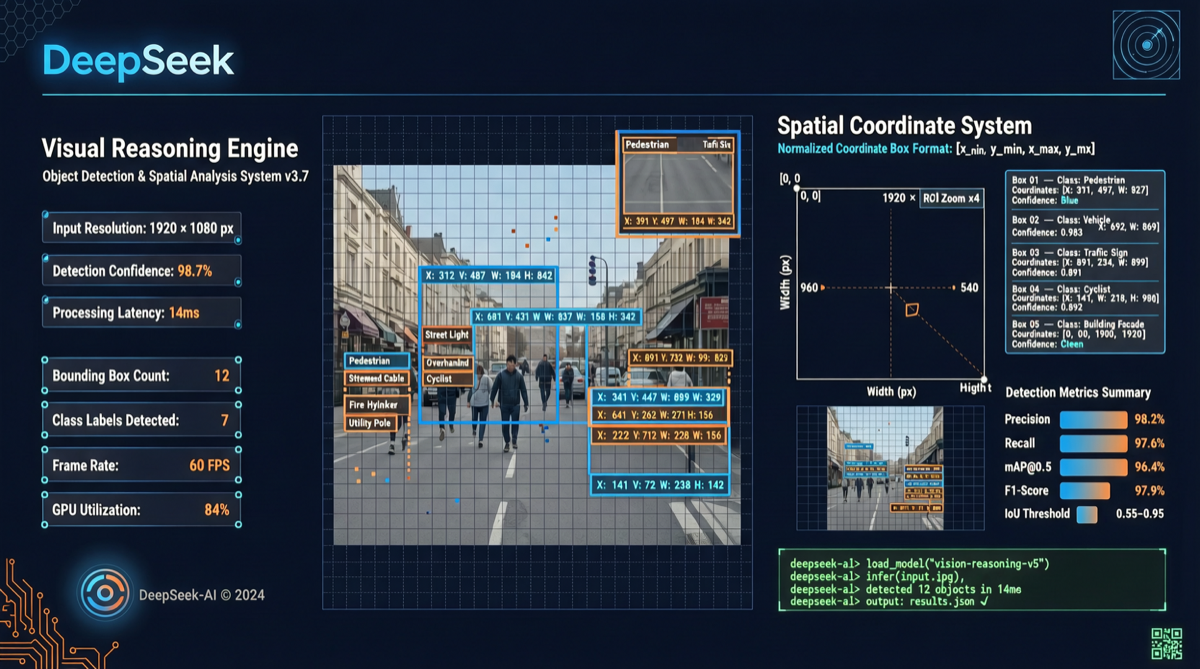
Что произошло
DeepSeek выпустил два обновления визуальных возможностей в конце апреля 2026 года, демонстрируя дифференцированный подход китайских моделей в области мультимодального рассуждения.
Первое: запуск DeepSeek Vision Beta. 30 апреля DeepSeek представил нативный режим понимания изображений непосредственно в официальном интерфейсе чата. Пользователи могут отправлять изображения прямо в диалоге и получать анализ без переключения инструментов или вызова сторонних API.
Второе: технический отчёт «Думая визуальными примитивами». Команда DeepSeek-V4-Flash опубликовала привлекательную статью, предлагающую совершенно новую парадигму мультимодального рассуждения — модель больше не «переводит» изображения в текстовые описания перед рассуждением, а оперирует непосредственно в визуальном пространстве.
Технический прорыв: механизм двухканального мышления
Традиционные мультимодальные модели следуют рабочему процессу: изображение → кодирование в токены → цепочечное рассуждение на языке (CoT) → вывод текстового ответа. DeepSeek утверждает, что этот путь имеет фундаментальный недостаток — к моменту, когда модель должна «описать» пространственные отношения на языке, потеря информации уже произошла.
Ключевая инновация DeepSeek-V4-Flash — двухканальное мышление:
| Измерение | Традиционный CoT | Визуальные примитивы DeepSeek |
|---|---|---|
| Среда рассуждения | Чисто языковые токены | Язык + пространственные координаты |
| Визуальные якоря | Текстовое описание позиции | Прямой вывод bounding box / точек |
| Пространственные отношения | «Объект A слева от объекта B» | Точные координаты bounding box |
| Процесс рассуждения | Линейная цепочка | Параллельное переплетение |
Примеры в отчёте показывают, что при анализе сложных диаграмм модель одновременно выводит текстовое рассуждение и точные визуальные аннотации — не сначала думает, потом говорит, а «указывает и думает одновременно».
Оценка ландшафта
Этот подход резко контрастирует с текущими основными мультимодальными моделями:
- GPT-4o / Claude: Языкоцентричное визуальное понимание, изображения кодируются и встраиваются в текстовые цепочки рассуждений
- Gemini: Нативная мультимодальность, но рассуждение по-прежнему доминируется последовательностями токенов
- DeepSeek-V4-Flash: Впервые пространственные операции (указание, выделение рамкой) становятся полноправными участниками процесса рассуждения
Для практических применений это означает, что новая парадигма DeepSeek может обеспечить значительное повышение точности в сценариях, требующих точной локализации и пространственного рассуждения (анализ медицинских изображений, промышленная инспекция качества, автоматизированное тестирование интерфейсов).
Как использовать
| Сценарий | Традиционный подход | Визуальные примитивы DeepSeek |
|---|---|---|
| Извлечение информации из документов | OCR → текстовый парсинг → позиционирование | Прямое выделение рамкой ключевых полей |
| Промышленное обнаружение дефектов | Классификатор с обучением bounding box | Модель напрямую выводит координаты дефектов |
| Анализ диаграмм | Текстовое описание тенденций данных | Указывает на конкретные точки данных и объясняет |
| Отладка UI кода | Скриншот + текстовое описание бага | Прямая аннотация проблемных областей UI |
Рекомендация к действию: Если вы создаёте приложения ИИ, связанные с компьютерным зрением, следите за тем, станут ли визуальные примитивы DeepSeek-V4-Flash доступны через API. Для сценариев, требующих точной локализации, это может быть значительно более экономичным выбором, чем чистое языковое рассуждение. Тем временем DeepSeek Vision Beta уже доступен для бесплатного тестирования в официальном интерфейсе чата.