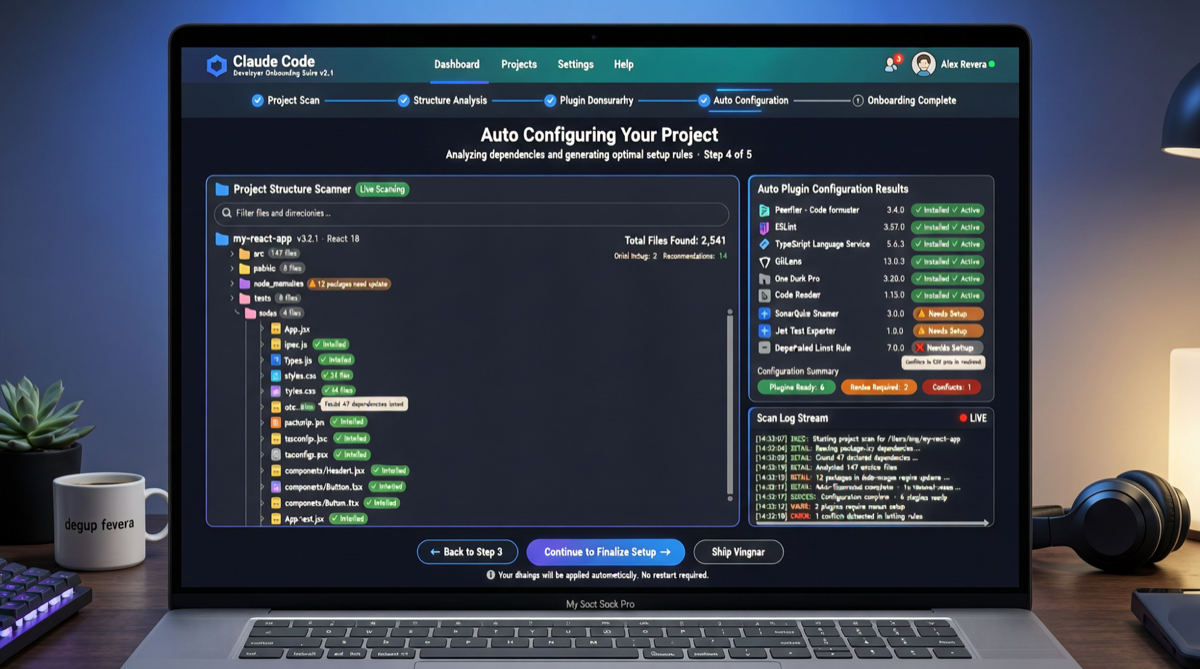
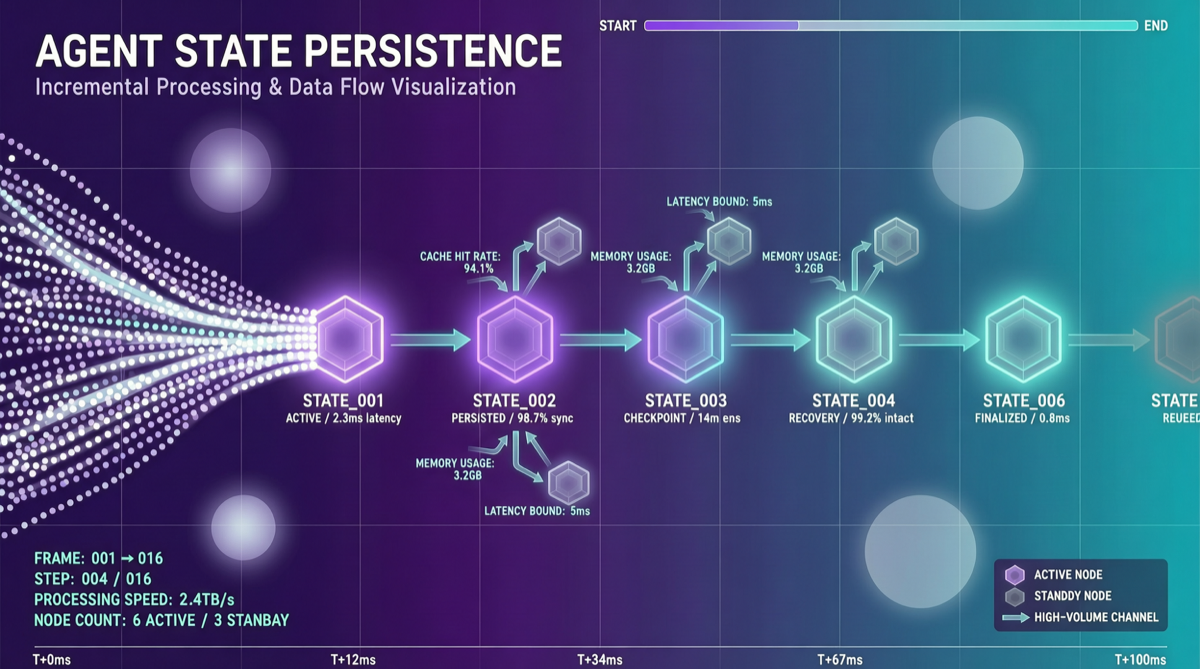
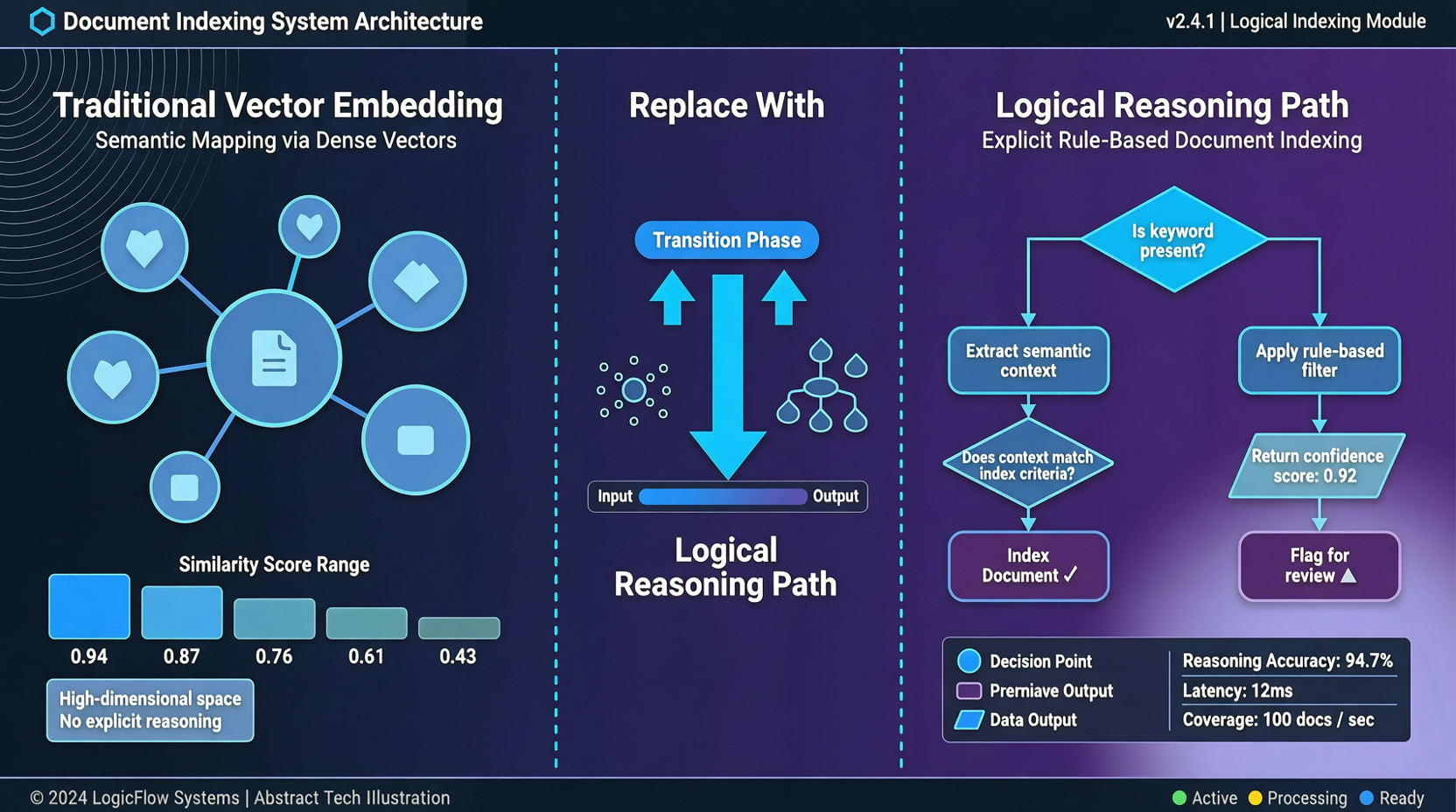
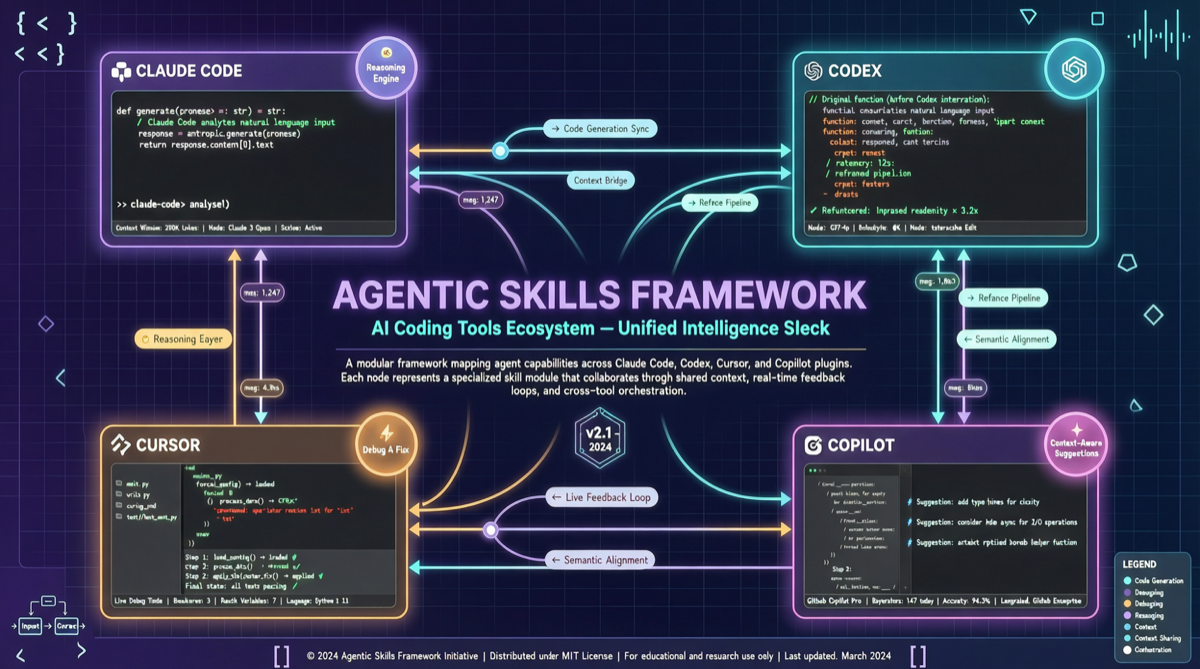
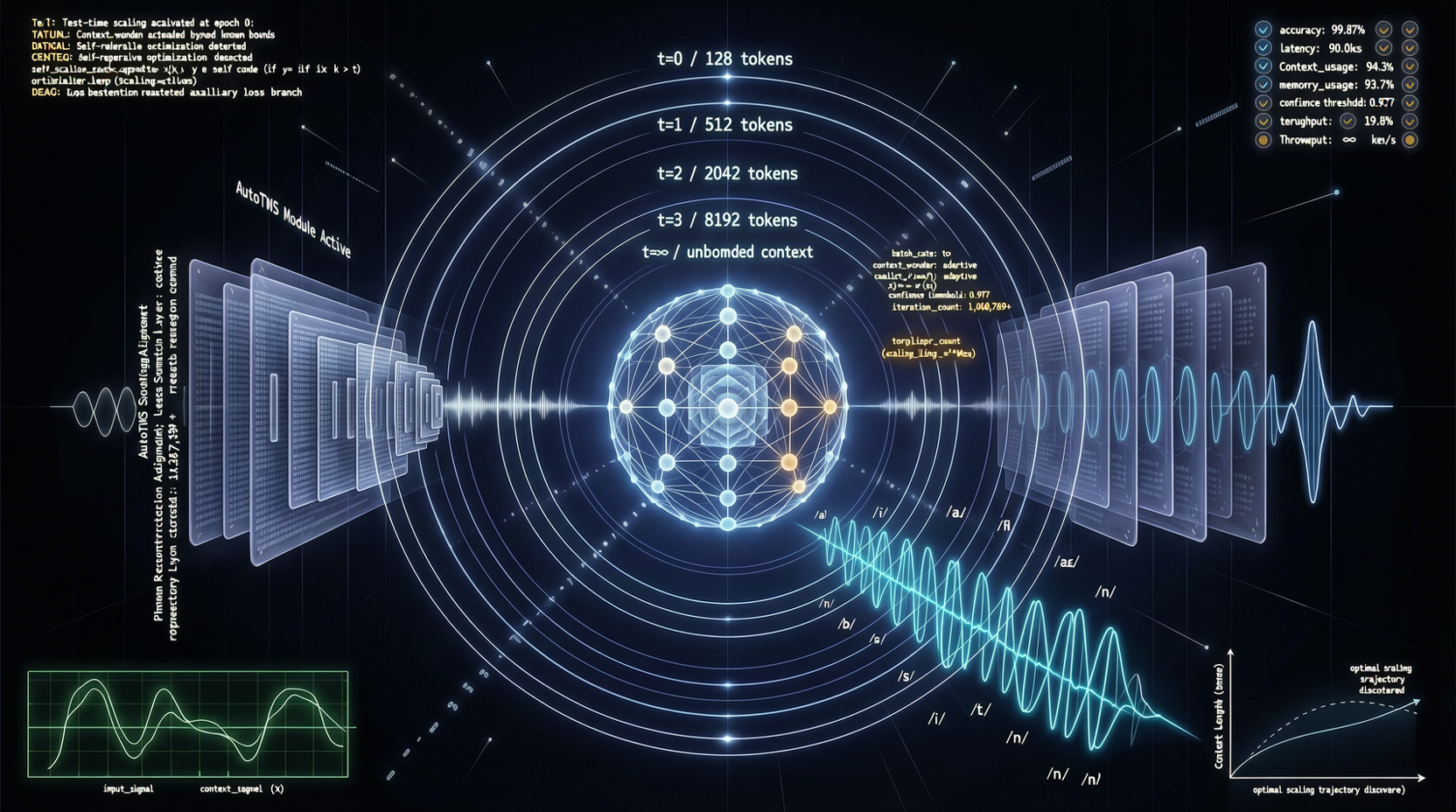
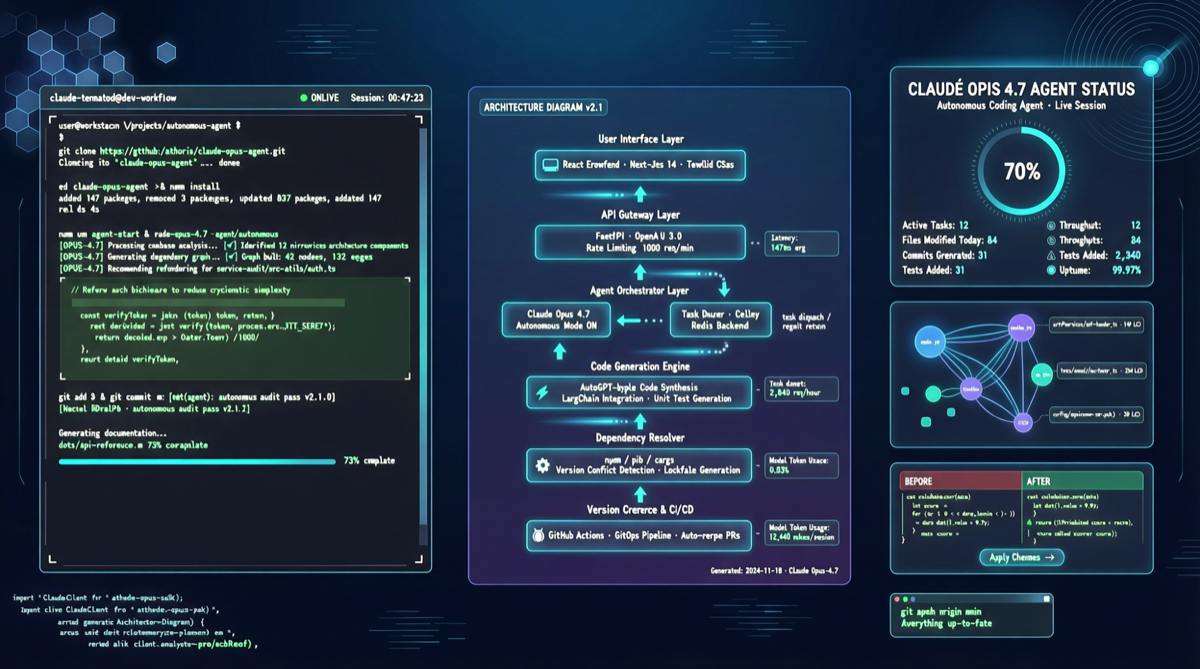
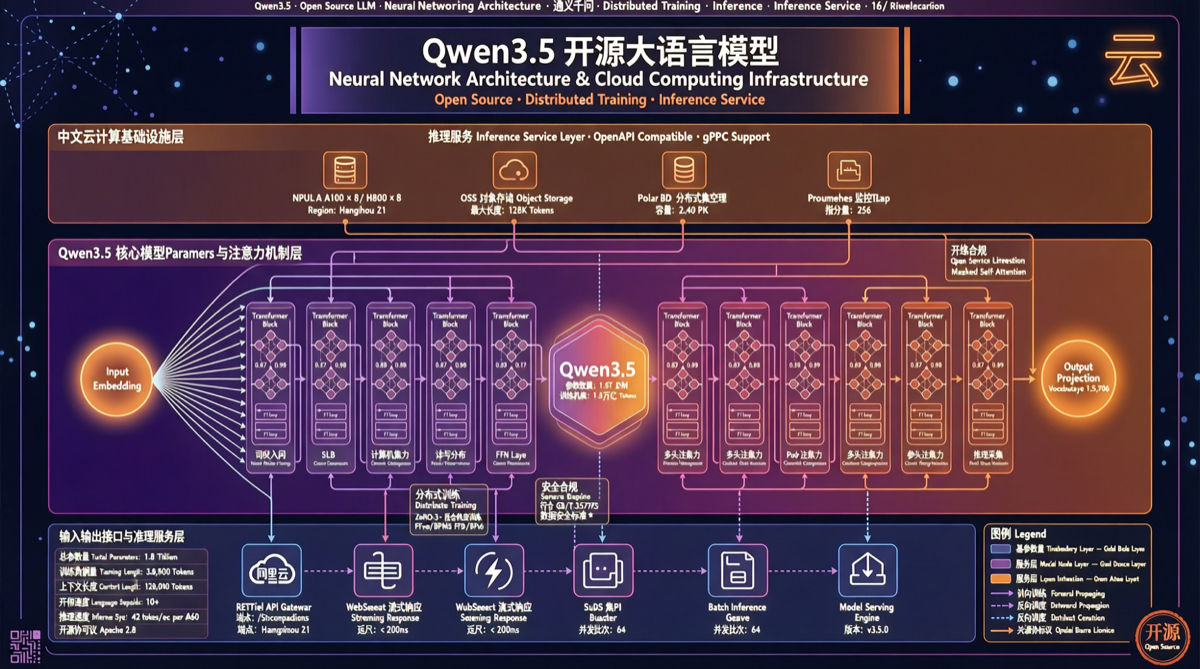
A2UI、MCP Apps、AG-UIの選び方:Agent UIでプロトコル名に惑わされないために
A2UIはコンポーネントの設計図寄り、MCP Appsはiframeベースのアプリ寄り、AG-UIはフロントエンドとバックエンド間の状態同期チャネル寄り。技術選定ではまず「UIとセキュリティ境界を誰が制御するか」を明確にする必要がある。
体験、ベンチマーク、限界
A2UIはコンポーネントの設計図寄り、MCP Appsはiframeベースのアプリ寄り、AG-UIはフロントエンドとバックエンド間の状態同期チャネル寄り。技術選定ではまず「UIとセキュリティ境界を誰が制御するか」を明確にする必要がある。
Basetenは110億〜130億ドルの企業価値で資金調達を進めていると報じられている。企業がオープンモデルの推論を自社管理すべきかどうかは、スループット、レイテンシ、ベンダーロックイン、運用保守能力によって判断すべきである。
Codex SitesとClaude Code Artifactsはどちらもコードエージェントの成果物を可視化するものですが、前者はデプロイに重点を置き、後者はチーム向けの解説とレビューに重点を置いています。
Fable 5とGPT-5.5はどちらも最先端のコーディング能力でしのぎを削っています。モデル選定の際は、ベンチマークスコアよりも、対応範囲、価格、ツールチェーン、セキュリティ戦略を優先して考慮します。
ローコードAI自動化ツールは既に階層化されている。安定したプロセスにはワークフロープラットフォームを、探索型のプロセスにはコードエージェントを選択すべきだ。評価基準は生成速度ではなくガバナンス(運用管理)に置くべきである。
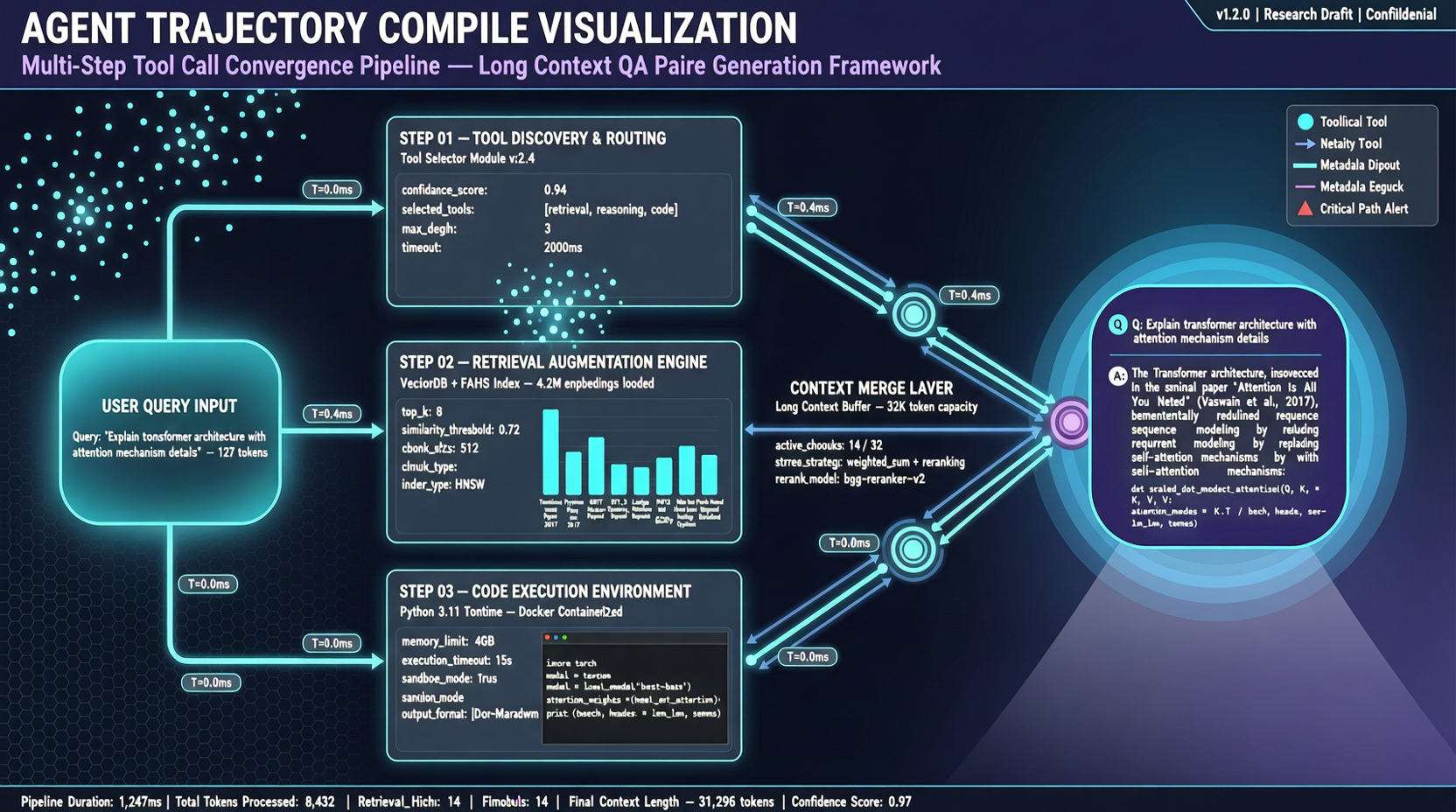
ACCは複数ターンのエージェンットツール呼び出し軌道を長文脈QA対にコンパイル、散在する証拠を統合することをモデルに教える。ACC訓練後のQwen3-30B-A3BはMRCRで+18.1、235B版に迫る。
RLVRのトークンレベル信用割り当てはブラックボックスだった。DelTAはポリシー勾配の更新方向を線形識別器として再解釈し、7つの数学ベンチマークで同規模ベースラインを2-3点上回る。
MM-OCEANは27のMLLMを人格知覚で評価、正解评分の51%が観察可能な証拠に基づかないことを発見、ホリスティックグラウンディング率は0-33.5%に留まる。正解 ≠ 理解。
