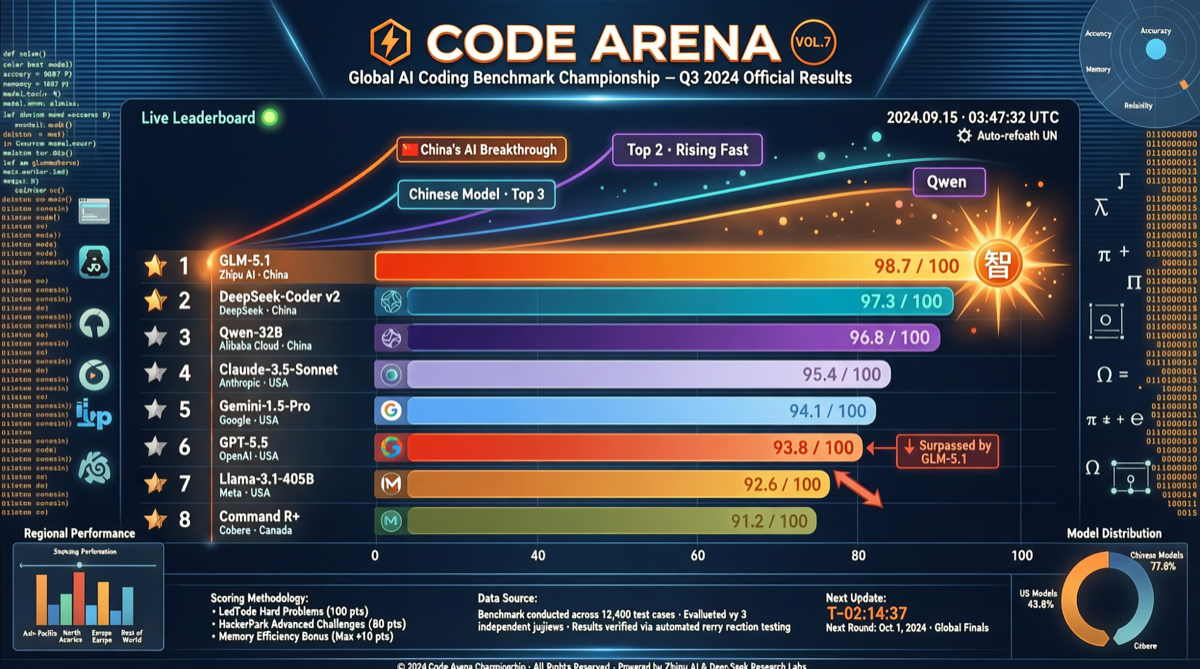
Core Data
The latest Code Arena rankings reveal a significant shift in the coding landscape. Among the 46 agentic coding models evaluated, Chinese models occupy the most prominent positions:
| Rank | Model | Code Arena Score |
|---|---|---|
| 1 | GLM-5.1 | ~1535+ |
| 2 | Kimi K2.6 | ~1520+ |
| 3 | MiMo-V2.5-Pro | ~1510+ |
| … | … | … |
| 5 | GLM-5.1 (confirmed) | 1535 |
| 9 | GPT-5.5 High | 1500 |
Key fact: GLM-5.1’s score (1535) in Code Arena has clearly surpassed GPT-5.5 High (1500), performing particularly well in agentic coding and web development tasks.
The Three-Way Chinese Coding Power Structure
Combining data from multiple dimensions, Chinese models have formed a “three-strong-plus-challengers” pattern in coding:
GLM-5.1: Zhipu AI’s latest model, standing out in Code Arena. Previously, Zhipu publicly released a blog post reviewing the Scaling Pain encountered during GLM-5 training, candidly disclosing debugging processes for garbled outputs, repetition, and rare character issues — a level of transparency rare in the industry. GLM-5.1 is the version after these fixes, with significantly improved coding capability.
Kimi K2.6: Moonshot AI’s flagship model, topping open-source models on SWE-Bench Pro with a score of 58.6, surpassing GPT-5.4 and Claude 4.6. K2.6 uses an Agent Swarm architecture, supporting 300 parallel sub-agents and 4000-step deep reasoning, redefining the ceiling of Agent scale.
MiMo-V2.5-Pro: Developed under the leadership of Luo Fuli, head of Xiaomi’s large model team. In a recent 3.5-hour in-depth interview, Luo revealed Xiaomi’s technical direction after the Pre-train gap disappeared — pivoting toward Agent RL. MiMo’s rapid rise validates the effectiveness of this approach.
The Surprise Underperformer: DeepSeek V4 Pro
Most dramatically, DeepSeek V4 Pro’s performance was unexpected. Once regarded as the king of Chinese models, V4 Pro surprisingly ranks at the bottom in this coding leaderboard. This may reflect several trends:
- V4 Pro’s optimization leans toward general reasoning, putting it at a disadvantage in agentic coding-specific scenarios
- Competitor iteration has accelerated — the coding-specific optimizations of GLM-5.1 and K2.6 show significant results
- DeepSeek’s API cache pricing strategy lowered usage costs but did not translate into improved coding capability
Industry Significance
This ranking shift sends several important signals:
- Chinese models are no longer catching up in coding — GLM-5.1 surpassing GPT-5.5 High is a landmark event
- A culture of transparent post-mortems is forming: Zhipu’s public Scaling Pain disclosure, Anthropic’s quality decline post-mortem, and OpenAI’s “Goblin” output incident review — large model companies are increasing engineering transparency
- Agent architecture is becoming the differentiator: K2.6’s 300 parallel sub-agents and GLM-5.1’s self-evaluation (building a complete Three.js racing game for self-assessment) show that Agent-native architecture is replacing pure model scale competition
For developers and enterprises, this means that in agentic coding scenarios, Chinese models have moved from “usable” to “good” — and in some cases, becoming the first choice.