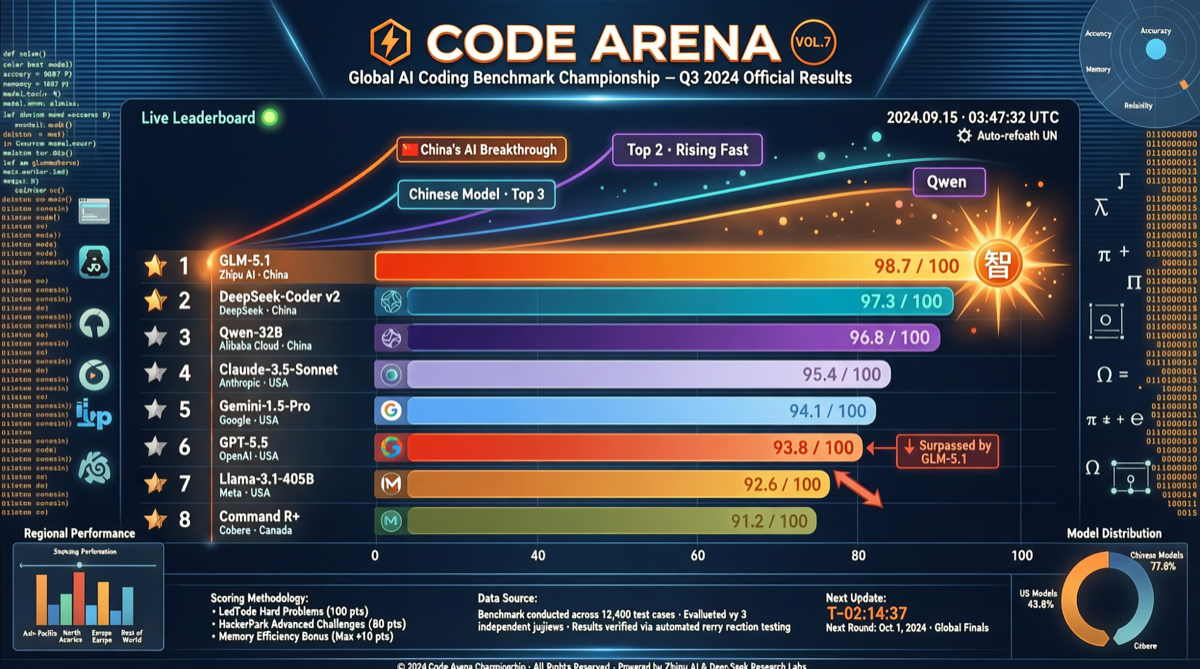
Ключевые данные
Последний рейтинг Code Arena выявил значительный сдвиг в ландшафте кодирования. Среди 46 оцениваемых моделей агентного кодирования китайские модели занимают самые заметные позиции:
| Ранг | Модель | Код Code Arena |
|---|---|---|
| 1 | GLM-5.1 | ~1535+ |
| 2 | Kimi K2.6 | ~1520+ |
| 3 | MiMo-V2.5-Pro | ~1510+ |
| … | … | … |
| 5 | GLM-5.1 (подтверждено) | 1535 |
| 9 | GPT-5.5 High | 1500 |
Ключевой факт: Результат GLM-5.1 в Code Arena (1535) явно превзошёл GPT-5.5 High (1500), показав особенно высокие результаты в задачах агентного кодирования и веб-разработки.
Структура трёх китайских лидеров в кодировании
Объединяя данные из нескольких источников, китайские модели сформировали структуру «три лидера плюс преследователи» в кодировании:
GLM-5.1: Последняя модель Zhipu AI, выделяющаяся в Code Arena. Ранее Zhipu публично опубликовала блог-пост с анализом проблем масштабирования, возникших при обучении GLM-5, откровенно раскрыв процесс отладки проблем с некорректным выводом, повторениями и редкими символами — уровень прозрачности, редкий в индустрии. GLM-5.1 — это версия после исправления этих проблем, со значительно улучшенной способностью к кодированию.
Kimi K2.6: Флагманская модель Moonshot AI, возглавившая открытые модели в SWE-Bench Pro с результатом 58,6, опередив GPT-5.4 и Claude 4.6. K2.6 использует архитектуру Agent Swarm, поддерживающую 300 параллельных субагентов и 4000 шагов глубокого рассуждения, переопределяя потолок масштаба агентов.
MiMo-V2.5-Pro: Модель, разработанная под руководством Ло Фули, руководителя команды больших моделей Xiaomi. В недавнем 3,5-часовом глубинном интервью Ло раскрыла техническое направление Xiaomi после исчезновения разрыва в предварительном обучении — переход к агентному обучению с подкреплением (Agent RL). Стремительный взлёт MiMo подтверждает эффективность этого подхода.
Неожиданный аутсайдер: DeepSeek V4 Pro
Наиболее драматичным стало выступление DeepSeek V4 Pro. Когда-то считавшаяся королём китайских моделей, V4 Pro неожиданно оказалась в конце этого рейтинга по кодированию. Это может отражать несколько тенденций:
- Оптимизация V4 Pro смещена в сторону общего рассуждения, что ставит её в невыгодное положение в специализированных сценариях агентного кодирования
- Ускорение итераций конкурентов — специализированные оптимизации кодирования GLM-5.1 и K2.6 показывают значительные результаты
- Ценовая стратегия кэширования API DeepSeek снизила стоимость использования, но не привела к улучшению способности к кодированию
Значение для индустрии
Этот сдвиг в рейтинге передаёт несколько важных сигналов:
- Китайские модели больше не догоняют в кодировании — обход GLM-5.1 модели GPT-5.5 High является знаковым событием
- Формируется культура прозрачных разборов: публичное раскрытие проблем масштабирования Zhipu, разбор снижения качества Anthropic и обзор инцидента с выводом «гоблина» OpenAI — компании больших моделей повышают инженерную прозрачность
- Архитектура агентов становится ключевым diferenciрующим фактором: 300 параллельных субагентов K2.6 и самооценка GLM-5.1 (создание полноценной гоночной игры на Three.js для самопроверки) показывают, что агентно-ориентированная архитектура заменяет чистую гонку масштабов моделей
Для разработчиков и предприятий это означает, что в сценариях агентного кодирования китайские модели перешли от «пригодных» к «хорошим» — а в некоторых случаях становятся первым выбором.