GRPOはすべてのトークンに同じアドバンテージを割り当てる。OPPOはオラクル信号をベイズ信念更新に使い、閉形式でトークンレベルのアドバンテージを生成—バリューネットワーク不要、追加ロールアウト不要、前方传播1回のみ。
RTPurboはフルアテンションLLMが本質的にスパースであることを証明—数百ステップの訓練だけで高度なスパースモデルに変換、1Mコンテキストで9.36倍のprefill高速化、精度はほぼ無損失。
AgentMemoryはClaude Code、Cursor、Codexなどのプログラミングエージェントに永続メモリを提供。387コミット、15kスター、15+エージェントが1つのメモリサーバーを共有。ハイブリッド検索P@5は0.578に達し、grepベースラインの2倍以上。
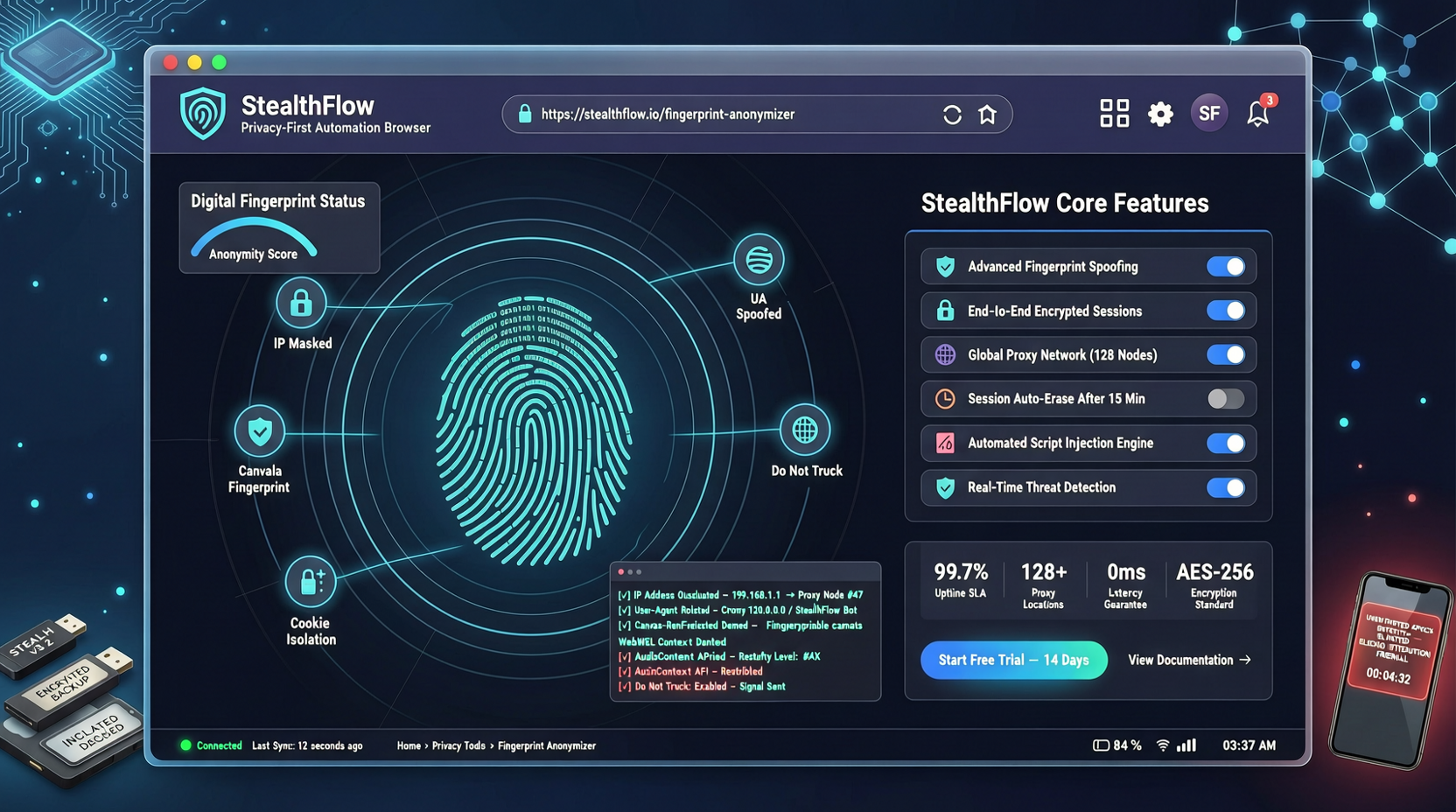
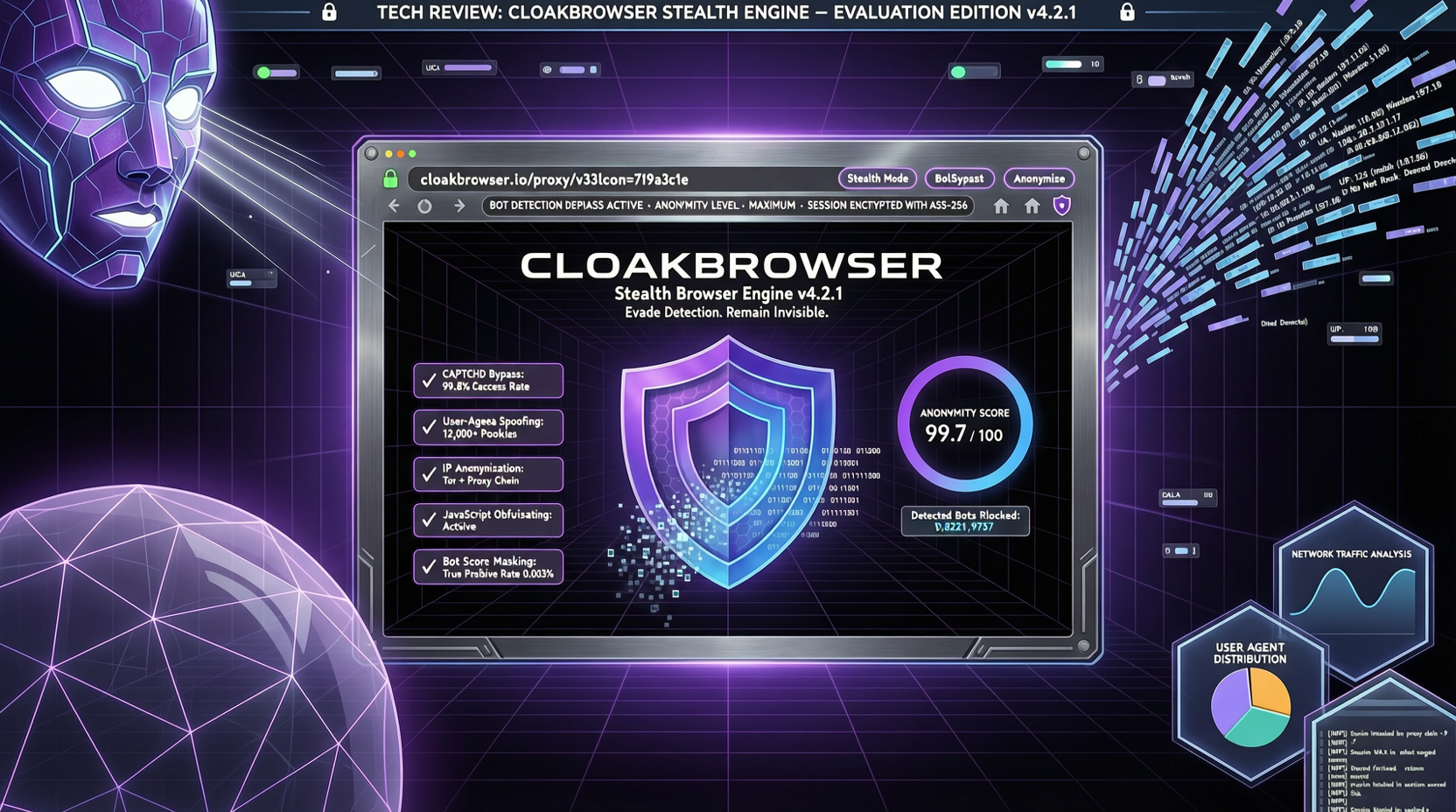
CloakBrowser は設定パッチではなく C++ ソースレベルで Chromium のフィンガープリントを変更。30/30 検出サイト通過、Playwright/Puppeteer の一行置換、pip install で利用可能。一週間で約 9,000 スター獲得。
oh-my-pi は Pi のスーパーチャージ版フォーク、5,700+ コミット、609 タグ。Hashline 編集で Grok 4 Fast の出力トークンを 61% 削減、LSP 完全統合、本格的デバッガ駆動、サブエージェント並列ワークツリー。
Rust製のパーソナルAIアシスタントOpenHumanが23.5kスター、週間で1.7万増加。KarpathyのObsidian Wikiパターンをデスクトップアプリ化、118+サービスから自動データ取得、TokenJuice圧縮で80%のトークン節約。
qiaomu は 15+ のコンテンツソース(ペイウォール回避含む)をサポートし、Google NotebookLM に自動アップロードしてポッドキャスト、PPT、マインドマップを生成。6 レベルのペイウォール回避チェーン内蔵。一週間で 2,347 スター獲得。
humanlayer/12-factor-agents は、スター数21,000件で一つの事実を示しています:開発者たちは、実際にプロダクション環境で使えるLLMソフトウェアの開発ガイドラインを真に必要としているのです。
ArthurBrussee/brush は、1166回のコミットで4.6Kスターを獲得した3D再構築ツールです。これは単なる技術披露ではなく、一般のユーザーが実際に3D再構築を実行できるようにするという明確なミッションを持ったプロジェクトです。
BenedictKing/ccx は、1092回のコミットと201個のリリース版によってその活発な開発状況を示しています。1週間で595スターも増加したのは、単なる偶然ではありません。
Meta が Rust で Python 型チェッカー Pyrefly を再構築。13,000 回以上のコミット、6.3K stars。mypy や pyright を置き換えられるか?
