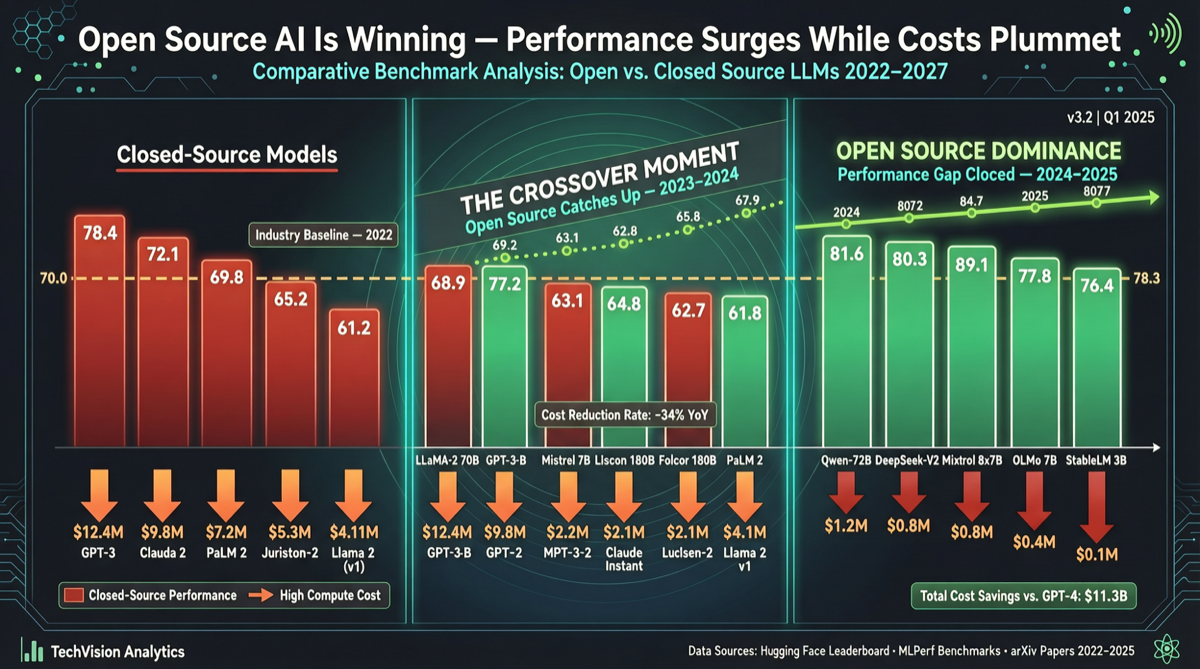
核心结论
2026 年 5 月,开源 AI 模型与闭源 API 之间的性能差距正在消失。OpenRouter 最新排行榜显示,Kimi K2.6 已在综合能力上领先开源阵营,GLM 5.1 紧随其后,DeepSeek V4 Preview 正在追赶。对开发者而言,这释放了一个明确信号:如果你在做批量处理、异步推理或成本敏感的任务,开源模型已经可以替代大部分闭源 API 调用。
性能对标
OpenRouter 榜单现状
| 模型 | 类型 | 综合排名 | 优势领域 | 相对短板 |
|---|---|---|---|---|
| GPT-5.5 | 闭源 | #1 | 指令跟随、复杂推理 | API 价格高 |
| Claude 4 Opus | 闭源 | #2 | 长文本、代码 | API 价格高 |
| Kimi K2.6 | 开源 | #3-4 | 中文理解、多轮对话 | 推理速度 |
| GLM 5.1 | 开源 | #4-5 | 工具调用、Agent | 推理速度 |
| DeepSeek V4 Preview | 开源 | #5-6 | 数学、代码 | 仍在训练中 |
| Gemini 2.5 Pro | 闭源 | #2-3 | 多模态 | 中文场景一般 |
关键信号:Kimi K2.6 和 GLM 5.1 已经”非常接近闭源 AI 的性能”,这是多位开发者的共识评价。
速度:开源模型唯一的系统性短板
| 模型 | 平均首 token 延迟 | 吞吐量 (tokens/s) | 适合场景 |
|---|---|---|---|
| GPT-5.5 | ~500ms | 120-150 | 实时交互 |
| Claude 4 | ~600ms | 100-130 | 实时交互 |
| Kimi K2.6 (API) | ~800ms | 80-100 | 准实时 |
| GLM 5.1 (API) | ~900ms | 70-90 | 准实时 |
| 本地部署 (A100) | ~300ms | 50-80 | 批量处理 |
速度差距在缩小:云端 API 版本的 Kimi/GLM 延迟在 800-900ms 量级,本地部署在 A100 上可以压到 300ms。对于异步任务(批量处理、数据标注、内容生成),速度根本不是问题。
成本对比:这才是真正的驱动力
以月处理 100 万 tokens 为基准:
| 方案 | 月成本 | 每百万 token 成本 | 备注 |
|---|---|---|---|
| GPT-5.5 API | $15-25 | $15-25 | 输入+输出混合 |
| Claude 4 API | $20-30 | $20-30 | 含 system prompt 开销 |
| Kimi K2.6 API | $2-5 | $2-5 | 国产 API 价格优势 |
