何が起きたか
DeepSeek は2026年4月末に2つの視覚機能アップデートを続けて発表し、マルチモーダル推論における中国モデルの差別化路線を示しました。
第一弾:DeepSeek Vision Beta リリース。4月30日、DeepSeek は公式チャット画面内にネイティブな画像理解モードを導入しました。ユーザーはツールを切り替えたりサードパーティAPIを呼び出したりすることなく、会話内で直接画像を送信して分析結果を得られます。
第二弾:「視覚プリミティブで考える(Thinking with Visual Primitives)」技術レポート。DeepSeek-V4-Flash チームは注目の論文を発表し、まったく新しいマルチモーダル推論パラダイムを提案しました。モデルが画像を「翻訳」してから推理するのではなく、視覚空間内で直接操作するものです。
技術的ブレイクスルー:二軌道思考メカニズム
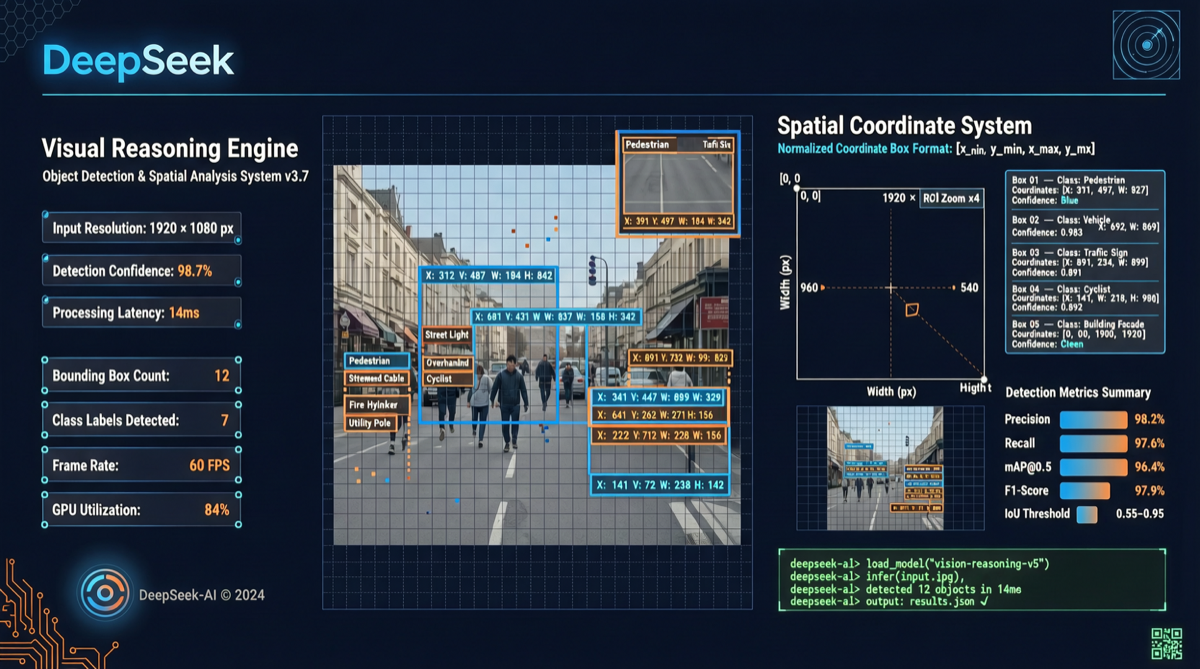
従来のマルチモーダルモデルのワークフローは、画像 → トークンにエンコード → 言語による連鎖推論(CoT)→ テキスト回答を出力、というものでした。DeepSeek はこのパスに根本的な欠陥があると指摘します。モデルが空間関係を「言語で記述」する必要がある時点で、情報の損失はすでに起きているのです。
DeepSeek-V4-Flash のコアイノベーションは二軌道思考です。
| 次元 | 従来の CoT | DeepSeek 視覚プリミティブ |
|---|---|---|
| 推論媒体 | 純粋な言語トークン | 言語+空間座標 |
| 視覚アンカー | 位置のテキスト記述 | 直接バウンディングボックス/ポイントマーカーを出力 |
| 空間関係 | 「オブジェクトAはBの左側」 | 正確なバウンディングボックス座標 |
| 推論プロセス | 線形連鎖 | 並列交差 |
レポートの例では、複雑なチャートを分析する際、モデルがテキスト推論と正確な視覚注釈を同時に出力していることが示されています。考えてから話すのではなく、「指しながら考える」のです。
市場ポジショニング
このアプローチは、現在の主流マルチモーダルモデルと鮮明な対比を成しています。
- GPT-4o / Claude: 言語中心の視覚理解、画像はエンコードされてテキスト推論チェーンに統合
- Gemini: ネイティブマルチモーダルだが推論は依然としてトークンシーケンスが中心
- DeepSeek-V4-Flash: 空間操作(指す、囲む)を推論プロセスの一等公民として初めて組み込み
実用的な応用において、これは正確な位置特定と空間推論を必要とするシナリオ(医療画像解析、工業品質検査、UI 自動化テスト)で、DeepSeek の新しいパラダイムが顕著な精度向上をもたらす可能性があることを意味します。
どう使うか
| シナリオ | 従来のアプローチ | DeepSeek 視覚プリミティブ |
|---|---|---|
| ドキュメント情報抽出 | OCR → テキスト解析 → 位置特定 | 主要フィールドを直接ボックスで囲む |
| 工業欠陥検出 | 境界ボックス分類器を訓練 | モデルが直接欠陥座標を出力 |
| チャート分析 | データトレンドのテキスト記述 | 特定のデータポイントを指して説明 |
| コードUIデバッグ | スクリーンショット+バグのテキスト記述 | 問題のあるUI領域を直接注釈 |
アクション推奨: 視覚関連のAIアプリケーションを構築している場合、DeepSeek-V4-Flash の視覚プリミティブ機能がAPIで利用可能かどうか注目してください。正確な位置特定を必要とするシナリオでは、純粋な言語推論方案より大幅にコスト効率の高い選択肢となる可能性があります。同時に、DeepSeek Vision Beta は公式チャット画面で無料で体験できます。