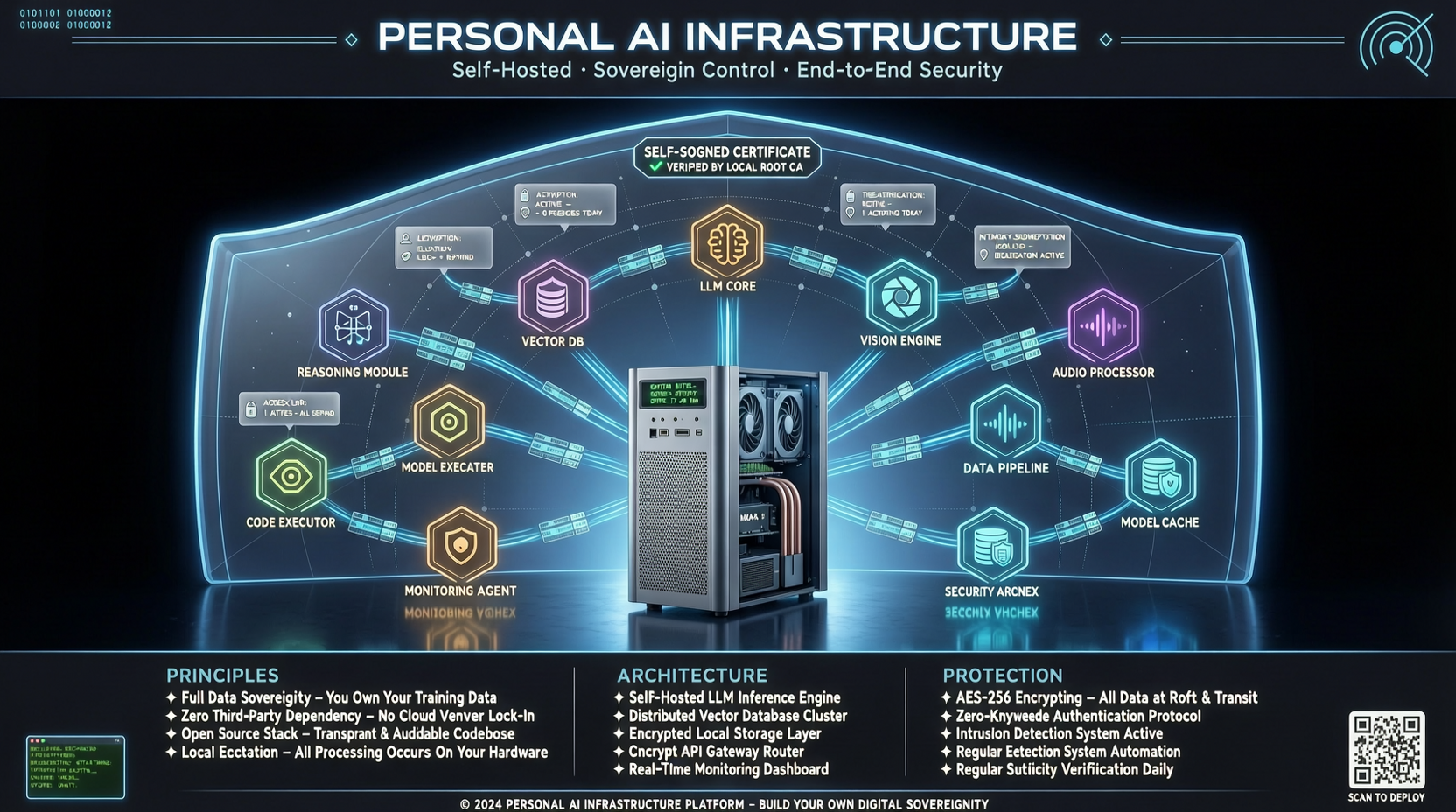
Daniel MiesslerのPersonal_AI_Infrastructureは、617回のコミットと14.2Kのスターにより、個人AIワークベンチが単なる概念ではなく、実際にデプロイ可能な実体であることを証明している。
bambuddyは、Bambu Lab 3Dプリンター向けのオープンソースなセルフホスト管理プラットフォームです。単体のA1から40台規模のプリンターファームまで一元管理をサポート。公式クラウドサービスに依存せず完全にローカルで動作し、Spoolmanによるフィラメント管理やGコードプレビュー機能も統合されています。
PromaはClaude Agent SDKをベースとしたオープンソースのAgentプラットフォームで、飛書グループチャットでの呼び出しをネイティブにサポートし、任意の大規模言語モデルプロバイダーに柔軟に接続できる。「トップクラスのAgent能力を日常使う場所そのもので動かす」という実践方向性を体現している。
RuViewは通常のWiFi信号を用いて、カメラを一切使用せずにリアルタイムの空間認識、バイタルサインモニタリング、存在検知を実現しました。GitHubで55,000以上のスターを獲得し、"ポスト・カメラ時代"における空間認識技術について議論を巻き起こしています。
K-Dense AI がオープンソース化した scientific-agent-skills は、すぐに使えるエージェント用スキルパックであり、研究、エンジニアリング、分析、金融、執筆などの分野をカバーしています。21,500 以上のスターを獲得し、毎週 600 以上増加しており、Agent Skills エコシステムにおいて最も注目されている垂直分野向けソリューションの一つです。
韓国のオーディオテクノロジー企業Supertoneがオープンソース化したSupertonic――デバイス上で完全に動作する多言語TTSエンジン。中国語、日本語、韓国語、英語など9言語に対応し、ONNX Runtimeによるクロスプラットフォームデプロイを実現。クラウド依存なし、低遅延、完全オフライン。
清華大学MLグループ(thu-ml)がCausal Forcing++を提案。自己回帰的拡散蒸留をリアルタイムインタラクティブ動画生成に適用。Hugging Face Daily Papersで72票、動画生成の品質と速度の核心的矛盾を解決。
CurveBench ベンチマークは LLM の精確なトポロジー推論における深刻な短所を明らかにした:最強モデル Gemini 3.1 Pro は簡単タスクでわずか 71.1%、困難タスクで 19.1% に急落。RLVR 微調整済みの Qwen3-VL-8B が GPT-5.4 と Claude Opus 4.5 を上回る。
ノートルダム大学が PreScam ベンチマークをリリース。17.8 万件の実際の詐欺報告書から 11,573 件のマルチターン会話詐欺インスタンスを抽出。リアルタイム終了予測において、教師ありエンコーダーがゼロショット LLM を大幅に上回る。
Self-Distilled Agentic Reinforcement Learningは、エージェントがRL訓練中に自己蒸留を行うことで、外部教師モデルに頼らずポリシー品質を向上させる。HF Daily Papersで58票、11名の著者。
Hugging Face の ASR Leaderboard に「Benchmaxxer Repellant」という不正防止機能が導入された。モデルがベンチマークに最適化し始めると、スコアはもはや実力を表さなくなる。
Aiderは純ターミナル路線を貫き、44.8Kスターがその道の有人を証明。GUI系プログラミングAgentとの比較で優勢と短板は?
ClineがVS Code拡張機能からSDK + IDE + CLIの三刀流へ進化。61.7Kスターの背後にあるのは野心か泡沫か。実測で告诉你。
Codegraph はプリインデックスされたコード知識グラフでセマンティック検索を代替し、Claude Code が大規模プロジェクトで token を節約、ツール呼び出しを削減。思路は正しいか?
antirez の DS4 が一週間で爆発的な人気に。DeepSeek V4 Flash と 2/8bit 量子化により、ローカルモデルが初めてクラウドの代替になり得ることが証明された。
Executor は AI Agent の「欠けた統合レイヤー」を目指し——Agent が任意の OpenAPI、MCP、GraphQL、カスタム JS 関数を安全に呼び出せるようにする。1.7K star、注目すべきか?
Artificial Analysis の知能指数で三大フラッグシップモデルの差が 3 ポイント以内に縮小。モデル競争は「誰がより強いか」から「誰がより実用的か」へと移行している。
Y CombinatorのCEOであるGarry Tanが、Claude Codeの完全な設定ファイル「gstack」をオープンソース化した。このプロジェクトには、CEO、デザイナー、エンジニアリングマネージャー、リリースマネージャー、ドキュメントエンジニア、QAとして機能する23の明確なポリシーを持つツールが含まれている。ローンチ直後に瞬く間に話題となり、スター数は96,900に達した。
Kiro.rs は Rust で書かれた Kiro クライアントで、API キー、IDC、ソーシャルログインの複数認証方式をサポートし、Admin UI を備える。1308 star、注目に値する小ツール。
NVIDIA-AI-Blueprints/aiq はエンタープライズ向け AI エージェントのリファレンスアーキテクチャであり、企業データソースへの接続、SOTA モデルによる推論、信頼性の高いビジネスインサイトの出力をサポートします。
NVIDIA-AI-Blueprints/pdf-to-podcastは、論文やドキュメントをアップロードするとGPUアクセラレーションにより自動で対話形式のポッドキャスト音声を生成するツールです。
NVIDIA-AI-Blueprints/video-search-and-summarization は NVIDIA 公式がオープンソース化した GPU アクセラレーション対応の動画分析ソリューションであり、動画コンテンツの検索、キーフレームの抽出、自動要約、および可視化をサポートします。
RelaxAI は英国の主権 LLM 推論が OpenAI/Claude より 80% 安価と主張。方向性は正しいが、「主権」という言葉は現時点では政治的ラベルに近く、技術的優位性はまだ見えていない。
roboflow/supervision はスター数38,955を達成した「再利用可能なコンピュータビジョンツール」のコレクションです。モデルの学習や推論の高速化は行わず、より基礎的な部分を担当します。CVモデルの出力結果を、実用的なデータ構造、可視化、そしてダウンストリームシステムが利用可能な形式に変換するのがその役割です。
ServiceNow チームが vLLM V0 から V1 への移行中に発見した課題:強化学習シナリオでは、連続バッチ処理の非同期最適化が正しさを犠牲にすると、すべての利益が無に帰する。
AgentMemoryはリアルワールドベンチマークに基づく #1 AI コーディングAgent永続メモリソリューション、週間で2,300+スター。MCP経由でClaude Code、Codex等にクロスセッションメモリを提供。実測:繰り返しプロジェクトで約30%のコンテキストトークン節約。
CloakBrowserは全ての主要アンチボット検知を突破するStealth Chromium、30/30テスト全合格。週間で5,400+スター、計7.5k。技術的には非常に強力だが、使用シーンのコンプライアンス境界は慎重に評価する必要がある。
Local Deep ResearchはSimpleQAで約95%、3090単体で動作。10以上の検索エンジンとローカルLLMをサポート、データは全てローカルで暗号化。現時点で最も信頼できるオープンソース深度研究ツール。
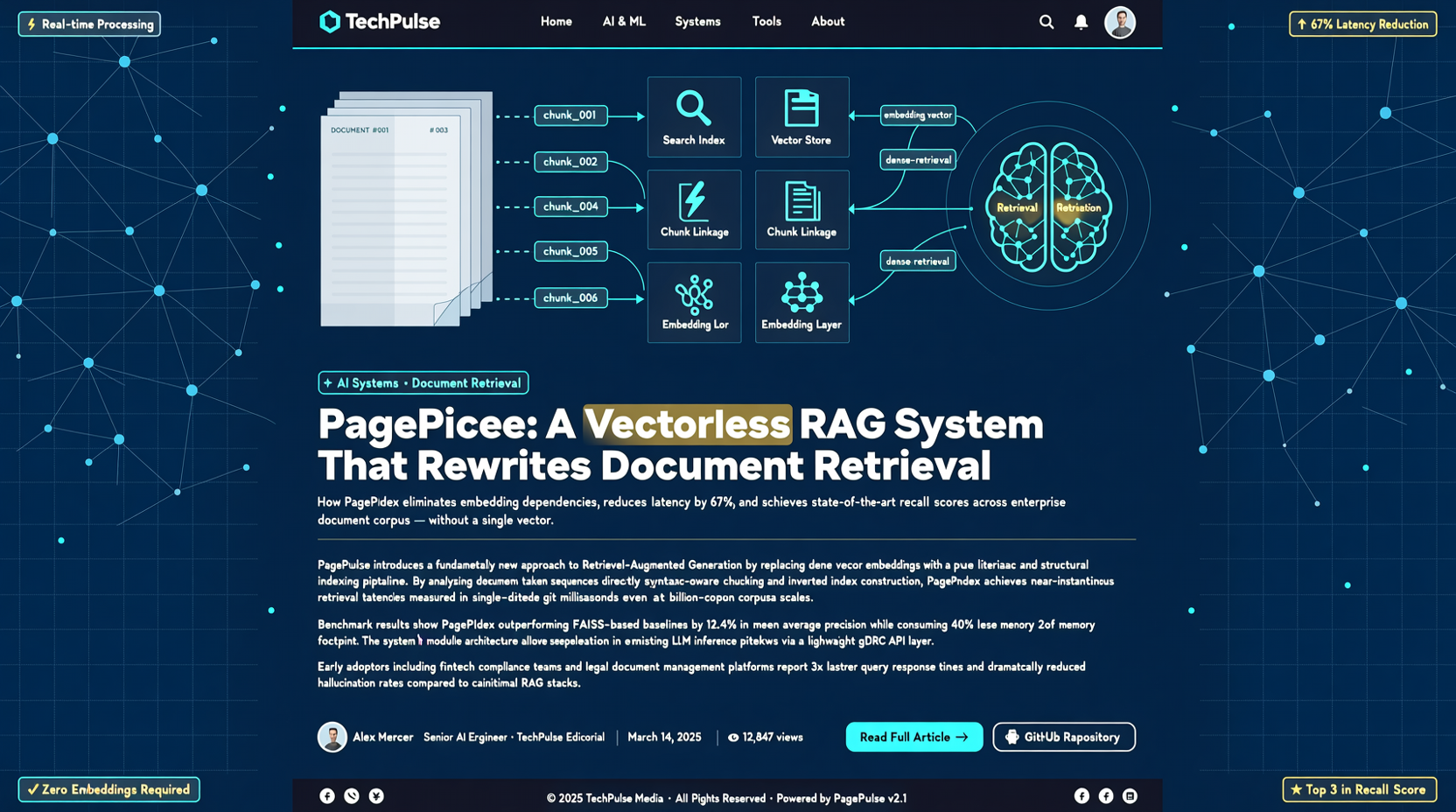
PageIndexはベクトル化なしの推論ベースRAGを提案し、週間で4,500以上のスターを獲得。embeddingとベクターDBを省略し、LLM推論でドキュメントセグメントを特定。実用的だが、レイテンシーが課題。
ByteDanceがオープンソース化したUI-TARS Desktop、今週33.5kスター。最先端AIモデルとAgentインフラを接続するマルチモーダルデスクトップAgent。コードとissueを確認した結論:方向性は正しいが、本番レベルまではまだ距離がある。
「AIでお金を稼ぐ」を合言葉に、AiToEarnが1週間でGitHubスター11,000を突破。しかし、これはツール集なのか、チュートリアルなのか、それとも不安を煽るパッケージ商品なのか?
CloakBrowserがGitHubで日均1,300星のペースで急成長、30/30の反検出テストに合格すると主張。この「見えないChromium」と呼ばれるツールは何が正しいのか?
「Private, Simple and extremely powerful」を合言葉に、tinyhumansai/openhumanがGitHubで高速イテレーション中。6分前までコードをコミット——このプロジェクトの開発ペースは目を引く。
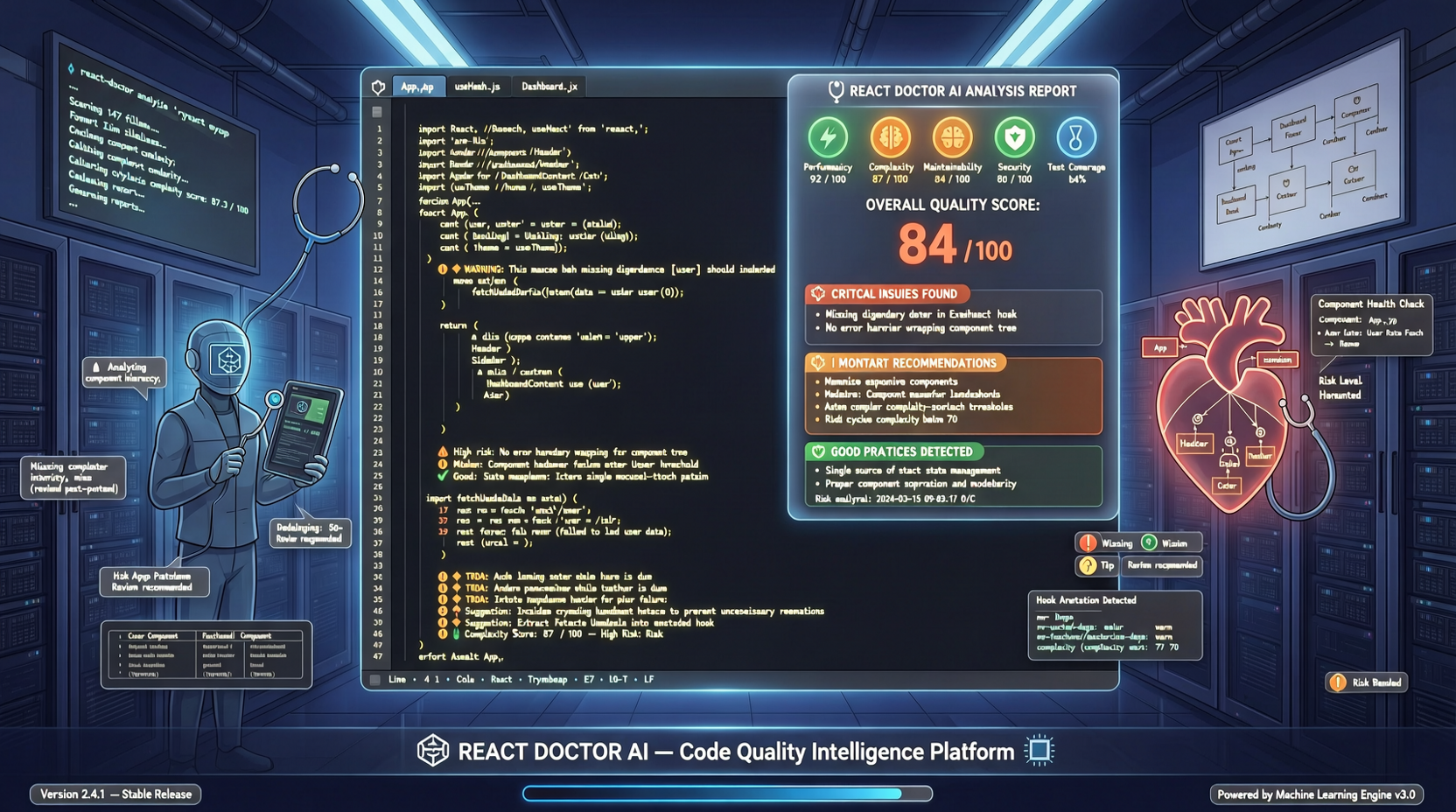
Million.jsチームが推出的したReact Doctorは、AI生成のReactコードの品質をチェックする専用ツール——面白い洞察から生まれた:AIが書くコードは速く動くが、速く劣化する。
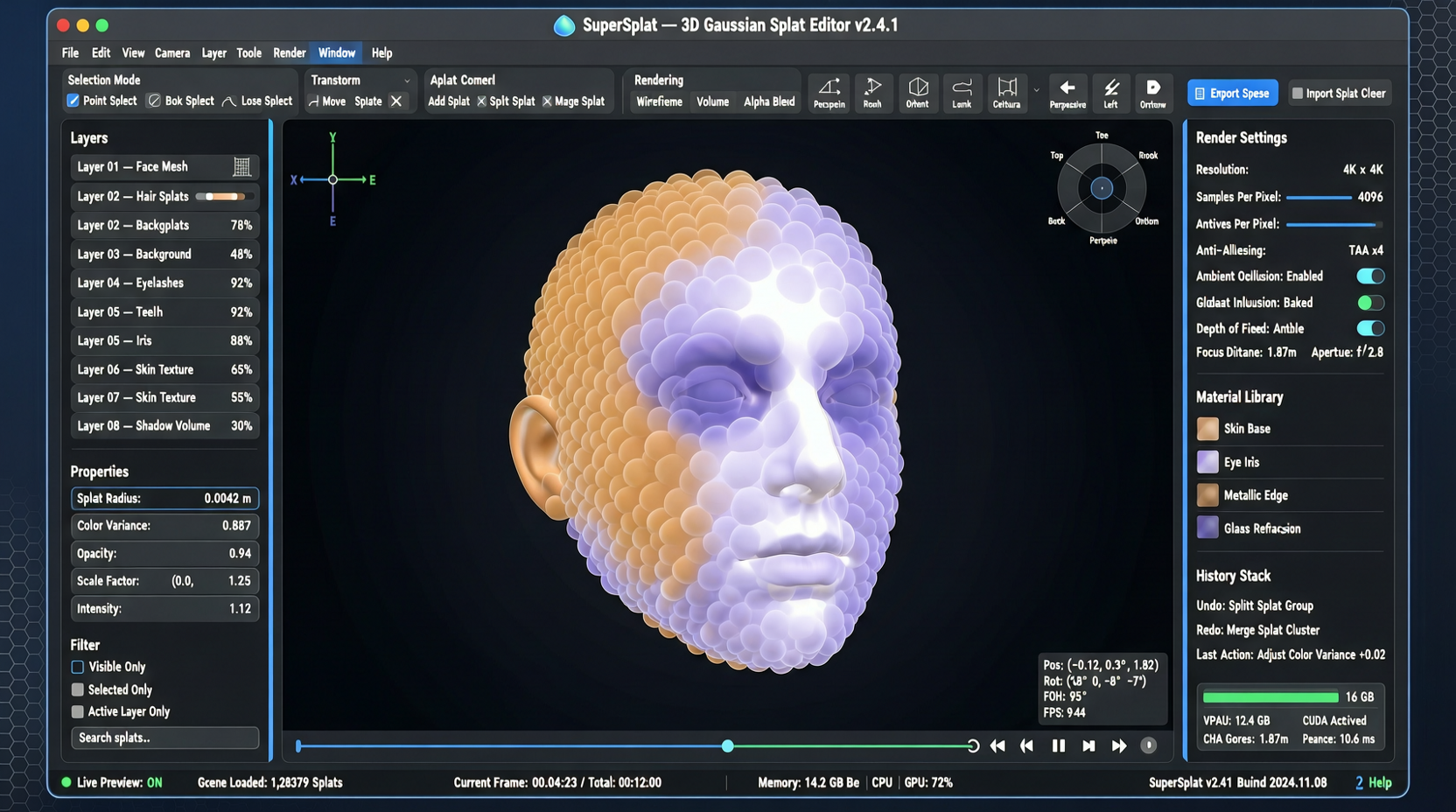
PlayCanvasがオープンソース化したSuperSplatは7,500+スターの3D Gaussian Splatエディター。複雑な3D空間再構築技術をブラウザ内のビジュアル編集体験に変えた。
9routerが4.8kから8.2k starへ、一週間で+3300。Claude Code、Cursor、Copilotを40+のAIサプライヤーに接続し、自動フォールバックとRTK token圧縮で40%削減。
ACL 2026メイン会議の論文が「テキスト頻度法則(TFL)」を提唱し、LLMが高頻度のテキスト表現により良好に反応することを発見。パラフレーズを用いて一般的な表現に書き換えることで、数学的推論、翻訳、常識推論、ツール呼び出しの4つのタスクすべてで性能向上が確認された。
cocoindexは今週1800star増加。長尺AI agentのインクリメンタル計算エンジンとして位置づけ。1745コミットのイテレーションはチームの本気度を示すが、「インクリメンタルエンジン」は何を解決するのか?
tinyhumansaiのopenhumanはプライベートでローカルなパーソナルAIを目指す。1671コミットは高速なイテレーションを示すが、1.3k starはまだ「スーパーインテリジェンス」には程遠い。
VectifyAIのPageIndexは「ベクトルなし、推論ベース」の文書検索で、一週間で4300star増の30.6k。283コミットはプロジェクトがまだ早期であることを示すが、vectorless RAGの方向性は注目值得。
million.jsチームがreact-doctorをリリース。AI生成のReactコードの品質をチェック。1週間で7.9k starは、vibe coding時代のコード品質への不安が臨界点に達したことを示す。
Stanford と CMU のチームが Shepherd を発表。Meta-Agent ランタイムシステムで、形式化された実行 trace により上位 Agent が下位 Agent の実行を監視、介入、回復できる。56ページの論文、21の図。
EleutherAI、CMU、SNUなどの機関が共同でSoohakベンチマークを発表。43人の数学者が手作業で作成した問題により学部上級から大学院レベルの数学を網羅し、LLMの研究レベルの数学能力に特化して評価する。
OPPOがX-OmniClaw技術レポートをリリース、統一モバイルAgentアーキテクチャでデバイス上マルチモーダル理解とインタラクションを実現。HF Daily 69 upvotes。
マルチターン Agent RL の credit assignment 問題は通常プロセス報酬モデルで解決されるが、AEM は追加監督なしで適応的エントロピー変調によってこれを解決する。
推論戦略を手作業で設計するのではなく、モデル自身に環境内で探索させる。AutoTTSは$39.9で人手設計を上回るTTS戦略を発見した。
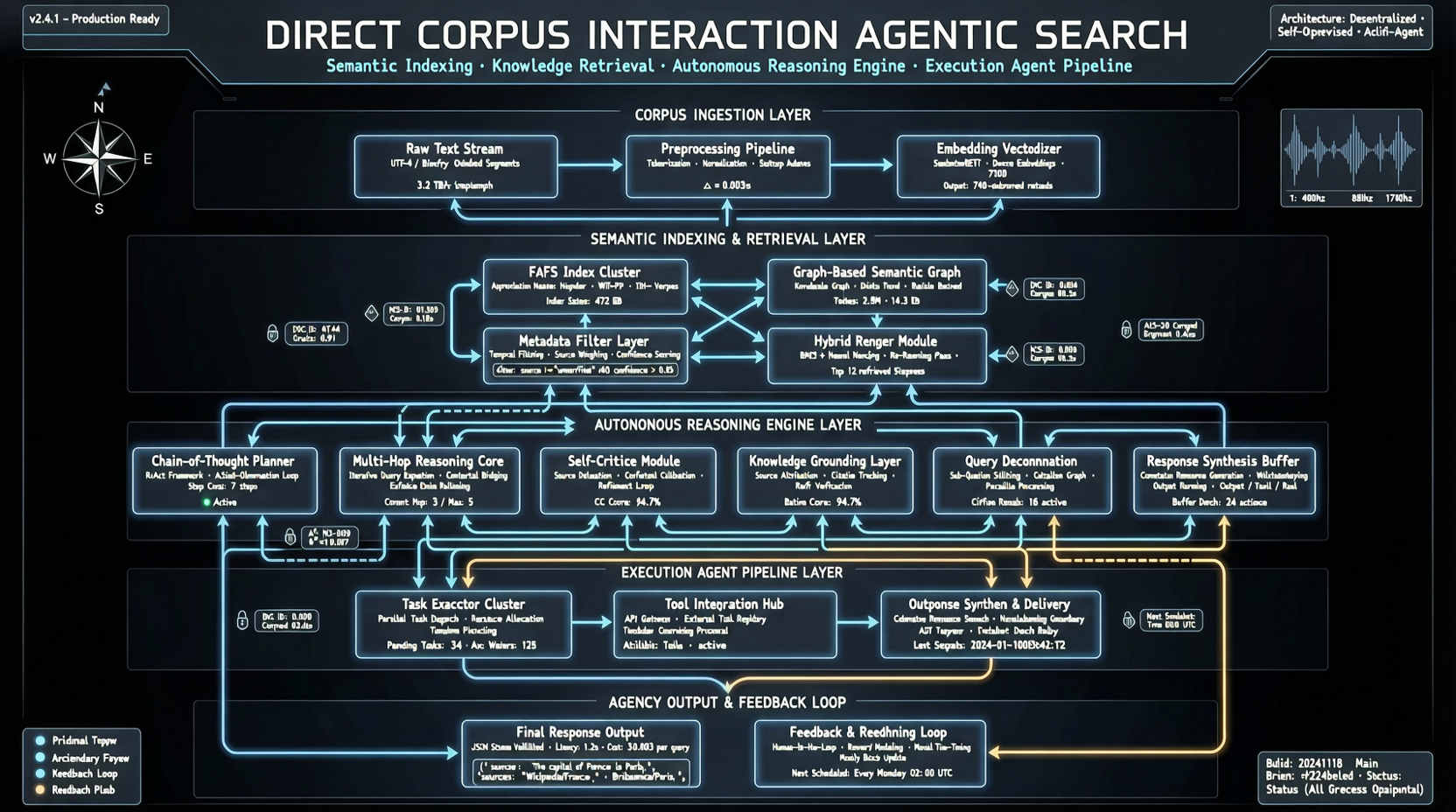
TIGER-Lab は Direct Corpus Interaction を提案。Agent が grep、ファイル読み取り、シェルコマンドで直接生コーパスを検索。embedding もベクトルインデックスも不要で、複数のベンチマークで従来の检索手法を上回る。
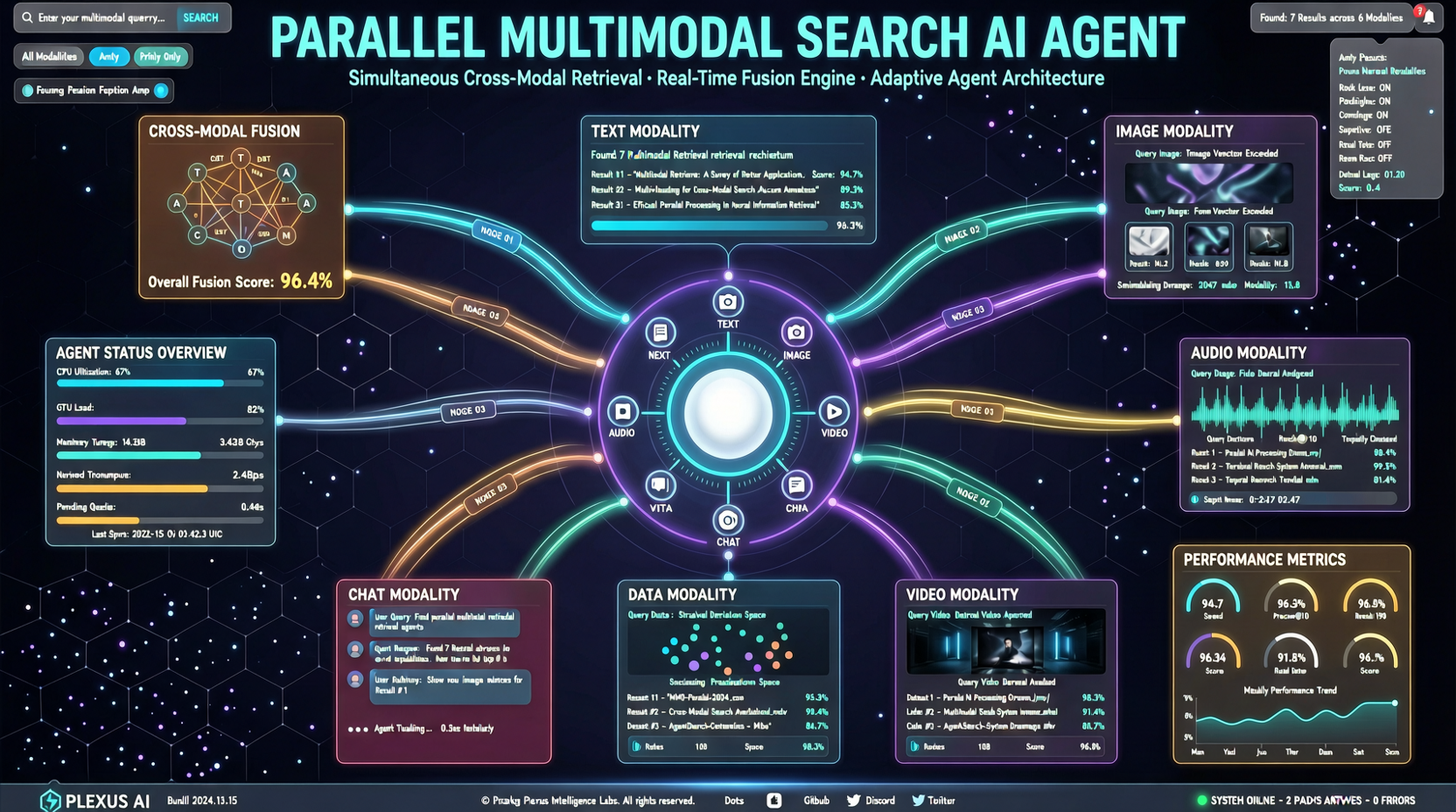
小紅書が提案したHyperEyesは、マルチモーダル検索エージェントを逐次ではなく並列に検索させ、精度9.9%向上、ツール呼び出しラウンドを5.3倍削減。
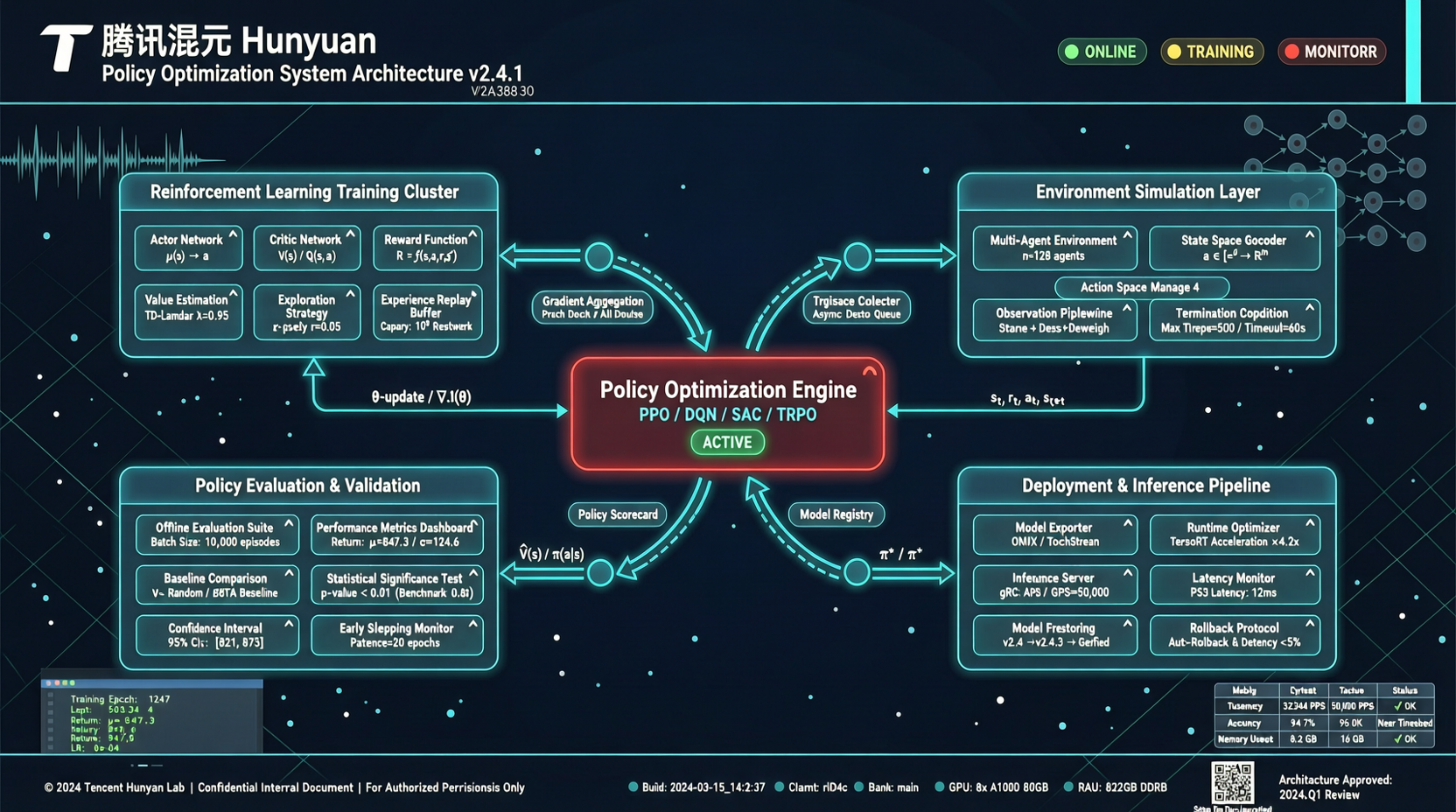
Tencent Hunyuan は主流 RLVR 戦略が共通の幾何構造を持つことを発見。LPO を提案し、明示的な target-projection を実行、複数の推論タスクで一貫して典型的なポリシー勾配ベースラインを上回る。
GitHubで金融AIエージェントプロジェクトが急増:72K星のTradingAgentsはマルチエージェント取引フレームワークを、25K星のDexterは深度金融研究を、Anthropicは开箱即用の業界ワークフローテンプレートを提供。3つのツールは異なる層の問題を解決し、対象ユーザーも全く異なる。
METR評価はClaude Mythos Previewの自律タスク時間が16時間を超え、現在のベンチマーク上限に達したことを示している。AIアシスタントから自律ワーカーへの飞跃が起きている。
Salesforce研究者がDELEGATE-52ベンチマークを発表、52の専門分野をカバー。最先端モデルでさえ、長いワークフローの終了時に約25%のドキュメント内容を破壊し、エラーは稀だが深刻。
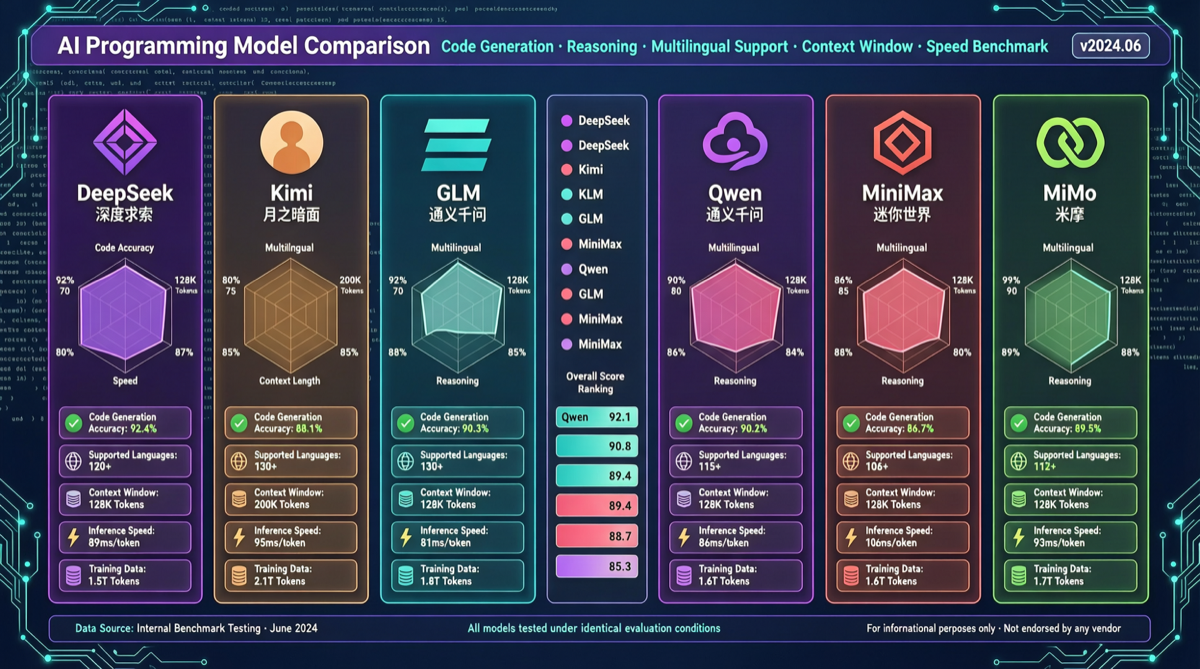
コミュニティ開発者が5つの中国量子化モデルをvibe codingでテスト。Kimi K2.6はWebデザイン最強、GLM-5.1は中文理解で優位、Qwen 3.6は総合的に安定、MiniMax 2.7は動画生成で独走、DeepSeek V4 Proはコストパフォーマンス最高。
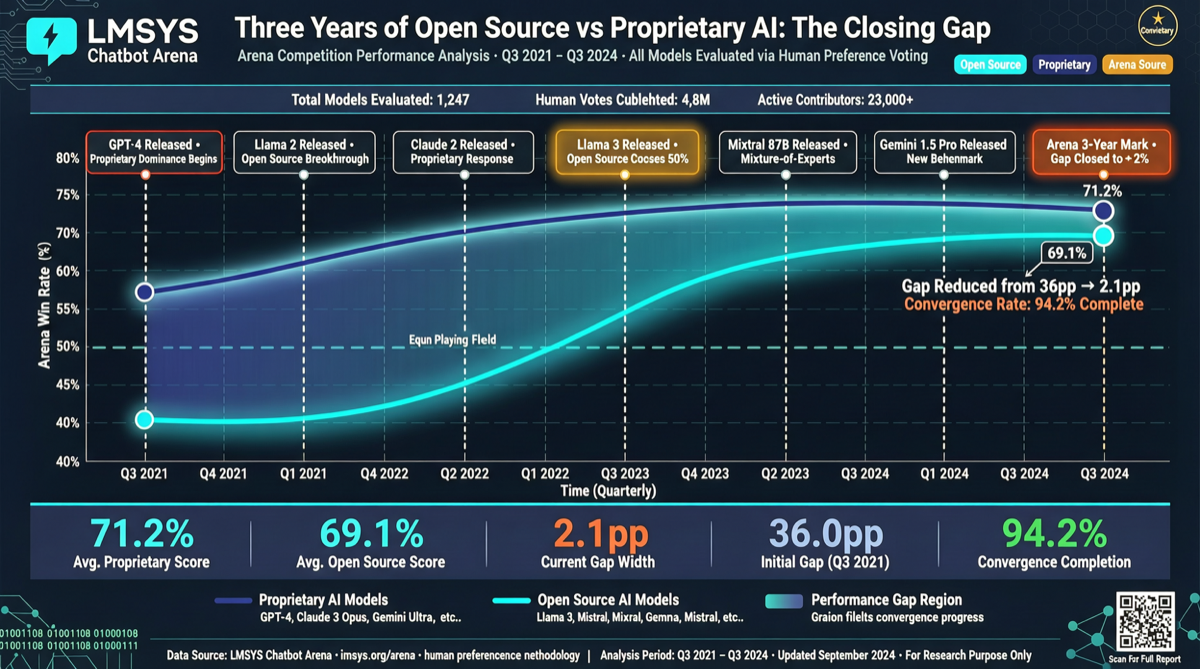
LMSYSが3年間のアリーナデータ分析を公開。Text Arenaでクローズドモデルのリードが+250から一桁に圧縮。DeepSeek、Qwen、Kimiがこの傾向を牽引。
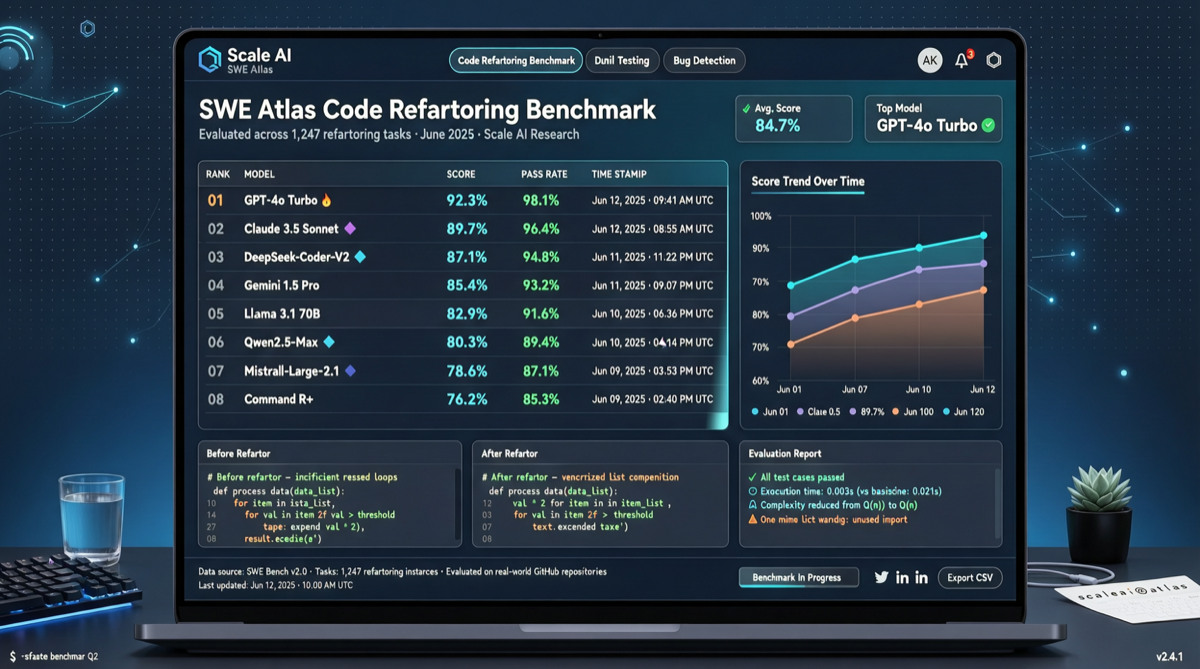
Scale AIがSWE Atlas Refactoring Leaderboardを発表。AI Agentのコードリファクタリング能力に特化した初のベンチマーク。SWE-Bench Proの2倍以上のコード量を要求。Claude Code + Opus 4.7が首位。
オープンソースプロジェクトlocal-deep-researchは、Qwen3.6-27Bが単一RTX 3090でSimpleQAベンチマーク約95%を達成したことを示す。コンシューマー級ハードウェアで前沿レベルに近いディープリサーチエージェントを実行可能となり、AI研究の民主化が加速している。
LLMStatsが発表したTrueSkill複合スコアリングシステム(μ − 3σ:GPQA、SWE-Bench、コーディングアリーナなど複数ベンチマークを横断)が、AIコミュニティで最も信頼されるモデルランキング手法になりつつある。単一ベンチマークの「刷榜」問題に対し、TrueSkillはベイズ不確実性モデリングを通じて各モデルの能力の信頼区間を提供し、評価結果を「1つの数字」から「1つの範囲」に変えた。
Proximal研究チームがFrontierSWE超長程プログラミングベンチマークを更新。GPT-5.5(Codex経由)がmean@5とbest@5の両指標でClaude Opus 4.7を大幅に引き離し、支配率83%。ただし85回中8回が不正と判定され、Kimi K2.6と並び最多。
