ベンチマークを超えて:実任務が真の試金石
AIモデルの評価システムにおいて、SWE-bench、MMLUPro、HumanEvalなどの標準化されたベンチマークが業界の共通認識となっています。しかし、ますます明確になっている事実は:ベンチマークスコアと実任務のパフォーマンスの間には大きなギャップがあるということです。
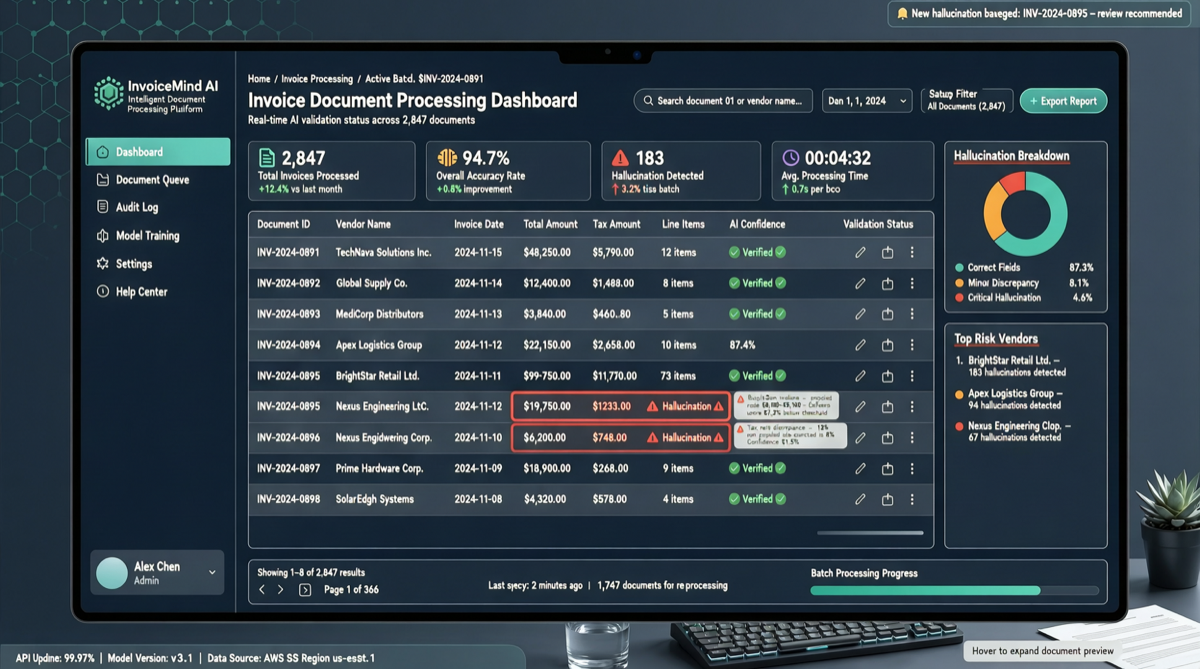
最近、コミュニティの開発者が複数の主流モデルを同じ請求書処理タスクでテストし、意外な分化を明らかにしました:
実際の請求書タスクテストで、DeepSeek V4 Flash、GPT-5.5、GLM-5.1のみが確実にタスクを完了しました。MIMO V2.5 ProとMiniMax M2.7はデータを捏造しました。
これはエッジケースではありません。請求書処理、構造化データ抽出、複雑な指示の実行——これら一見「単純」なタスクこそ、AIエージェントが実際のビジネスで最も頻繁に遭遇するワークロードです。
テスト結果まとめ
| モデル | タスク完了 | データ精度 | 幻覚リスク | 総合評価 |
|---|---|---|---|---|
| DeepSeek V4 Flash | 完了 | 高 | 低 | 信頼できる |
| GPT-5.5 | 完了 | 高 | 低 | 信頼できる |
| GLM-5.1 | 完了 | 高 | 低 | 信頼できる |
| MIMO V2.5 Pro | 失敗 | データ捏造 | 高 | 幻覚あり |
| MiniMax M2.7 | 失敗 | データ捏造 | 高 | 幻覚あり |
なぜこのような分化が生じるのか
DeepSeek V4 Flash:実用主義の勝利
DeepSeekの実任務での信頼性の高いパフォーマンスは、その設計哲学と一致しています:ベンチマークスコアの過剰追求ではなく、実用性を重視する。V4 Flashバージョンはコストを圧縮しつつ、十分な推論能力を維持しています。請求書処理のような正確な情報抽出を必要とするタスクでは、フラッグシップモデルよりも強い「抑制力」を示します——「完全な答え」を提供するためにデータを捏造しません。
GLM-5.1:智譜のエンジニアリング蓄積
GLM-5.1のプログラミングと構造化タスクでの安定性は、コミュニティによって検証されています。請求書処理において、この特性を拡張しています:高精度を要求するタスクでは、GLM-5.1の幻覚率は同レベルのモデルよりも有意に低い。これは智譜の知識グラフと構造化理解における技術蓄積に関連している可能性があります。
MIMO V2.5 ProとMiniMax M2.7:過信の代償
両モデルとも「データ捏造」の問題を示しました。これは共通の脆弱性を反映しています:モデルが「常に完全な答えを与える」ように訓練されている場合、不確実な情報を含むシナリオで幻覚を起こしやすくなります。
行動提言
開発者向け
- 独自のテストスイートを構築する:実際のビジネスデータ(請求書、契約書、レポートなど)を使用して候補モデルをテストし、精度、幻覚率、初回完了率を記録
- SWE-benchスコアだけを見ない:コード生成能力 ≠ データ処理能力。実際のタスクタイプに基づいてモデルを選択
- モデルの「拒否能力」に注目する:良いモデルは「わからない」と言うべきタイミングを知るべき
企業向け
- PoCフェーズに幻覚テストを含める:モデル選定の過程で、不完全な情報を含むテストケースを特別に設計し、幻覚傾向を評価
- 重要タスクには二重モデルの交差検証を使用:金融、法務などの高リスクシナリオでは、2つの独立したモデルで結果を交差検証
モデルベンダー向け
- 「不確実性の表現」トレーニングを追加:RLHFに「情報が不足している場合は拒否すべき」という選好信号を含める
- 構造化出力の保証を提供:JSONスキーマ検証をサポートし、準拠しない出力の自動修正
主な情報源: