Заключение
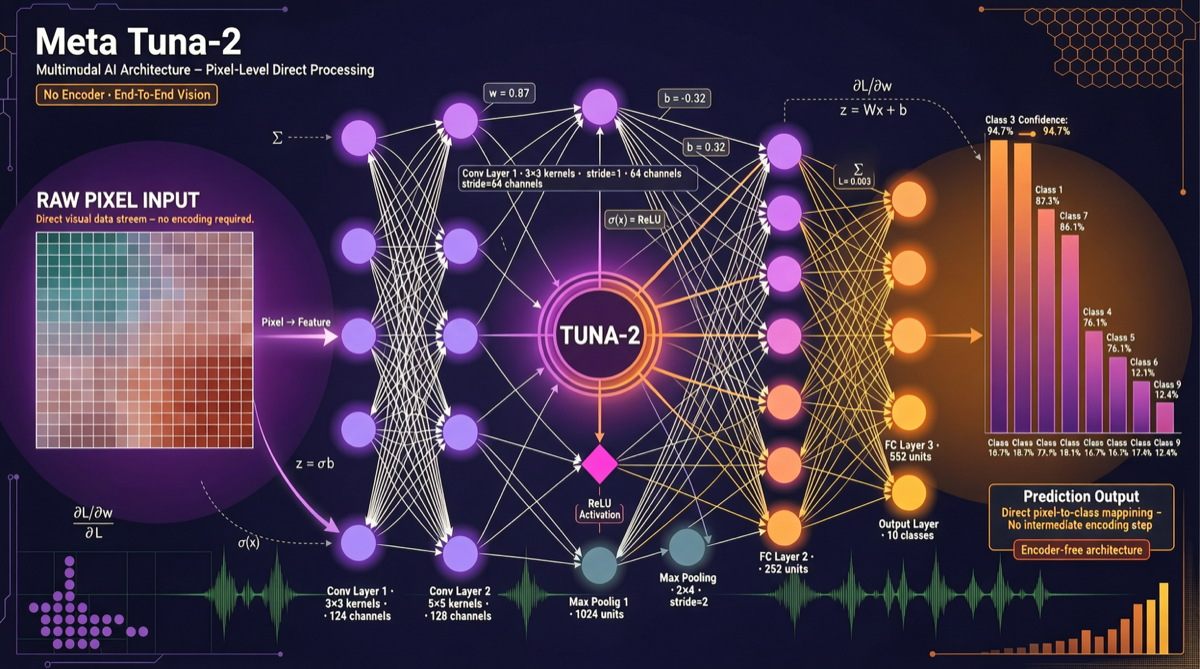
Tuna-2 от Meta выбирает радикальный технический путь: полный отказ от визуальных энкодеров и VAE, обработка мультимодальных задач напрямую через пиксельные эмбеддинги. Это превосходит традиционные подходы с энкодерами в задачах точного восприятия, одновременно объединяя возможности понимания и генерации. Для приложений, требующих высокоточного визуального понимания, Tuna-2 заслуживает внимания.
Болевая точка: «Налог на энкодер» у традиционных мультимодальных моделей
Текущие мейнстримные мультимодальные модели (GPT-4o, Claude, Gemini) практически все следуют одному паттерну:
Входное изображение → Визуальный энкодер (извлечение признаков) → VAE (сжатое представление) → LLM (понимание/генерация)У этого подхода есть два врождённых缺陷а:
- Потеря информации: Процесс сжатия энкодерами и VAE неизбежно теряет мелкозернистую визуальную информацию
- Архитектурная фрагментация: Визуальное понимание и генерация изображений требуют двух отдельных конвейеров обработки
Решение Tuna-2: убрать промежуточные слои, позволить модели обрабатывать пиксели напрямую.