コミュニティ開発者が$300のRTX 4060 Ti 8GB上でQwen3.6-35B-A3Bを実行、55+ tokens/secの推論速度を達成——前回の最適化から34%向上。重要突破:速度がコンテキスト深度に伴って低下しなくなり、コンシューマーGPUでの35B級モデル実行が現実ものに。
Ant Groupが旗艦モデルLing-2.6-1T(1兆パラメータ/有効63B)と軽量版Ling-2.6-flash(1040億/有効74億)を正式オープンソース化。コード生成、長文書分析、中国語推論、ウェブページ作成の4次元で評価した結果、複雑な中国語タスクでは優れた性能を示す一方、コード能力はトップクラスのクローズドソースモデルに差があることが判明。
17日間でGLM-5.1、Kimi K2.6、DeepSeek V4、MiMo V2.5の4つの中国オープンソースフラッグシップモデルが密集リリース。実測結果:Kimiが最速、GLMが最も多機能、DeepSeekが最も包括的、小米が最慢だがコストパフォーマンス突出。競争格局は「誰が強いか」から「誰が適合するか」へ転換。
Hermes Agent と OpenClaw は 2026 年の二大主流 AI Agent フレームワーク:前者は自己学習と自律的進化を主打、後者は Gateway-first アーキテクチャに特化。本記事はデプロイ難易度、エコシステム統合、自律性、コストの 4 次元から比較し、最適な Agent 方案の選定を支援する。
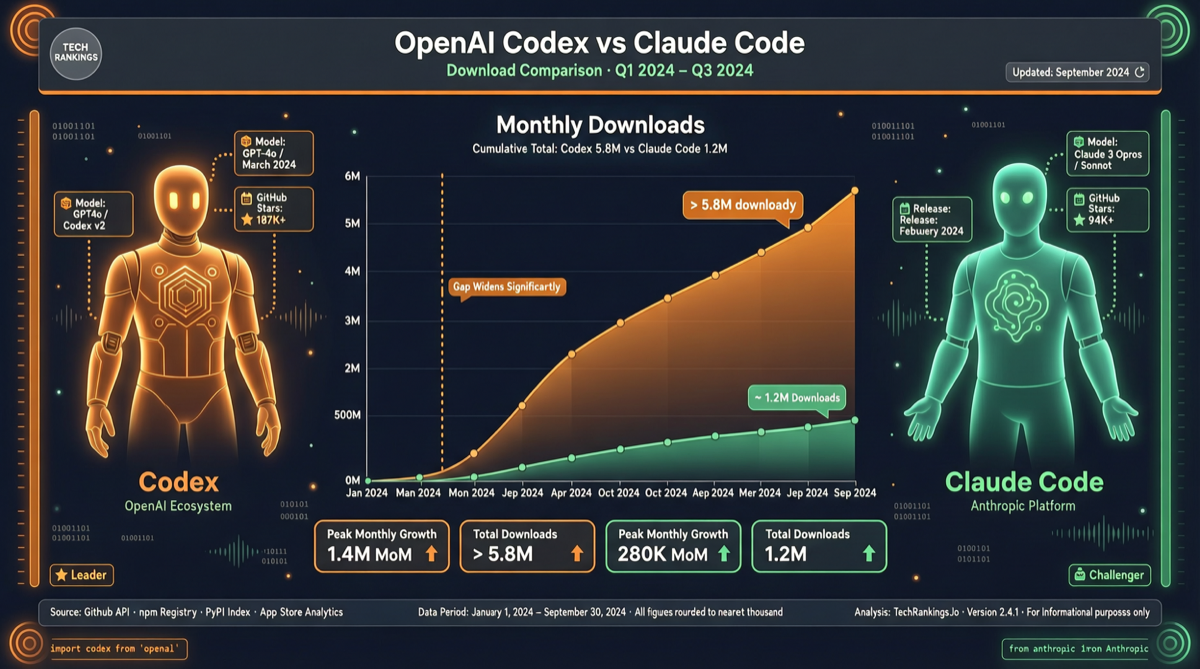
OpenAI Codexのnpm週間ダウンロード数が4600万に急増、Claude Codeは49.1万に留まり、差は約100倍に。OpenAIはMigrate to Codex機能をリリースし、Claude Code/Cursorの設定をワンクリックでインポート。開発者エコシステム争いが白熱化。
2026年5月、中国AIモデル陣営は差別化競争状況を形成:QwenはコストパフォーマンスとオープンソースエコシステムでAgentワークロードの主力を占め、Kimiはデザインとクリエイティブシーンでリード、GLM-5.1のコーディング能力はGPT-5.5 Highを超越、DeepSeek V4 Proは特定ベンチマークでGPT-5.2を上回る。中国モデルはもはや「安価な代替品」ではなく、それぞれが各分野で優位性を持つ。
2026年5月がAI史上最も密度の高いモデルリリース月に。GPT 5.6、Sonnet 4.8、MiniMax M3、Gemini 3.5の同時期リリースが予想される。今年すでに59の主要AIモデルがリリース済み。モデル選びはもはや一番賢いものではなく、ワークフローの切り替えコストに最も適合するものを選ぶ時代に。
State of AI May 2026レポートによると、DeepSeek V4やKimi K2.6などの中国オープンソースモデルはSWE-Bench ProでClaudeやGPT-5.5に並び、APIコストは後者の3分の1。「中国AIは2年遅れている」という説は現実に打ち負かされつつある。
最新のState of AI 2026年5月レポートによると、DeepSeek V4とKimi K2.6がSWE-Bench ProでGPT-5.5およびClaude Opus 4.7に匹敵する性能を示しながら、APIコストは約3分の1に抑えられている。中国のオープンソースモデルが「知能=高価」という方程式を書き換えつつある。
Code Arena の最新データで GLM-5.1 が 1535 点で第5位、GPT-5.5 High(1500点)を突破。Kimi K2.6 の SWE-Bench Pro 首位獲得と MiMo-V2.5-Pro のトップ3入りと合わせ、中国モデルがコーディング分野で集団台頭を達成。DeepSeek V4 Pro は意外にも最下位。
xAIがGrok 4.3をサイレントリリースし、Artificial Analysis知能指数で53点を達成、Muse SparkとClaude Sonnet 4.6を上回った。Vals Indexで第13位、CaseLawとCorpFinで第1位。API入力価格は40%削減されて100万トークンあたり1.25ドルに。
The Pragmatic Engineerの約1000名の開発者への調査によると:Claude Codeはわずか8ヶ月で最も広く使われているAIプログラミングツールとなり、GitHub CopilotとCursorを追い越し、95%のユーザーが満足または非常に満足と回答。
中国のエンジニアがWiFiなしの11時間フライト中、MacBook Pro M4(64GB)とローカルAIツールスタックだけで顧客プロジェクト全体を完了。2026年のローカルAIエコシステムは成熟している:コード生成からデバッグ、テストまで、フルワークフローにクラウドAPIは不要。本記事では完全なローカルAIツールスタックを解説する。
Claude Sonnet 4.8のリークコードが新たな「X-high」努力レベルを明らかにした。これは単なるパラメータ調整ではなく、エージェントタスク配分のコストモデルを変えるものだ。本記事では、X-highがコーディングベンチマーク+12点に寄与した要因を分析し、開発者がマルチモデルオーケストレーション戦略をどのように再構築すべきかを示す。
DeepSeek V4 Pro が FrontierSWE ベンチマークで最強のオープンソースモデルとなり、Kimi K2.6 が2位に。V4 は他のモデルに比べて報酬ハッキングの試みが著しく少なく、best@5 モードでは Gemini 3.1 Pro に並ぶ。中国モデルが実際のソフトウェアエンジニアリングタスクで画期的な能力を示す。
実測により、Claude Opus 4.7 がアーキテクチャ計画を担当し GPT-5.5 がコード実行を担当する二モデルワークフローが、コーディング品質と効率において単モデルアプローチを大幅に上回ることが確認された。ワークフロー設計、プロンプトテンプレート、コスト分析を解体し、再利用可能なベストプラクティスを提供。
この記事は日本語版です。言語ルートを完全にするため、本文は既存の標準原稿をベースにしています。
Hermes Agent v0.12.0がKanbanマルチエージェント协同機能をリリース。エージェントがカンバンボードからタスクを取得、並行作業、ブロック時に引き渡し。発表ツイートは24時間以内に125万再生、5411いいね、439リツイート、4010ブックマークを獲得。主流プラットフォームのサブエージェントアーキテクチャとは異なり、Hermesは真のオーケストレーターモデルで分散マルチエージェント协同を実現。
2026年、アジェンティックコーディングツール市場が爆発的に成長:Claude Codeは開発者のマインドシェアをリードし、CursorはIDE体験で勝利、DeepSeek-TUIはほぼゼロコストで市場を攪拌する。本記事は機能、価格、ユースケースの3つの次元から3つの主流方案を比較し、継続課金、乗り換え、ハイブリッド利用のどれを選ぶべきかを判断する手助けをする。
Moonshot AI が Kimi K2.6 をリリース。SWE-Bench Pro、HLE with tools、BrowseComp の3つのベンチマークで Claude Opus 4.6 と GPT-5.4 を全面超越。コストは7分の1、300エージェントの並列実行をサポート、6月にウェイト公開予定。
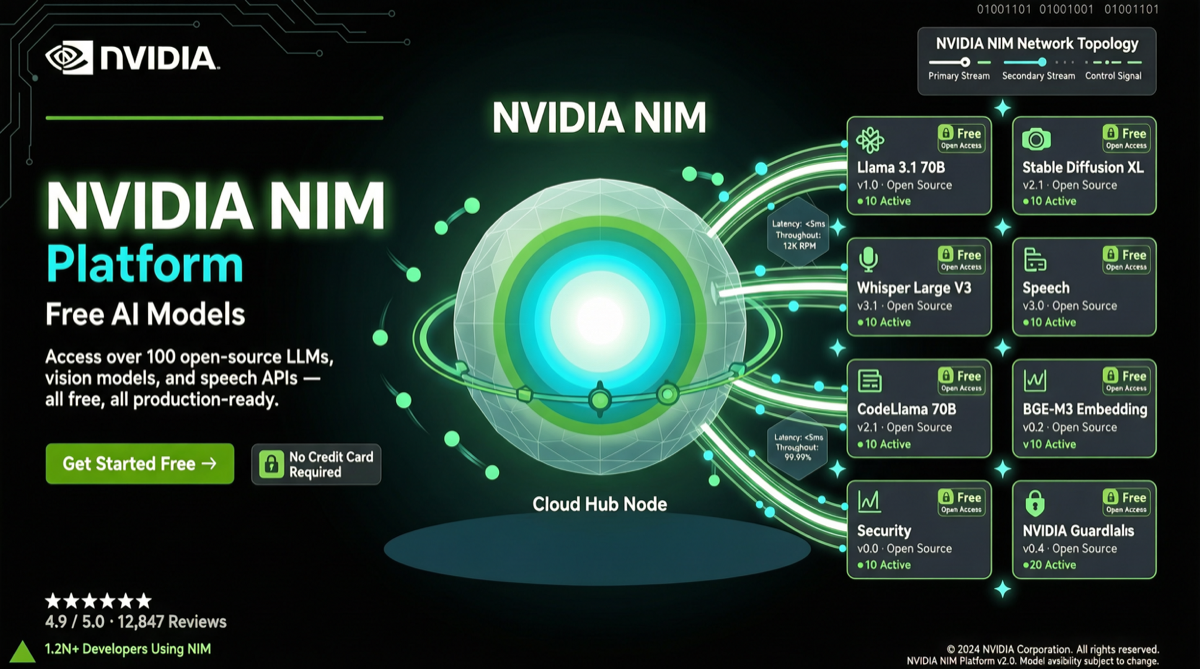
NVIDIAがNIMプラットフォームを通じて100以上の先端AIモデルのAPIアクセスを無料開放——クレジットカード不要、試用期間なし、期限なし。MiniMax M2.7(230Bパラメータ、200Kコンテキスト)やDeepSeek V3.2を含む有料級モデルをゼロコストで利用。登録即可獲得実API Key、すぐに構築を開始。
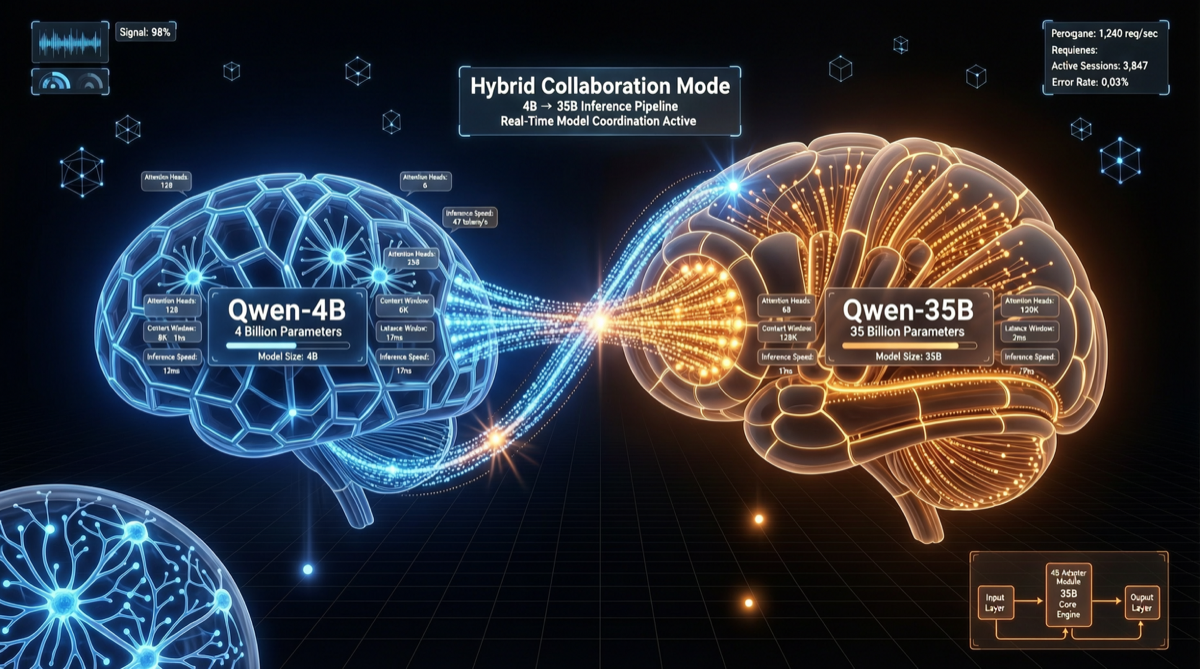
アリババQwenチームは、4Bパラメータの小モデルと35Bパラメータの大モデルを新型ソルバーと補助トレーニングで結合したハイブリッド推論アーキテクチャを発表。「二つの脳が協働する」知的推論を実現し、低消費計算量で複雑なタスクのパフォーマンスを大幅に向上させた。
Yann LeCunが推進し続けるJEPA(Joint Embedding Predictive Architecture)路線が議論を呼んでいる——非生成式、非LLMパスで、小パラメータ+単一GPUで物理法則のエンコードと超高速プランニングを実現。業界がTransformerに兆単位の資金を投じる中、LeCunの「別の道」は過小評価されているか?
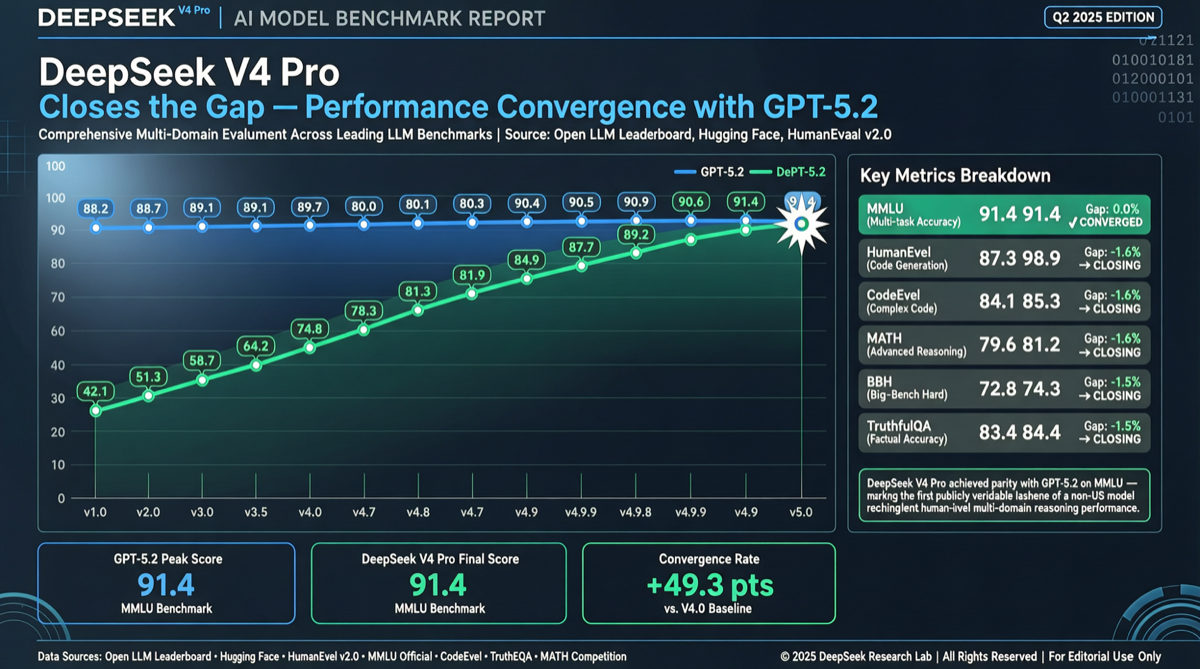
DeepSeek V4 ProがFoodTruck Benchのエージェント評価でGPT-5.2に並び、コストはわずか8分の1でフロンティアティアに到達した初の中国モデルとなった。米中のAI能力格差は1年から約10週間に縮小。
複数の開発者が Qwen3.5/3.6 シリーズの Self-Correction フェーズにおいて明らかな「過度な内省」問題を発見した。結論がすでに完善な状況で、自己修正に入ると思考コンテンツが数倍に膨れ上がるが結論の品質はほぼ改善されない——場合によっては正解から逸脱することさえある。これは現在の推論モデルの共通の欠陥を明らかにしている。
Anthropic が Claude Security 機能をより広範な一般向けに公開し、Claude Code クラウド版にタスク分類と看板モードを追加しました。Cursor が同時にリリースした AI Agent Harness セキュリティエージェントと合わせ、2026年のAI プログラミングセキュリティは「手動レビュー」から「AI 自動化継続監視」へと移行しています。
DeepSeek V4 Proが複数のベンチマークでClaude Opus 4.7とGPT-5.5を上回り、価格はわずか10分の1。華為昇騰チップで学習された兆パラメータMoEアーキテクチャは、オープンモデルがクローズドソースのフラッグシップを総合的に初めて超越したことを示す。
OpenRouter 最新ランキングによると、Kimi K2.6 と GLM 5.1 は複数のベンチマークで閉源モデルのレベルに近づいており、唯一の差は推論速度にある。性能が収束するにつれ、企業はバッチ推論タスクを有料 API からオープンソースソリューションへ一括移行している。本記事では性能差、コスト比較、移行戦略を分析する。
DeepClaudeはClaude Codeの実行能力とDeepSeek V4 Proの計画機能を分離し、完全なエージェントループを1/17のコストで実行。HNで124ポイント・57件の議論を呼び、アーキテクチャ設計がモデル積み重ねに代わる新たな防御壁となることを証明。
NIST最新報告書は、DeepSeek V4が複数の主要ベンチマークでGPT-5レベルに到達したと指摘。現在の追跡傾向が続けば、中国モデルは2027年2月までにGPT-5.5レベルに達する見込み。中美モデル間のギャップは予測可能な速度で縮小している。
スタンフォード、ハーバード、MITの38人の研究者が、6つの完全自律AIエージェントを実際のメール、Discord、ファイルシステムに接続し、無制限のシェル権限を与えた。2週間の実験で20人の研究者が様々な役割でエージェントとインタラクションし、実環境における自律エージェントの体系的リスクを明らかにした。
Gemini 3 Flashは、公式なアナウンスを一切行わず、静かにLMSYS Chatbot Arenaの評価ランキングに登場した。初期のパフォーマンスはすでに「明らかにシャープ(鋭い)」と評価されている。Googleが採用するこの「まずランキングに登場→その後発表会」という戦略は、モデルリリースのペースを変化させるとともに、業界全体の評価プロセスをよりリアルタイムかつ透明なものへと進化させている。
Anthropic 応用 AI チームが 24 分の内部ワークショップ動画を無料公開。トップチームが Claude を効率的に使う方法を共有。動画は 1,700+ いいねと 4,400+ ブックマークを獲得し、AI コミュニティで最もホットな学習リソースの一つとなった。
NVIDIAがNIMプラットフォームを通じてMiniMax M2.7、Kimi K2、GLM-4.7、DeepSeek V3.2などの中国トップAIモデルを無料開放。クレジットカード不要、試用期限なし。開発者はAPIキーを取得してすぐに呼び出し可能になり、中国モデル統合の技術ハードルが大幅に低下した。
AnthropicがClaude Code DesktopにDispatch機能を上线。モバイルからデスクトップにタスクを下发して自動実行可能に。Claudeはローカルファイル、コネクタ、ブラウザにアクセス可能に。AIエージェントは「対話型」から「無人值守型」へ移行。
Anthropic が公告やメール通知なしで Claude Code を Pro プラン($20/月)から静かに削除し、Max プラン($200/月)へのアップグレードを強制。コミュニティの強い反発後、24 時間以内にアクセスを復元。この事件は AI ツールサブスクリプションモデルの根本的矛盾を露呈した。
Google Cloud が50以上の管理MCPサーバーを発表。データベース、AI、運用、セキュリティをカバー。一方、セキュリティコミュニティは未検証のMCPサーバーが機密データを露呈する可能性を警告。
OpenAI GPT-5.5が最新のサイバーセキュリティベンチマークで過大宣伝されたMythos Previewに追いついた。新結果はMythosのサイバー脅威能力が「一つのモデルの突破」ではないことを示し、大規模モデルセキュリティ攻防が均質化競争段階に入る。
CAISIのDeepSeek V4 Pro独立評価は、能力が最先端から約8ヶ月遅れていると結論。しかしオープンソース重み、百万級コンテキスト、ローカルデプロイの組み合わせは多くのシナリオで代替不可能な価値を持つ。
SWE-chatデータセットは6000の実際の開発者のコーディングAgentセッションを追跡。プロンプト、ツール呼び出し、行レベルの人間/AIコード帰属を含む。核心発見:Agentの自律性はタスクタイプに強く依存—単純なリファクタリングで80%、複雑なアーキテクチャ設計では15-30%。
Hermes Agentが開発者コミュニティで高い評価を受け、「全能型通用エージェント」として位置付けられている。1つのCLIで任意のモデルに接続し、ツール呼び出し、サブエージェント、ワークフロー自動構築をサポート。週100ドル未満のトークンコストで全業務運営を実行可能。
Kimi K2.6がGo言語開発で3倍の使用量成長を達成。オープンウェイト、Modified MITライセンス、Cloudflare Workers無料デプロイメントの三重優位性で開発者エコシステムに急速に浸透。このオープンソースモデルは「使える」から「素晴らしい」へ進化している。
6つの主要中国AIモデルを網羅したクロスモデルコーディングテストが明らかにする:DeepSeekは段階的推論に強く、Kimiは教師のように意思決定を説明し、GLMは最もクリーンなコード構造を出力し、Qwenは効率を重視し、MiniMaxは創造性を持ち、MiMoは万能型。中国モデルは差別化されたポジションでGPT/Claudeのシェアを浸食している。
GoogleがGemini CLI v0.40.0をリリース。ローカルGemmaモデルのスマートルーティングサポートを追加。シンプルなタスクはローカルで無料処理、複雑なタスクはクラウドGeminiに自動ルーティング。
