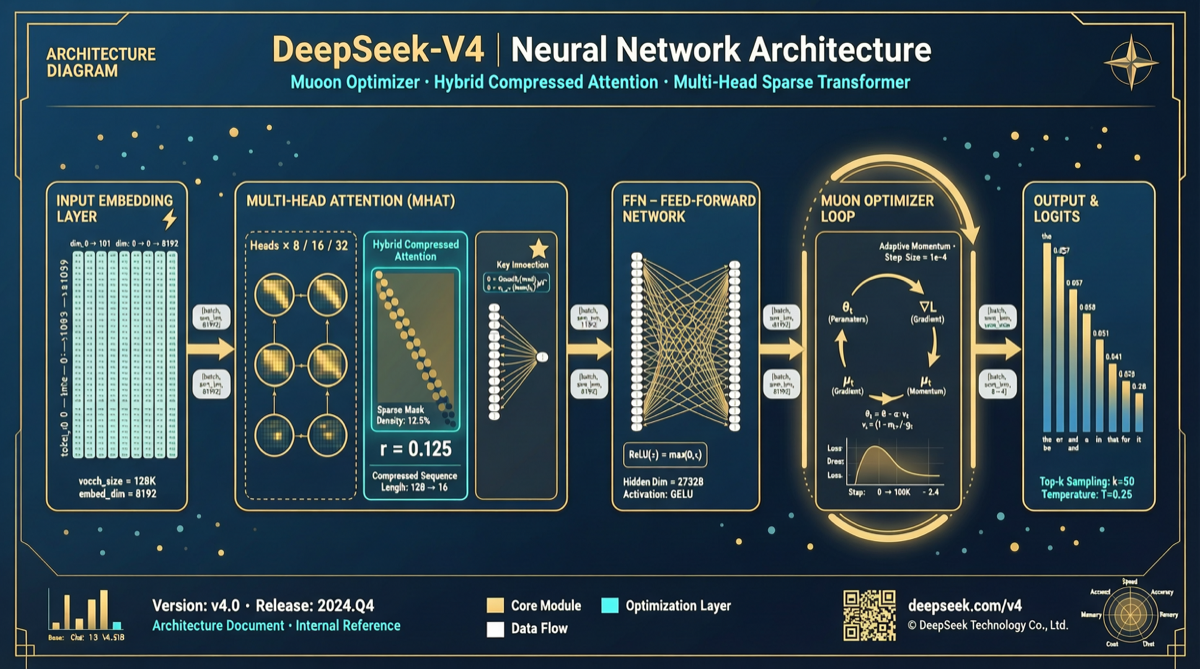
Core Technical Findings
DeepSeek-V4’s technical report finally reveals why this model achieves flagship-level performance while maintaining low costs. Two technical innovations stand out:
Innovation 1: Hybrid Compressed Attention System
The Pain Point: Standard Attention’s Computational Bottleneck
Standard Self-Attention has O(n² × d) complexity. When sequence length expands from 4K to 128K, computation grows 1024x.
DeepSeek’s Approach: Hybrid Strategy
Hybrid Compressed Attention:
┌──────────────────────────────────────┐
│ Short-range → Standard Attention │
│ Mid-range → Sliding Window │
│ Long-range → Compressed/Linear │
│ Global → Compressed Token Summary│
└──────────────────────────────────────┘| Dimension | Standard Attention | Hybrid Compressed | Improvement |
|---|---|---|---|
| Complexity | O(n²) | O(n × log n) | ~10-100x |
| Memory | Full KV Cache | Layered Compression | 60-80% reduction |
Innovation 2: Muon Optimizer
Background: Adam’s Limitations
Adam has been the default optimizer, but at hundred-billion parameter scale, problems emerge:
- Large memory overhead (maintains two momentum states per parameter)
- Instability during fine-tuning
- Hyperparameter sensitivity
Muon’s Core Idea
Adam: Element-wise adaptive learning rate
Muon: Matrix-structured optimization direction| Optimization Dimension | Adam | Muon |
|---|---|---|
| Training Speed | Baseline | Faster |
| Training Stability | Medium | Higher |
| Hyperparameter Sensitivity | High | Low |
Community estimates suggest 15-25% speed improvement — meaning thousands of GPU-hours saved.
Innovation 3: Improved Inter-Layer Connections
DeepSeek-V4 introduces more complex connection patterns allowing information to “jump” between layers, directly improving complex multi-step reasoning capability.
Practical Significance for Developers
1. API Usage
- Long context tasks: Hybrid compression means performance won’t degrade sharply at 128K context
- Complex reasoning: Improved inter-layer connections make V4 stronger at multi-step reasoning
2. Open Source Deployment
- Lower memory requirements: KV Cache compression reduces inference memory pressure
- Cheaper GPUs: 60-80% memory savings means models that needed 8 A100s may now need only 4
Summary
DeepSeek-V4’s innovation route is architectural innovation, not scale competition. For teams with limited budgets needing flagship performance, this represents a more sustainable development direction.