| GLM 5.1 API | $2-4 | $2-4 | 性价比极高 |
| 本地部署 (电费) | $0.5-1 | ~$0.5 | 硬件成本另计 |
闭源 API 的成本是开源方案的 5-15 倍。当性能差距缩小到 10% 以内时,成本就成了决定性因素。
哪些场景已经可以迁移?
| 场景 | 迁移可行性 | 推荐方案 | 注意事项 |
|---|---|---|---|
| 批量数据标注 | ✅ 完全可行 | Kimi K2.6 本地部署 | 对速度不敏感 |
| 内容生成 | ✅ 完全可行 | GLM 5.1 API | 中文场景表现好 |
| 客服对话 | ⚠️ 部分可行 | Kimi K2.6 API | 延迟需评估 |
| 实时翻译 | ⚠️ 部分可行 | 专用小模型 | 通用模型延迟偏高 |
| 代码生成 | ✅ 可行 | Kimi K2.6 + DeepSeek | 代码场景开源表现好 |
| 复杂推理链 | ❌ 暂不建议 | GPT-5.5 / Claude 4 | 闭源仍有优势 |
迁移策略
渐进式迁移(推荐)
阶段一:非关键任务迁移
→ 数据清洗、批量摘要、内容初稿
→ 用开源模型,保留闭源模型做质量抽检
阶段二:核心任务灰度
→ 客服、翻译、代码生成
→ A/B 测试开源 vs 闭源的输出质量
阶段三:按需回退
→ 保留闭源 API 作为 fallback
→ 当开源模型不满足质量要求时自动切换混合架构示例
def smart_route(prompt, task_type):
if task_type in ["batch_label", "content_draft"]:
return kimi_client.generate(prompt) # 低成本
elif task_type in ["complex_reasoning", "safety_critical"]:
return gpt_client.generate(prompt) # 高质量
else:
return glm_client.generate(prompt) # 平衡型行业格局判断
AI 行业正在经历”云计算时代”的重演:
- 早期:闭源 API 是唯一选择,价格高但性能最好
- 现在:开源模型性能追平,价格差距显著
- 未来:闭源 API 退守”最高端场景”(实时交互、复杂推理、多模态),开源模型占据”大批量场景”
这不是零和博弈——API 厂商会降价,开源模型会提速,最终用户受益。
行动建议
- 今天:查看你的 API 账单,找出占成本 80% 的使用场景
- 本周:用 Kimi K2.6 或 GLM 5.1 的 API 替换其中 20% 的非关键调用
- 本月:如果有 GPU 资源,部署本地推理服务,进一步降低成本
- 持续:关注 OpenRouter 排行榜,跟踪开源模型的性能变化
当开源模型的性能差距缩小到”感知不到”而成本差距仍在”肉眼可见”时,迁移就不再是技术问题,而是商业决策。