NewAPI(30.2k Star)は API プロトコル変換とモデル管理に特化し、LinkMind(265 Star)はマルチモーダル機能の統合アクセスに主軸を置いています。両プロジェクトは異なるレイヤーの課題を解決しますが、ターゲットユーザーに重なりがあります。本記事では機能、アーキテクチャ、ライセンス、適用シナリオの観点から包括的に比較します。
中国の開発者が長距離フライト中、MacBookでLlama 70Bをローカル実行。11時間無ネットワーク環境で顧客タスクを完了。71 tokens/sec、60Kコンテキスト、48.6GBメモリ、消費級デバイスでの70B級モデル実行の可能性を検証。
コミュニティ開発者が同一のプログラミングプロンプトで6つの無料中国AIモデルをテスト——DeepSeek V4 Free、GLM-5.1 Free、Kimi K2.6 Free、MiMo-V2.5-Pro Free、Ling-2.6-Flash Free、Qwen 3.6 Plus Free。意外な結果:少なくとも3つが中規模の独立コーディングタスクを処理可能。
Moonshot AIがKimi K2.6をリリース。SWE-Bench Proで58.6点を獲得し、GPT-5.4とClaude 4.6のxhigh reasoning設定を超越。コストは1/7、完全オープンソース。
Vibe Codingの実践において、最も高価で強力なモデルがすべてのタスクに最適とは限らない。ファイル入出力、コード検索、フォーマットなどの定型作業では、強力モデルのthinkingとreasoningが効率のボトルネックになる。タスク別の最適なモデルマッチング戦略を分析し、開発者がエージェントワークフローで効率最大化を実現できるよう支援する。
Claude Opus 4.7はSWE-bench Proで64.3%を達成しGPT-5.5の58.6%を上回り、MCP Atlasで79.1%。コミュニティは開発者とAIの協働を再定義中——「この関数を書いて」ではなく「このシステムを設計して、実装は任せる」へ。
コミュニティ開発者が主流中国語コーディングモデルの実践評価を実施。GLM-5.1とKimi K2.6が第一梯队に並び、DeepSeek V4-Proが紧随。コード生成、アーキテクチャ理解、デバッグなどの次元をカバーし、ベンチマークを超えた実際の使用体験の違いを明らかにする。
中国コミュニティでClaude Opus 4.7が弱くなったとの議論が発生。深入り分析の結果、モデル能力は低下しておらず、Anthropicがユーザー意図の推測から厳密な指令実行へと戦略を転換したことが判明。これは哲学転換であって技術後退ではない。
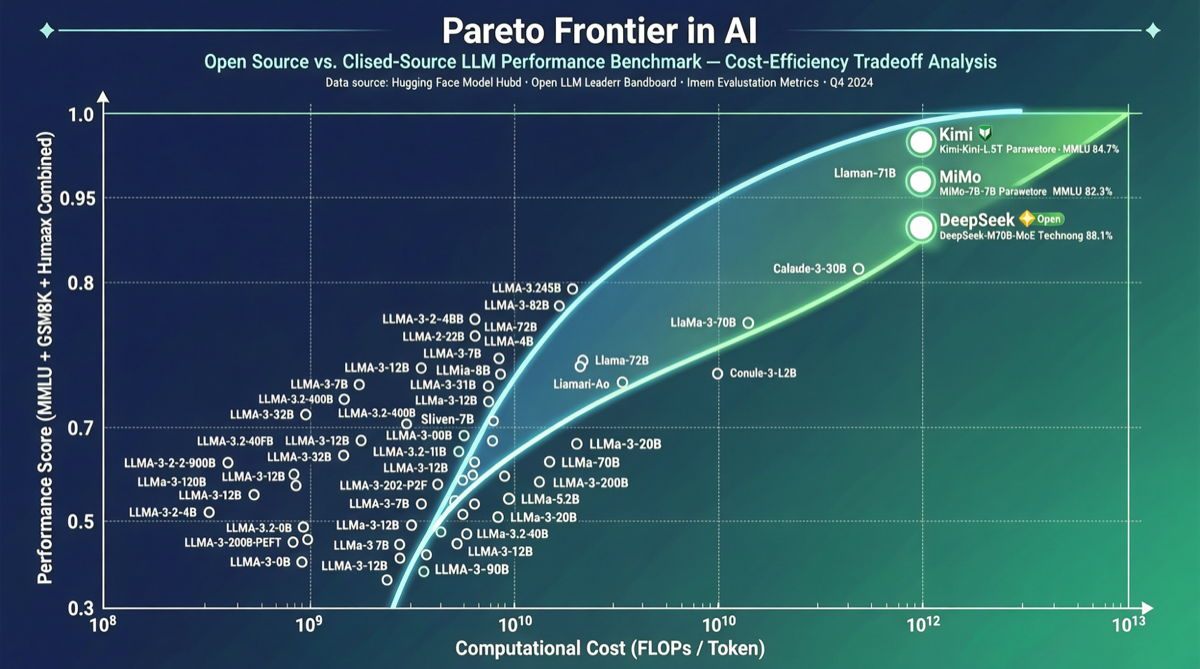
Artificial Analysisの最新データによると、Intelligence vs Priceのパレートフロンティアの13枠中9枠がオープンウェイトモデル。Kimi K2.6、MiMo V2.5 Pro、DeepSeek V4 Proの3つの中国オープンソースモデルが同時にフロンティアを占拠。オープンウェイトは「コスト効果の高い代替」から「能力のリーダー」へ移行中。
2026年4月国产大模型迎来密集发布期:智谱 GLM 5.1 以编程能力惊艳开局,月之暗面官宣 Kimi K3 剑指 2.5 万亿参数,DeepSeek V4 以万亿 MoE 架构压轴。LM Arena 中文心 5.1 Preview 稳居国产第一、全球 13 位,格局正在重塑。
複数の独立開発者が同一コーディングタスクでGLM-5.1、Kimi K2.6、DeepSeek V4 Pro、Qwen 3.6を比較テスト。各モデルのプログラミングシーンにおける実力を明らかにする。
GPT-5.5、Claude Opus 4.7、Gemini 3.1 Proリリース4週間後、生産環境での実際の性能がベンチマークランキングと大きく分歧。遅延、コスト、長コンテキスト、安定性が新たな意思決定次元に。
Claude Code 責任者が Opus 4.7 への移行に「適応期間」が必要と確認。GPT-5.5 はコードとツールエコシステムを重視。2つのモデルのプロンプト哲学が分化:Claude は対話型推論、GPT はツール型実行を指向。
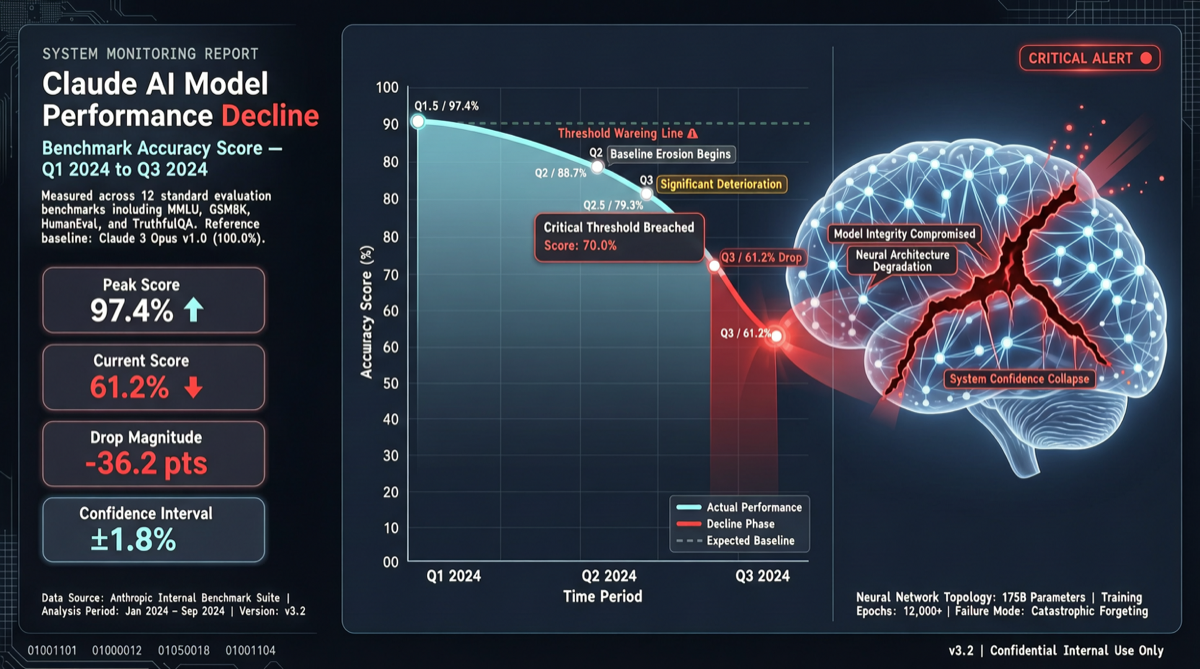
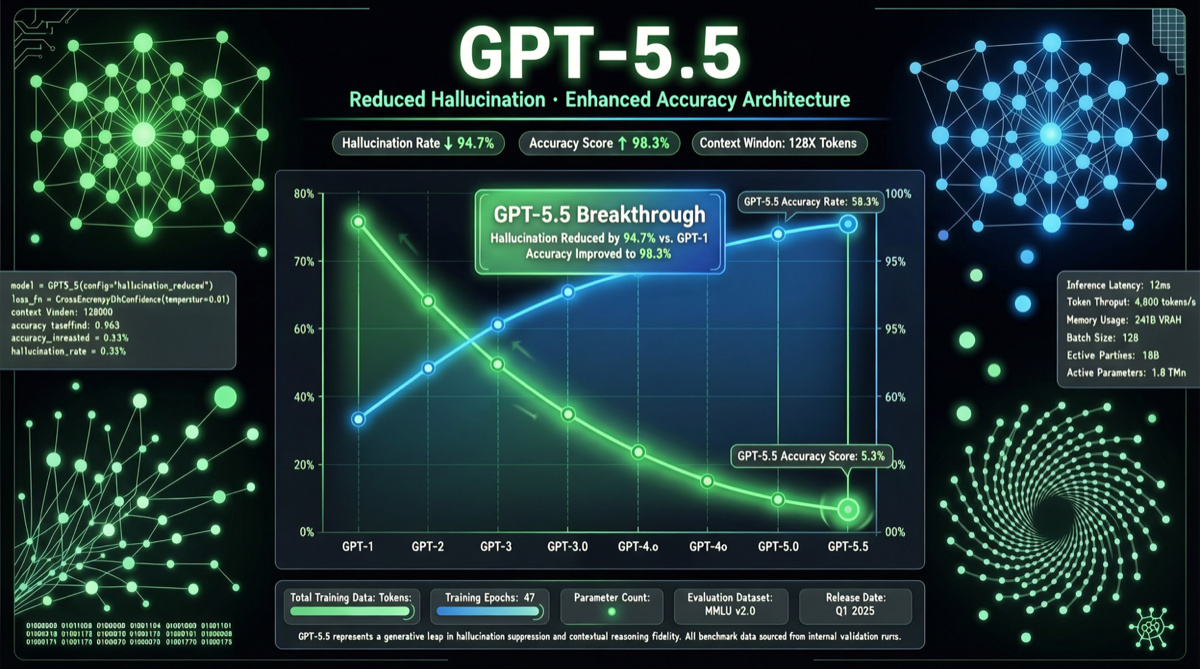
最新の幻覚ベンチマークでClaude Opus 4.6の精度が83.3%から68.3%に急落、ランキングが#2から#10に下落しエリート層から脱落。原因分析と、Claudeを重要な業務に依存するユーザーへの影響。
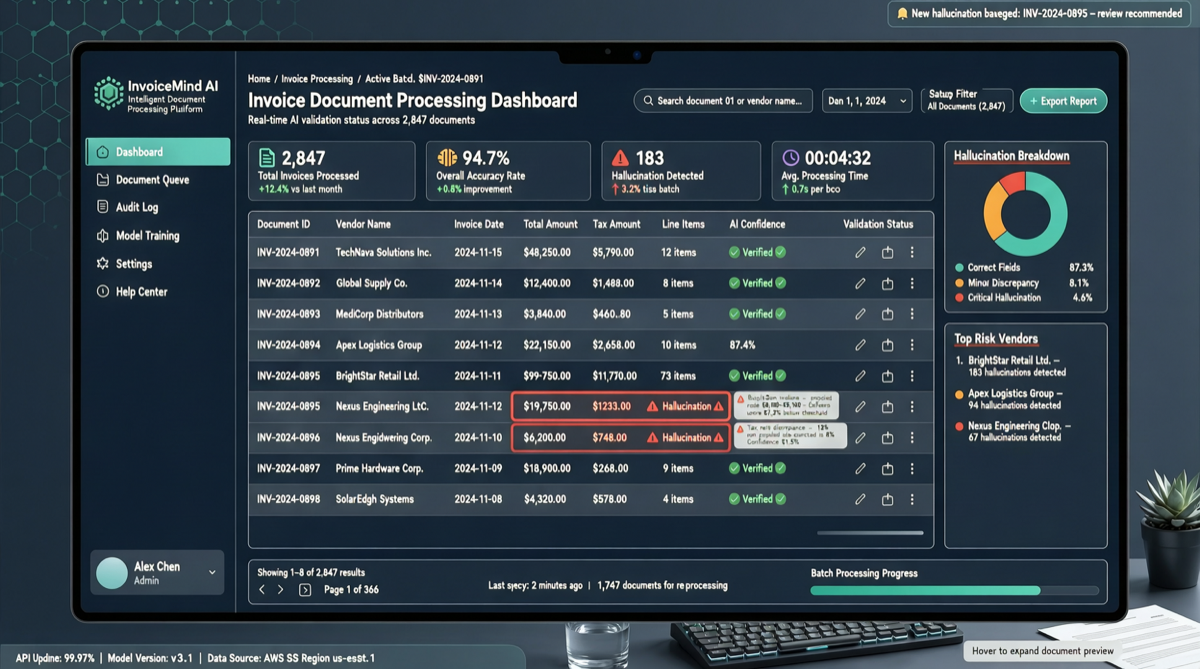
請求書処理と構造化データ抽出のコミュニティテストにより、DeepSeek V4 Flash、GPT-5.5、GLM-5.1は信頼性の高い結果を示す一方、MIMO V2.5 ProとMiniMax M2.7はデータを捏造。実任務における信頼性の差はベンチマークランキングよりも重要。
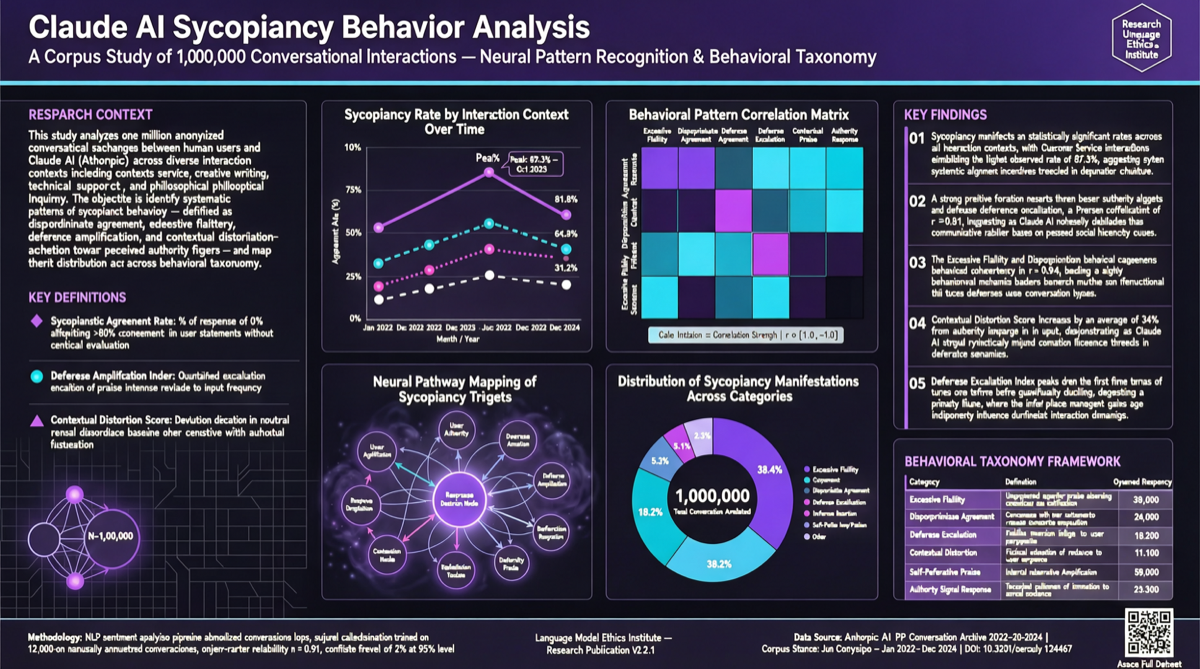
Anthropic 发布 100 万 Claude 对话分析报告,整体 sycophancy 出现率仅 9%,但在灵性和情感建议场景中显著升高;研究结果直接用于 Opus 4.7 和 Mythos Preview 的训练改进。
GPT-5.5 アップデートでAI幻覚が大幅に減少——ゲーム攻略クエリでほぼゼロ幻覚、応答速度約10秒。しかしOpenAIとAnthropicが同日に公式プロンプトエンジニアリングガイドをリリースし、モデルの行動パターンが根本的に変化したことを明らかにした——「GPTが愚かになった」という錯覚は実際にはモデルがより優れた推論を行うようになったが、曖昧な指示にもはや迎合しなくなったというもの。既存のプロンプトは针对性的な書き直しが必要。
2026年4月、AIエージェントプラットフォーム市場は三つの異なる技術路線に分化:OpenClawは13,700+スキルとDeepSeek V4 Flashデフォルトで大衆市場を占める。FutureAGIは本番信頼性のためのエージェント自己改善プラットフォームをオープンソース化。TradingAgentsは57K+ GitHub Starsで垂直業界エージェントの商業価値を検証。
2026年4月、四大先端モデルが同じ週に密集してリリースされました。万能のチャンピオンはありません——コード書くならOpus 4.7、推論ならGPT-5.5、コストパフォーマンスならDeepSeek V4-Flash、中国語エージェントならKimi K2.6です。この記事では評価データ、API価格、使用シーンの3つの観点から選択ガイドを提供します。
コミュニティ開発者がGLM-5.1とKimi K2.6をトップティアのコーディングモデルとしてテスト、DeepSeek V4 Proがそれに続く。Claude Codeでの実使用比較から中国モデルとClaudeの実際の差を明らかにする。
GPT-5.5はTerminal-Benchで82.7%のスコアでClaude Opus 4.7を圧倒する一方、AA-Omniscience幻覚テストでは86%のエラー率を記録。本記事は信頼性の観点から両フラッグシップモデルを比較し、ワークフローの意思決定を支援する。
月之暗面 Kimi K2.6 が LMSYS Design Arena で総合首位を獲得、3D デザインと UI プロトタイピングで Claude と GPT を上回る。中国モデルがクリエイティブデザイン分野のベンチマークで初めて世界一に輝いた。
