結論
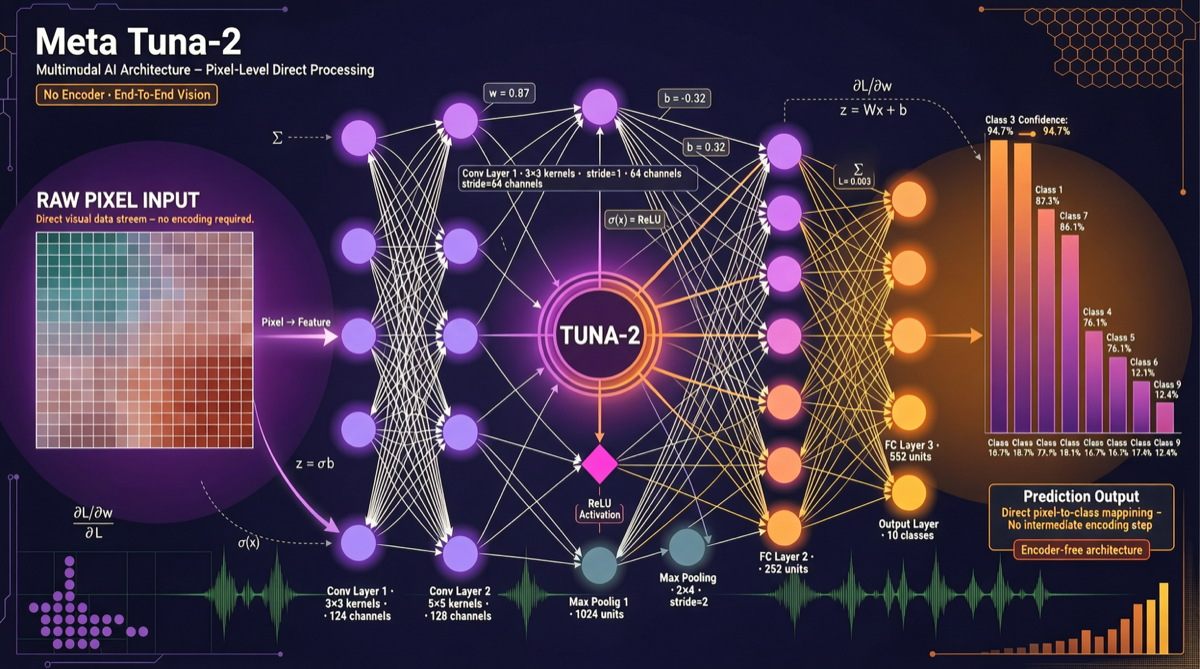
MetaのTuna-2は過激な技術路線を採用した。視覚エンコーダーとVAEを完全に捨て、ピクセル埋め込みで直接マルチモーダルタスクを処理する。これは細粒度知覚タスクで従来のエンコーダー方式を上回り、理解と生成の能力を統一する。高精度の視覚理解が必要なアプリケーションにとって、Tuna-2は注目する価値がある。
痛点:伝統的マルチモーダルモデルの「エンコーダー税」
現在の主流マルチモーダルモデル(GPT-4o、Claude、Gemini)はほぼ同じパターンに従っている:
入力画像 → 視覚エンコーダー(特徴抽出)→ VAE(圧縮表現)→ LLM(理解/生成)このアプローチには2つの固有の欠陥がある:
- 情報の損失:エンコーダーとVAEの圧縮過程で必然的に細粒度の視覚情報が失われる
- アーキテクチャの分断:視覚理解と画像生成に2つの別々の処理パイプラインが必要
Tuna-2の解決策:中間層を切り捨て、モデルに直接ピクセルを処理させる。
Tuna-2 アーキテクチャ詳細
コアアーキテクチャ
| コンポーネント | 従来アプローチ | Tuna-2 |
|---|---|---|
| 視覚エンコーディング | CLIP/SigLIPエンコーダー | エンコーダーなし |
| 画像圧縮 | VAE潜在空間 | 直接ピクセル埋め込み |
| 理解 + 生成 | 分離アーキテクチャ | 統一アーキテクチャ |
| 細粒度知覚 | エンコーダーボトルネック | ピクセルレベルの精度 |
主要技術ポイント
-
ピクセル埋め込みがエンコーダーを代替
- 画像を直接patch embeddingsに分割
- 事前学習済み視覚エンコーダーは不要
- 元のピクセルレベルの細粒度情報を保持
-
理解と生成の統一
- 同じアーキテクチャでマルチモーダル理解と画像生成の両方を実行
- タスクごとにモデルを切り替える必要なし
-
パフォーマンス
- 細粒度知覚ベンチマークでエンコーダー方式を上回る
- MoEアーキテクチャが推論効率を確保
- 拡張性が強く、パラメータ規模が柔軟
同時代のマルチモーダル方式との横断比較
| モデル | アーキテクチャ | 理解 | 生成 | オープンソース | 特色 |
|---|---|---|---|---|---|
| Tuna-2 (Meta) | エンコーダーフリー+ピクセル埋め込み | ✅ | ✅ | ✅ | 細粒度知覚でリード |
| LLaDA2.0-Uni | 拡散LLM+MoE | ✅ | ✅ | ✅ | 8ステップ画像生成 |
| SenseNova U1 | モノリシックマルチモーダル | ✅ | ✅ | ✅ | 統一アーキテクチャ |
