Conclusion
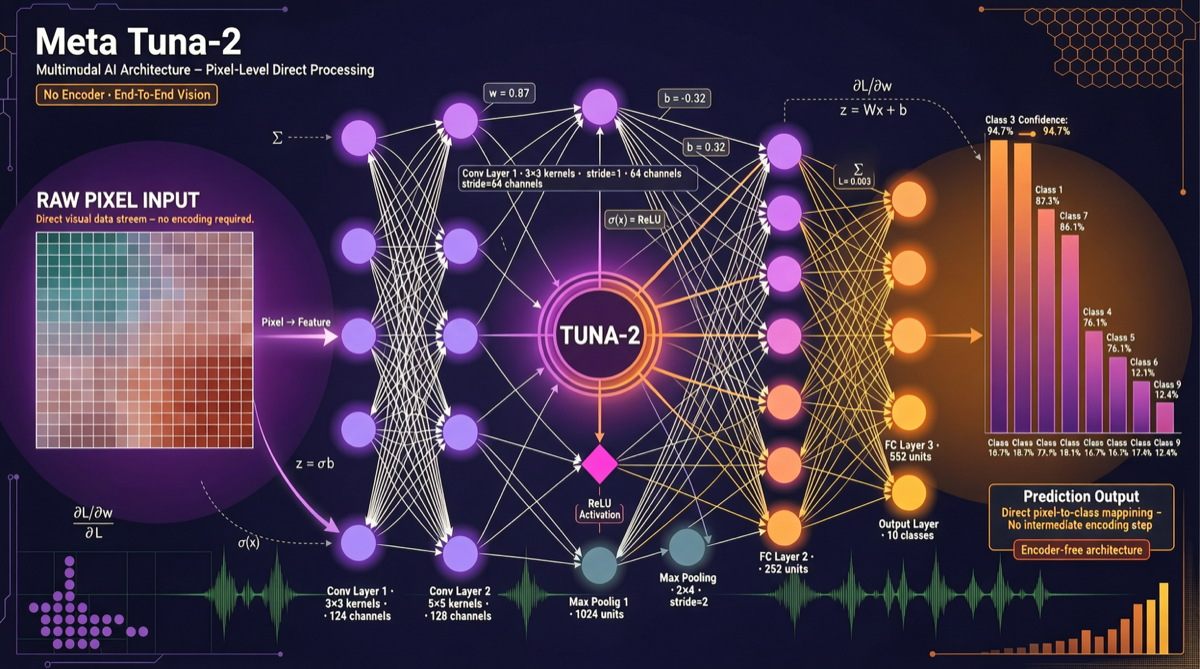
Meta’s Tuna-2 takes a radical technical route: completely abandoning vision encoders and VAEs, processing multimodal tasks directly through pixel embeddings. This surpasses traditional encoder approaches on fine-grained perception tasks while unifying understanding and generation capabilities. For applications requiring high-precision visual understanding, Tuna-2 deserves attention.
Pain Point: The “Encoder Tax” on Traditional Multimodal Models
Current mainstream multimodal models (GPT-4o, Claude, Gemini) almost all follow the same pattern:
Input Image → Vision Encoder (extracts features) → VAE (compressed representation) → LLM (understanding/generation)This approach has two inherent flaws:
- Information Loss: The compression process of encoders and VAEs inevitably loses fine-grained visual information
- Architectural Fragmentation: Visual understanding and image generation require two separate processing pipelines
Tuna-2’s solution: cut out the middle layers, let the model process pixels directly.
Tuna-2 Architecture Deep Dive
Core Architecture
| Component | Traditional Approach | Tuna-2 |
|---|---|---|
| Visual Encoding | CLIP/SigLIP encoders | No encoder |
| Image Compression | VAE latent space | Direct pixel embeddings |
| Understanding + Generation | Separate architectures | Unified architecture |
| Fine-Grained Perception | Encoder bottleneck | Pixel-level precision |
Key Technical Points
-
Pixel Embeddings Replace Encoders
- Images are directly split into patch embeddings
- No pre-trained vision encoder needed
- Retains original pixel-level fine-grained information
-
Unified Understanding and Generation
- Same architecture does both multimodal understanding and image generation
- No need to switch models for different tasks
-
Performance
- Surpasses encoder approaches on fine-grained perception benchmarks
- MoE architecture ensures inference efficiency
- Strong scalability, flexible parameter scale
Horizontal Comparison with Contemporary Multimodal Approaches
| Model | Architecture | Understanding | Generation | Open Source | Specialty |
|---|---|---|---|---|---|
| Tuna-2 (Meta) | Encoder-free + pixel embeddings | ✅ | ✅ | ✅ | Leading fine-grained perception |
| LLaDA2.0-Uni | Diffusion LLM + MoE | ✅ | ✅ | ✅ | 8-step image generation |
| SenseNova U1 | Monolithic multimodal | ✅ | ✅ | ✅ | Unified architecture |
| Nemotron 3 Nano Omni | Multimodal fusion | ✅ | ✅ | ✅ | Video/audio/text |
| GPT-Image-2 | LLM token-by-token | ✅ | ✅ | ❌ | Commercial closed-source |
Why Choose the Encoder-Free Route?
The Historical Baggage of Encoders
Vision encoders (like CLIP) are essentially doing “lossy information compression” — compressing millions of pixels into thousands of dimensions. This is sufficient for classification tasks, but falls short for tasks requiring fine-grained understanding (like: identifying UI element positions, reading small numbers in tables, distinguishing similar objects).
Tuna-2’s approach is similar to how Llama.cpp bypasses cloud APIs for direct local inference: cut out the middleman, go straight to source data.
When to Use Tuna-2
| Scenario | Recommendation | Reason |
|---|---|---|
| UI Screenshot Parsing | ⭐⭐⭐⭐⭐ | Pixel-level precision, accurate position recognition |
| Table OCR + Understanding | ⭐⭐⭐⭐⭐ | Strong fine-grained text recognition |
| Medical Image Analysis | ⭐⭐⭐⭐ | Requires pixel-level precision |
| General Conversation + Image Viewing | ⭐⭐⭐ | Encoder approaches are also sufficient for general tasks |
| Artistic Creation | ⭐⭐ | LLaDA2.0-Uni’s diffusion generation may be more suitable |
Getting Started
Quick Access
- GitHub Repository: Search for Meta Tuna-2 official repository
- Hugging Face Model: Open-source weights already uploaded
- Dependencies: PyTorch + corresponding MoE inference framework
- Hardware Requirements: Depends on parameter count, recommend at least 24GB VRAM
Integration with Existing Toolchains
# Typical integration path
Tuna-2 Model
↓ (via OpenAI-compatible API)
OpenClaw / Hermes Agent / LangChain
↓
Your Business ApplicationAs a unified multimodal understanding + generation model, it can serve as:
- Visual perception module for agents
- Document/table understanding engine
- Image generation backend
Landscape Assessment
Tuna-2 represents one branch direction for multimodal AI: end-to-end pixel processing. Alongside LLaDA2.0-Uni’s diffusion route and SenseNova U1’s monolithic architecture, it forms a three-way competition. In the short term, traditional encoder approaches remain mainstream; but in the medium-to-long term, if the pixel embedding route proves scalable, it could become the next-generation multimodal foundational architecture.