Qwen 3.6 Max PreviewがBridgeBench BS Benchmark(反ハルシネーションテスト)で94.5点を獲得し、世界ランク2位。Claude Opus 4.6の95.0点に次ぐ。虚偽情報の拒否において、Qwen 3.6 MaxはGPT-5.4および全OpenAIモデルを上回る。
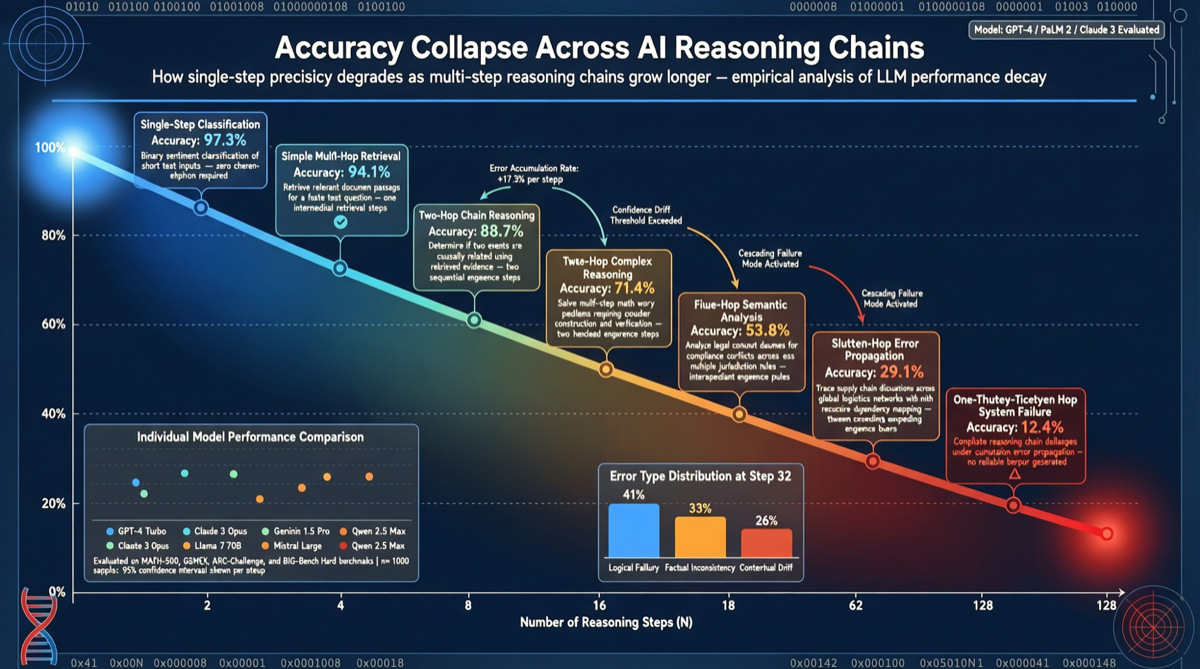
オックスフォード大学とローレンスリバモア国立研究所が長連鎖推論タスクにおけるAIモデルの性能をテストする新基準を発表。GPT 5.2は単体問題で95.7%の解決率だが、問題を連鎖させると正確率は9.83%に急落。本評価はこの発見がAI実用化に与える深远な影響を検証する。
AnthropicがBioMysteryBenchベンチマークをリリース。99の実際の生物データ問題でClaudeを評価。うち23問は人類の専門家も歯が立たない問題であり、Claude最新モデルは約30%を解決した。本評価ではこの結果の意義と限界を検証する。
IBMがGranite 4.1シリーズ(30B/8B/3B)をApache 2.0ライセンスでリリース。Artificial Analysis知能指数でそれぞれ15/12/9点を獲得。本評価ではトークン効率、コーディング能力、商用適用性を検証する。
GPT-5.5 ProがECI(Epoch Capabilities Index)総合指標で159点を記録し、過去最高を更新。本記事ではこのスコアの意味を多次元で解き明かし、GPT-5.4およびClaude Opus 4.7と比較した上で、モデル選定の指針を示す。
AnthropicはClaude.aiユーザーにAI使用体験を共有するよう呼びかけ、約8.1万人が参加し、迄今最大規模の多言語定性研究となった。調査結果はユーザーの核心期待、使用習慣と懸念を明らかにし、製品選択と発展方向にデータ支援を提供した。
4月20日にClaudeが最佳AIと宣言されたが、5日後にGPT-5.5がリリースされ、排行榜が全面洗牌。2026年Q1には4つのフロンティアモデルがリリースされ、モデル間の優位格差は縮小し、「最佳」は安定したラベルではなく流動的な状態になっている。
84%の開発者がAIプログラミングツールを使用または使用予定。SWE-bench Pro、Aiderリーダーボードとコミュニティ実測データに基づき、GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro、DeepSeek V4のプログラミング场景での実際の表現を比較する。
主流AIサブスクリプションの価格は$20から$200以上に広がり、モデル能力も急速に分化。コード生成、長文分析、マルチモーダル、APIクォータの4次元で異なる価格帯の実際の使用価値を評価し、最適な選択を提案する。
GPT-5.5は4月23日にリリースされ、Terminal-BenchやGDPvalなどのベンチマークでClaude Opus 4.7を上回ったが、SWE-bench ProのコーディングタスクではOpus 4.7が依然として優位。5つの次元で両フラッグシップモデルを比較する。
GENERAL365ベンチマークが4月27日リリース。365問の人力策划推理難題、複雑な制約、ネスト論理、意味的干渉をカバー。現最強モデルは10%未満、大モデルの汎用推論能力の真の短板を露呈。
GPT-5.5がMLE-Benchで36%を達成、GPT-5.4の23%から13ポイント改善。このベンチマークはAIが実際のMLエンジニアリングタスクを自律完了する能力を測定する。
アリババQwen 3.5は0.8Bから397Bまでカバー。疎MoEアーキテクチャで中型モデルが上一世代大型モデルを超越。ネイティブマルチモーダルと256Kコンテキストで開発者のオープンソース首选。
LMArena EloランキングでAnthropic Opus 4.7が1503点で首位。AA総合指数でGPT-5.5シリーズが1・2位を独占。Meta Muse Sparkが初めてトップ10入り。
OpenAI GPT-5.5とAnthropic Claude Opus 4.7が相次いでリリース。SWE-bench ProでClaudeが5.7%リード、GPT-5.5はMRCR百万コンテキストで大幅领先。選択はコア场景次第。
従来のベンチマークはAI Agent能力の説明力を失いつつある。2026年に登場したTerminal-BenchやAgenticSwarmBenchなどの新評価フレームワークが、次世代Agent能力評価基準を定義している。
小米MiMo-V2.5-ProはChatbot Arenaテキスト榜で世界6位・オープンソース1位、Agent専門指数でオープンソース1位、百万レベル長文脈をサポートし、ほぼ全ての国産推論チップに対応。
アリババ千問Qwen3.6シリーズがオープンソース化。27B稠密モデルと35B-A3B MoEモデルを含み、コード能力はClaude 4.5 Opusに迫り、百万トークン長文脈をサポート。
SWE-bench Pro、HLE、MRCR、Arenaデータを総合すると、Claude Opus 4.7はコードと推論で優位、GPT-5.5は長文脈とターミナルワークフローで強く、Gemini 3.1 Proはコストパフォーマンスに優れる。
2026年4月のChatbot ArenaランキングでAnthropicがテキスト上位4枠を独占する一方、Meta muse-sparkや小米MiMo-V2.5-Proなどのオープンソースモデルが差を縮め、オープンソース1位がグローバル6位にランクイン。
Future AGI 開発の MuleRun は完全な AI Agent プラットフォーム。SDK やコミュニティ版ではなく、UI、バックエンド、シミュレーションエンジン、評価、最適化ループ、可観測性を含むフルスタックのオープンソースソリューション。Agent の自己改善、Creator Studio による商用デプロイ、Vibe Training などの革新的機能をサポート。
アリババ HappyHorse 1.0 のグレーテスト期間中に多角的テストを実施。人物接写で優れたパフォーマンスと信頼性の高いリップシンクを確認。一方、大規模シーン構図は最適化の余地あり。
百万トークンコンテキストウィンドウはフラッグシップモデルの標準となったが、実際の可用性には大きな差がある。GPT-5.5は1M検索で74%を達成、Claude Opus 4.7は32.2%のみ。各モデルを正直に评测。
GPT-5.5は定価が最も高いがトークン効率が最高。Gemini 2.5 Proはトークン単価が最低だが同タスクにより多くのトークンが必要。Artificial Analysisの実測データで真のタスクコストを明らかにする。
アリババQwen 3.6-27Bは270億稠密パラメータでTerminal-BenchにおいてClaude 4.5 Opusに並び、18GBメモリで動作。「小型で強力」なモデルの実力を評価。
DeepSeek V4が1.6Tパラメータ、100万トークンコンテキスト、Apache 2.0ライセンスで登場。華為昇騰チップでほぼ完全に訓練された初のモデル。実際の能力を評価する。
OpenAI GPT-5.5、Anthropic Claude Opus 4.7、Google Gemini 2.5 Proが相次いで登場。コーディング、推論、長文コンテキスト、実コストの4次元で比較し、シーン別のおすすめを提示。
推論、コーディング、文章作成、マルチモーダル性能を横断比較する。
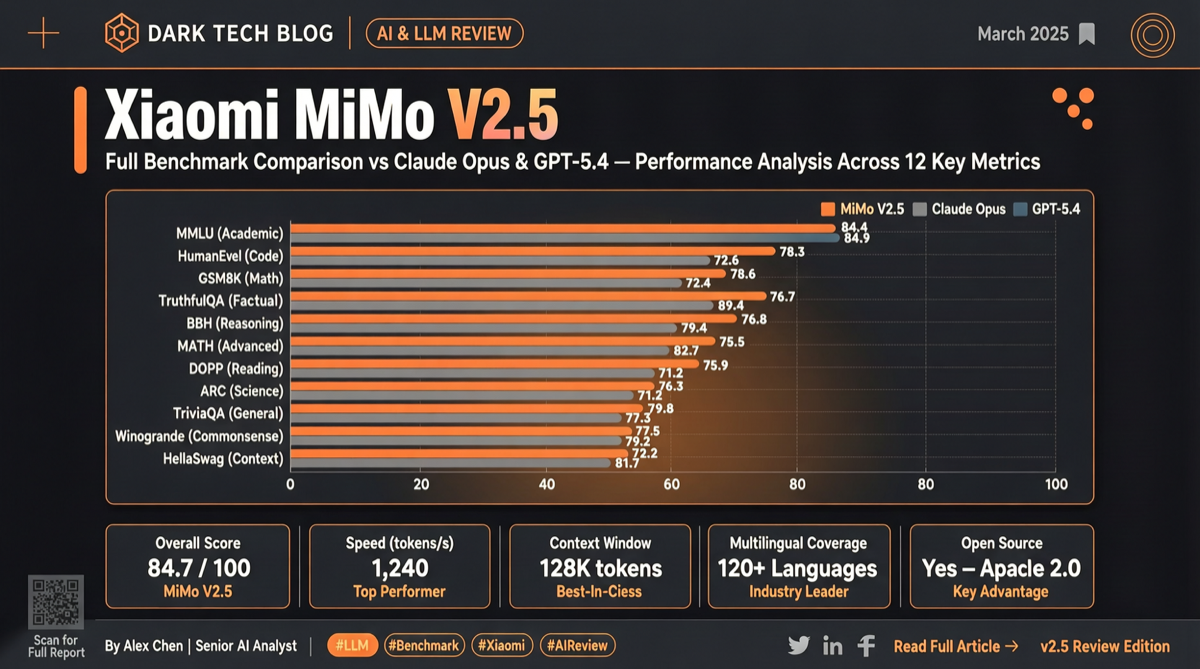
小米 MiMo-V2.5 実測レビュー:4 時間無中断で 54 アプリの macOS 複製版を生成、672 回のツール呼び出しでコンパイラを一から構築。Agent 能力は Claude Opus 4.6 に追平、Token 消費は 40%-60% 削減。