コア技術発見
DeepSeek-V4技術レポートは、低コストでフラグシップ級パフォーマンスを達成する理由を明らかにしました。
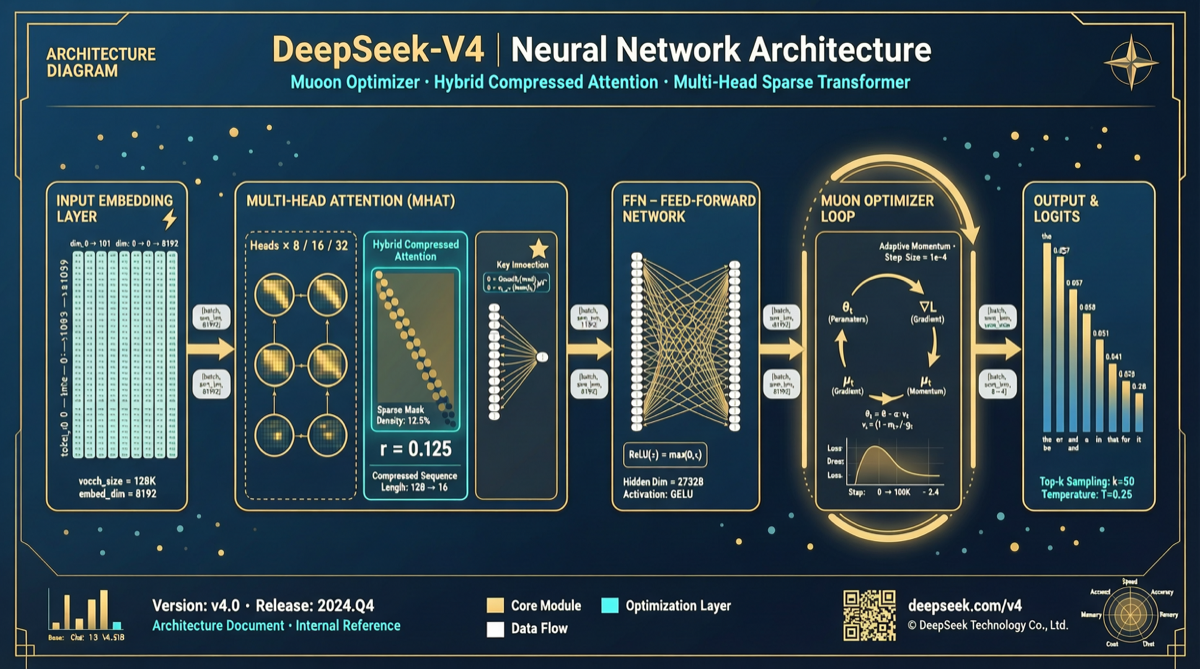
イノベーション1:混合圧縮Attentionシステム
標準Self-AttentionはO(n²)の計算复杂度。DeepSeekのハイブリッド戦略:
| 次元 | 標準Attention | 混合圧縮 | 改善 |
|---|---|---|---|
| 計算复杂度 | O(n²) | O(n × log n) | ~10-100倍 |
| メモリ使用量 | 全量KVキャッシュ | 階層圧縮 | 60-80%削減 |
イノベーション2:Muon最適化器
Adam: 要素単位の適応学習率
Muon: 行列構造の最適化方向| 最適化次元 | Adam | Muon |
|---|---|---|
| トレーニング速度 | 基準 | 高速 |
| 安定性 | 中 | 高い |
| ハイパーパラメータ敏感度 | 高い | 低い |
コミュニティ推定で15-25%の速度向上 — 数千GPU時間の節約。
まとめ
DeepSeek-V4のイノベーションルートはアーキテクチャレベルでの革新、スケール競争ではない。予算有限ながらフラグシップ級パフォーマンスが必要なチームにとって、より持続可能な開発方向を示しています。