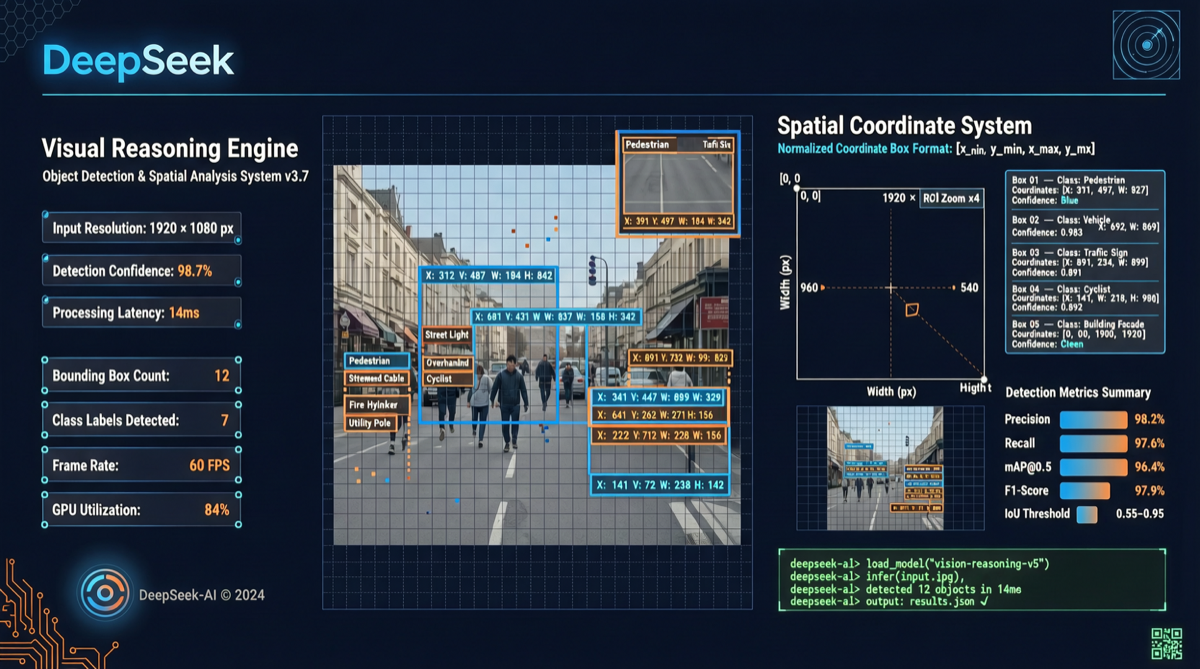
Second: “Thinking with Visual Primitives” technical report. The DeepSeek-V4-Flash team published a compelling paper proposing an entirely new multimodal reasoning paradigm — the model no longer “translates” images into text descriptions before reasoning, but operates directly in visual space.
Technical Breakthrough: Dual-Track Thinking Mechanism
Traditional multimodal models follow this workflow: image → encode as tokens → chain-of-thought reasoning in language → output text answer. DeepSeek argues this path has a fundamental flaw — by the time the model needs to “describe” spatial relationships in language, information loss has already occurred.
The core innovation of DeepSeek-V4-Flash is dual-track thinking:
| Dimension | Traditional CoT | DeepSeek Visual Primitives |
|---|---|---|
| Reasoning medium | Pure language tokens | Language + spatial coordinates |
| Visual anchors | Text descriptions of positions | Direct bounding box / point outputs |
| Spatial relations | ”Object A is to the left of object B” | Precise bounding box coordinates |
| Reasoning process | Linear chain | Parallel interleaving |
Examples in the report show the model simultaneously outputting text reasoning and precise visual annotations when analyzing complex charts — not thinking first then speaking, but “pointing while thinking.”
Landscape Assessment
This approach stands in sharp contrast to current mainstream multimodal models:
- GPT-4o / Claude: Language-centric visual understanding, images encoded and merged into text reasoning chains
- Gemini: Native multimodal but reasoning still dominated by token sequences
- DeepSeek-V4-Flash: First to elevate spatial operations (pointing, boxing) as first-class citizens in the reasoning process
For practical applications, this means DeepSeek’s new paradigm could deliver significant accuracy improvements in scenarios requiring precise localization and spatial reasoning (medical imaging analysis, industrial quality inspection, UI automated testing).
How to Use It
| Scenario | Traditional Approach | DeepSeek Visual Primitives |
|---|---|---|
| Document information extraction | OCR → text parsing → positioning | Direct bounding box on key fields |
| Industrial defect detection | Bounding box trained classifier | Model directly outputs defect coordinates |
| Chart analysis | Text description of data trends | Points to specific data points and explains |
| Code UI debugging | Screenshot + text description of bug | Directly annotates problematic UI regions |
Action recommendation: If you are building vision-related AI applications, watch whether DeepSeek-V4-Flash’s visual primitive capabilities are available via API. For scenarios requiring precise localization, this could be a significantly more cost-effective choice than pure language reasoning. Meanwhile, DeepSeek Vision Beta is already available for free trial in the official chat interface.