Core Takeaway
World Models are emerging as the next critical infrastructure following large language models.
Over the past two years, the AI research focus has been shifting from “pure text generation” to “perception, understanding, and interaction with the physical world.” But the world model track faces a serious engineering problem: video generation, 3D reconstruction, and embodied control tasks each operate in isolation, with fragmented interfaces, split reasoning flows, and tightly coupled systems. OpenWorldLib aims to end this fragmentation with a standardized framework.
What’s Happening
The DCAI team at Peking University, together with Kuaishou’s Kling team, Shanghai Algorithm Innovation Institute, Zhongguancun Institute, and other institutions, has officially open-sourced OpenWorldLib — a unified, standardized, and extensible advanced world model inference framework.
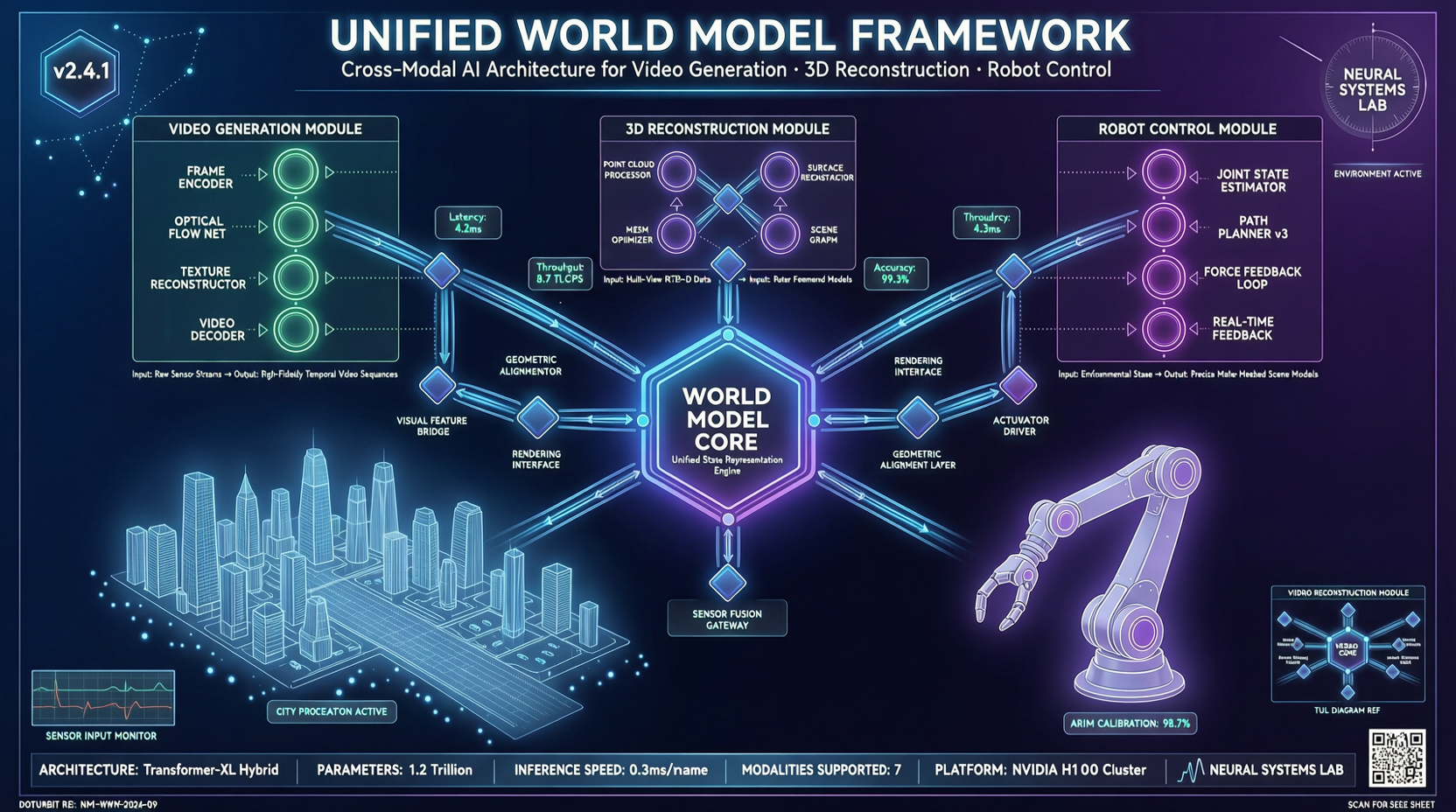
The framework provides a clear definition of world models: a model or framework centered on perception, equipped with interaction capabilities and long-term memory, used to understand and predict complex worlds. Under this definition, OpenWorldLib integrates multimodal understanding, generation, and action capabilities, building a standardized interface system for the open-source community.
Technical Details: Architecture Breakdown
OpenWorldLib’s core design philosophy is “unified interfaces + modular assembly”, manifested in three layers:
1. Pipeline (Core Orchestration Layer)
As the system’s central hub, the Pipeline connects functional components to achieve complete inference from input to output. It supports two execution modes:
- Single-turn inference (forward): For video generation, standard reasoning scenarios
- Multi-turn interaction (stream): Automatically calls the Memory module to maintain historical state, suitable for interactive video editing or embodied control tasks requiring long-term dependencies
2. Operator Mechanism (Input Standardization Layer)
Acts as a bridge between raw input and core execution modules. World models need to process diverse inputs — text, images, continuous control actions, audio signals. Operators handle two things:
- Validation: Ensures input format, shape, and type meet downstream model requirements
- Preprocessing: Converts raw signals into standardized tensors — image resizing, text tokenization, action space normalization
3. Four Core Modules
- Synthesis: Handles video generation, image generation, and other creative tasks
- Reasoning: Fuses text, images, and other multimodal information for spatial relationship analysis and complex semantic reasoning
- Representation: Unified modeling from visual input to structured 3D representation, supporting 3D scene reconstruction
- Memory: Provides context reading and updating for multi-turn interactions, maintaining state consistency
Experimental Results
The framework has been validated across multiple typical tasks:
- Interactive Video Generation: Compared to earlier methods (Matrix-Game series), newer models significantly improve visual quality and physical consistency in long-sequence generation, reducing color drift and structural distortion
- Multimodal Reasoning: The Reasoning module outputs interpretable reasoning results, giving models both “generative ability” and “understanding/decision-making ability”
- 3D Scene Reconstruction: The Representation module enables multi-view reconstruction and simulation verification, though geometric inconsistency issues persist under large viewpoint changes
- VLA (Vision-Language-Action) Control: Translates natural language instructions and visual observations into action sequences, achieving a closed loop from “understanding” to “acting”
Industry Significance
OpenWorldLib’s value extends beyond being just another open-source project — it addresses a critical industry pain point:
Researchers no longer need to build separate inference logic and engineering environments for each task type.
Before this, teams working on video generation and those working on embodied control might have been using completely different interface specifications and engineering architectures, making cross-task comparison and model reuse extremely difficult. OpenWorldLib’s unified module templates (Operator / Reasoning / Synthesis / Representation / Memory) allow developers to integrate new models by simply implementing the corresponding interfaces, without modifying the overall architecture.
This is similar to the role of Hugging Face Transformers in the LLM ecosystem — standardized interfaces lower the research barrier and promote ecosystem synergy.
Background
OpenWorldLib is led by the DCAI team at Peking University. The team focuses on foundational innovation and system deployment in AI models and data, and has previously open-sourced several high-quality projects:
- DataFlow: Data preparation system
- DataFlex: Dynamic model training system
- One-Eval: Automatic evaluation agent
DCAI main repository: https://github.com/OpenDCAI
For researchers and developers interested in world models, embodied AI, or multimodal AI, OpenWorldLib provides a ready-to-use, extensible infrastructure worth watching.