Детали архитектуры Tuna-2
Основная архитектура
| Компонент | Традиционный подход | Tuna-2 |
|---|---|---|
| Визуальное кодирование | Энкодеры CLIP/SigLIP | Без энкодера |
| Сжатие изображений | Латентное пространство VAE | Прямые пиксельные эмбеддинги |
| Понимание + Генерация | Раздельные архитектуры | Единая архитектура |
| Точное восприятие | Bottleneck энкодера | Точность на уровне пикселей |
Ключевые технические моменты
-
Пиксельные эмбеддинги заменяют энкодеры
- Изображения напрямую разбиваются на patch embeddings
- Предобученный визуальный энкодер не нужен
- Сохраняется исходная мелкозернистая информация на уровне пикселей
-
Объединённые понимание и генерация
- Одна и та же архитектура выполняет и мультимодальное понимание, и генерацию изображений
- Не нужно переключать модели для разных задач
-
Производительность
- Превосходит подходы с энкодерами в бенчмарках точного восприятия
- Архитектура MoE обеспечивает эффективность вывода
- Высокая масштабируемость, гибкий масштаб параметров
Горизонтальное сравнение с современными мультимодальными подходами
| Модель | Архитектура | Понимание | Генерация | Open Source | Специализация |
|---|---|---|---|---|---|
| Tuna-2 (Meta) | Без энкодера + пиксельные эмбеддинги | ✅ | ✅ | ✅ | Лидер в точном восприятии |
| LLaDA2.0-Uni | Диффузионный LLM + MoE | ✅ | ✅ | ✅ | Генерация изображений за 8 шагов |
| SenseNova U1 | Монолитная мультимодальная | ✅ | ✅ | ✅ | Единая архитектура |
| Nemotron 3 Nano Omni | Мультимодальная фузия | ✅ | ✅ | ✅ | Видео/аудио/текст |
| GPT-Image-2 | LLM токен за токеном | ✅ | ✅ | ❌ | Коммерческий закрытый |
Почему выбрать путь без энкодеров?
Исторический багаж энкодеров
Визуальные энкодеры (такие как CLIP) по сути занимаются «сжатием информации с потерями» — сжимают миллионы пикселей в тысячи измерений. Это достаточно для задач классификации, но недостаточно для задач, требующих точного понимания (например: определение позиций элементов UI, чтение мелких цифр в таблицах, различение похожих объектов).
Подход Tuna-2 похож на то, как Llama.cpp обходит облачные API для прямого локального вывода: убрать посредника, идти напрямую к исходным данным.
Когда использовать Tuna-2
| Сценарий | Рекомендация | Причина |
|---|---|---|
| Парсинг скриншотов UI | ⭐⭐⭐⭐⭐ | Точность на уровне пикселей, точное распознавание позиций |
| OCR таблиц + понимание | ⭐⭐⭐⭐⭐ | Сильное точное распознавание текста |
| Анализ медицинских изображений | ⭐⭐⭐⭐ | Требуется точность на уровне пикселей |
| Общий диалог + просмотр изображений | ⭐⭐⭐ | Подходы с энкодерами тоже достаточны для общих задач |
| Художественное творчество | ⭐⭐ | Диффузионная генерация LLaDA2.0-Uni может быть более подходящей |
Начало работы
Быстрый доступ
- Репозиторий GitHub: Найдите официальный репозиторий Meta Tuna-2
- Модель Hugging Face: Открытые веса уже загружены
- Зависимости: PyTorch + соответствующий фреймворк вывода MoE
- Требования к оборудованию: Зависит от количества параметров, рекомендуется минимум 24 ГБ VRAM
Интеграция с существующими цепочками инструментов
# Типичный путь интеграции
Модель Tuna-2
↓ (через API, совместимый с OpenAI)
OpenClaw / Hermes Agent / LangChain
↓
Ваше бизнес-приложениеКак единая модель мультимодального понимания + генерации, она может служить:
- Модулем визуального восприятия для агентов
- Движком понимания документов/таблиц
- Бэкендом генерации изображений
Оценка ландшафта
Tuna-2 представляет одно из направлений развития мультимодального ИИ: сквозная обработка пикселей. Наряду с диффузионным маршрутом LLaDA2.0-Uni и монолитной архитектурой SenseNova U1 она формирует тройное соревнование. В краткосрочной перспективе традиционные подходы с энкодерами остаются мейнстримом; но в среднесрочной и долгосрочной перспективе, если маршрут пиксельных эмбеддингов докажет масштабируемость, он может стать архитектурой следующего поколения для мультимодальных базовых моделей.