| Nemotron 3 Nano Omni | マルチモーダル融合 | ✅ | ✅ | ✅ | 動画/音声/テキスト |
| GPT-Image-2 | LLMトークン逐次 | ✅ | ✅ | ❌ | 商用クローズド |
なぜエンコーダーフリー路線を選ぶのか?
エンコーダーの歴史的荷物
視覚エンコーダー(CLIPなど)は本質的に「情報の有損圧縮」を行っている——数百万ピクセルの画像を数千次元のベクトルに圧縮する。このプロセスは分類タスクには十分だが、細粒度の理解が必要なタスク(UI要素の位置識別、表の中の小さな数字の読み取り、類似物体の区別など)には足りない。
Tuna-2のアプローチはLlama.cppがクラウドAPIを迂回して直接ローカル推論を行うのと似ている:仲介者を排除、ソースデータに直行。
Tuna-2を使うべき場面
| シナリオ | 推奨度 | 理由 |
|---|---|---|
| UIスクリーンショット解析 | ⭐⭐⭐⭐⭐ | ピクセルレベルの精度、位置認識が正確 |
| 表OCR+理解 | ⭐⭐⭐⭐⭐ | 細粒度文字認識が強い |
| 医療画像解析 | ⭐⭐⭐⭐ | ピクセルレベルの精度が必要 |
| 汎用対話+画像閲覧 | ⭐⭐⭐ | 汎用タスクはエンコーダー方式でも十分 |
| アート制作 | ⭐⭐ | LLaDA2.0-Uniの拡散生成がより適している可能性 |
はじめに
クイックアクセス
- GitHubリポジトリ:Meta Tuna-2公式リポジトリを検索
- Hugging Faceモデル:オープンソース重みはすでにアップロード済み
- 依存関係:PyTorch + 対応するMoE推論フレームワーク
- ハードウェア要件:パラメータ数によるが、最低24GB VRAMを推奨
既存ツールチェーンとの統合
# 典型的な統合パス
Tuna-2 モデル
↓ (OpenAI互換API経由)
OpenClaw / Hermes Agent / LangChain
↓
あなたのビジネスアプリケーションマルチモーダル理解+生成の統一モデルとして、以下として機能可能:
- エージェントの視覚知覚モジュール
- 文書/表理解エンジン
- 画像生成バックエンド
市場分析
Tuna-2はマルチモーダルAIの一つの分岐方向を代表する:エンドツーエンドのピクセル処理。LLaDA2.0-Uniの拡散路線、SenseNova U1のモノリシックアーキテクチャと並んで三つ巴の競争を形成。短期的には従来のエンコーダー方式が主流だが、中長期的にピクセル埋め込み路線がスケーラビリティを証明できれば、次世代マルチモーダル基盤アーキテクチャになる可能性がある。