長文脈推論のボトルネックは完全にアテンションメカニズムにある。KVキャッシュは文脈に比例して成長し、アテンション計算は二乗で成長する——100万トークンの入力でprefillを実行すれば、GPUファンが唸りを上げる。
既存の解決策は、ネイティブスパース訓練(スパースアテンションモデルをゼロから訓練、コスト极高)か、ヒューリスティックなトークン排除(推論時に一部のトークンを捨てる、精度は運次第)のどちらか。RTPurbo(arXiv:2605.16928、周彦柯他、2026年5月16日)は:どちらも必要ないと言う。
3つの観察
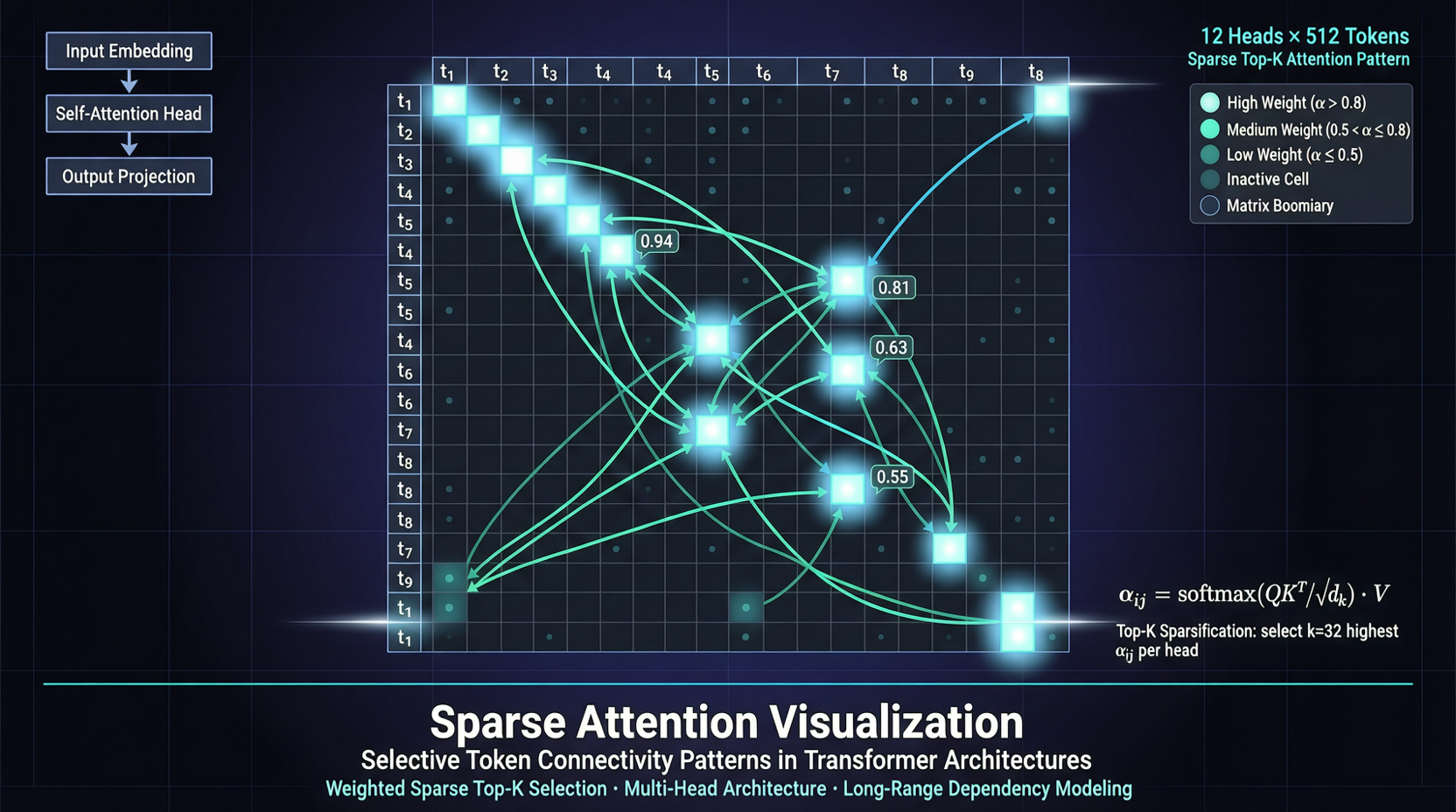
第一、アテンションヘッドのごく一部だけが完全な長文脈処理を本当に必要としている。 大部分のヘッドは長距離検索で単に無効だ——それらのアテンションパターンは短く局所的。実際に検索を行っているのは少数の「retrieval heads」だけ。
第二、長距離検索は主に低次元部分空間によって支配される。 論文は16次元のトークンインデクサーで関連トークンの効率的な検索が可能であることを証明している。16次元、128次元でも完全次元でもない。
第三、有用なトークンバジェットはクエリに強く依存する。 いくつかの問題は少数の重要トークンだけが必要で、他は大きなセクションをスキャンする必要がある。だから固定的top-kスパース化よりも動的top-p選択が適切——モデル自身に見る量を決定させる。
RTPurboのアプローチ
これらの観察に基づき、RTPurboの手法:retrieval headsのみに完全なKVキャッシュを保持し、他のすべてのヘッドには軽量なトークンインデクサーを使用してスパースアテンションを行う。
重要なブレークスルー:この変換には数百ステップの訓練しか必要ない。ゼロからのスパース事前訓練も、データパイプラインの再構築も不要。訓練済みのフルアテンションモデルを取って、数百ステップ微調整するだけで完了。
結果
長文脈ベンチマークと推論タスクでほぼ無損失の精度。1Mコンテキストで9.36倍のprefill高速化、2.01倍のdecode高速化。
主要ソース:
- arXiv:2605.16928, Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps, Yanke Zhou et al., 2026-05-16