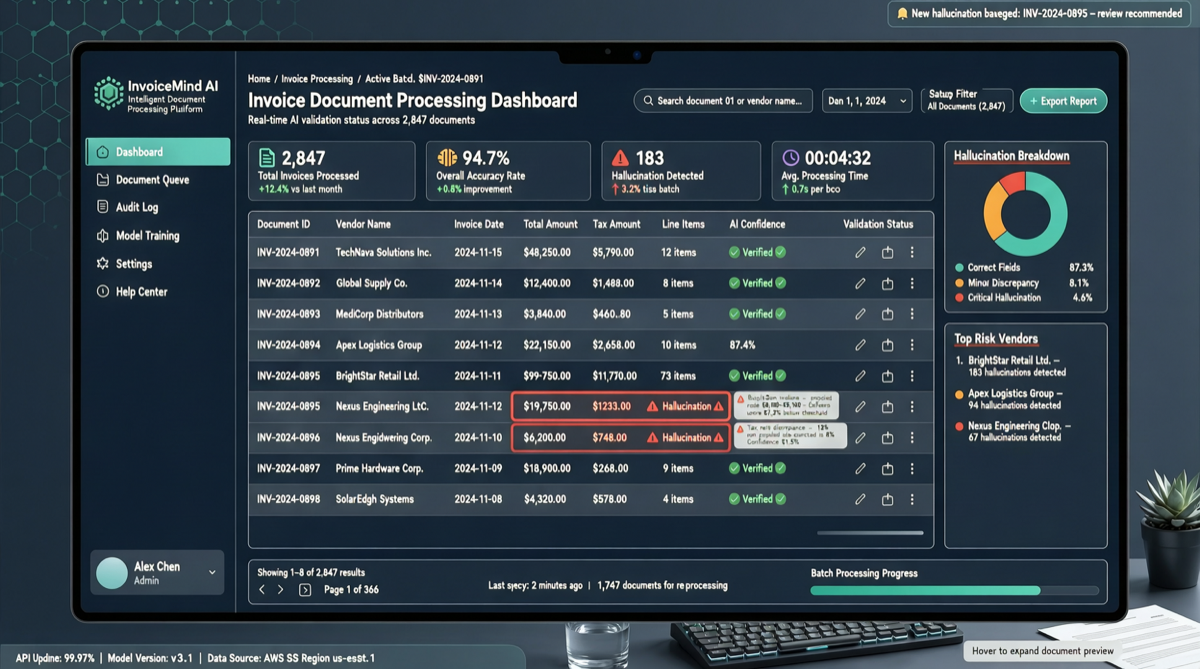
За пределами бенчмарков: реальные задачи — истинный экзамен
В системе оценки AI-моделей стандартизированные бенчмарки, такие как SWE-bench, MMLUPro и HumanEval, стали отраслевым консенсусом. Но всё более очевидный факт: между баллами бенчмарков и производительностью в реальных задачах существует значительный разрыв.
Недавно разработчик из сообщества протестировал несколько основных моделей с одной и той же задачей обработки счетов, выявив удивительное расхождение:
В фактическом тестировании задачи обработки счетов только DeepSeek V4 Flash, GPT-5.5 и GLM-5.1 надёжно выполнили задачу. MIMO V2.5 Pro и MiniMax M2.7 выдумывали данные.
Это не пограничный случай. Обработка счетов, извлечение структурированных данных, выполнение сложных инструкций — эти кажущиеся «простыми» задачи как раз являются теми workload’ами, с которыми AI-агенты чаще всего сталкиваются в реальном бизнесе.
Сводка результатов тестирования
| Модель | Задача выполнена | Точность данных | Риск галлюцинаций | Общая оценка |
|---|---|---|---|---|
| DeepSeek V4 Flash | Да | Высокая | Низкий | Надёжная |
| GPT-5.5 | Да | Высокая | Низкий | Надёжная |
| GLM-5.1 | Да | Высокая | Низкий | Надёжная |
| MIMO V2.5 Pro | Нет | Выдумывание | Высокий | Галлюцинации |
| MiniMax M2.7 | Нет | Выдумывание | Высокий | Галлюцинации |
Почему возникает такое расхождение
DeepSeek V4 Flash: победа прагматика
Надёжная работа DeepSeek в реальных задачах согласуется с его философией дизайна: не чрезмерное стремление к баллам бенчмарков, а акцент на практическую применимость. Версия V4 Flash, сжимая затраты, сохраняет достаточную способность к рассуждению. В задачах, требующих точного извлечения информации, таких как обработка счетов, она проявляет большую «сдержанность», чем флагманские модели — не выдумывает данные ради «полного ответа».
GLM-5.1: инженерный опыт Zhipu
Стабильность GLM-5.1 в программировании и структурированных задачах подтверждена сообществом. В обработке счетов эта характеристика проявляется особенно: в задачах, требующих высокой точности, частота галлюцинаций GLM-5.1 значительно ниже, чем у моделей того же уровня.
MIMO V2.5 Pro и MiniMax M2.7: цена самоуверенности
Обе модели продемонстрировали проблему «выдумывания данных». Это отражает общую уязвимость: когда модели обучены «всегда давать полный ответ», они более склонны к галлюцинациям в сценариях с неопределённой информацией.
Рекомендации к действию
Для разработчиков
- Создайте собственный набор тестов: Используйте реальные бизнес-данные (счета, контракты, отчёты) для тестирования кандидатов, фиксируя точность, частоту галлюцинаций и процент выполнения с первой попытки
- Не смотрите только на баллы SWE-bench: Способность генерировать код ≠ способность обрабатывать данные. Выбирайте модели на основе ваших реальных типов задач
- Обращайте внимание на «способность отказа» моделей: Хорошая модель должна знать, когда сказать «не знаю»
Для предприятий
- Фаза PoC должна включать тестирование на галлюцинации: В процессе выбора моделей специально разрабатывайте тестовые случаи с неполной информацией для оценки склонности к галлюцинациям
- Используйте перекрёстную проверку двумя моделями для критических задач: В высокорисковых сценариях, таких как финансы и юриспруденция, используйте две независимые модели для перекрёстной проверки результатов
Для поставщиков моделей
- Добавьте обучение «выражению неопределённости»: Включите сигналы предпочтения «следует отказаться при недостатке информации» в RLHF
- Обеспечьте гарантии структурированного вывода: Поддерживайте валидацию JSON Schema с автоматической коррекцией несоответствующего вывода
Источники: