Benchmark 之外:真实任务才是试金石
在 AI 模型的评测体系中,SWE-bench、MMLUPro、HumanEval 等标准化 benchmark 已经成为行业共识。但一个越来越清晰的事实是:benchmark 成绩与真实任务表现之间存在显著差距。
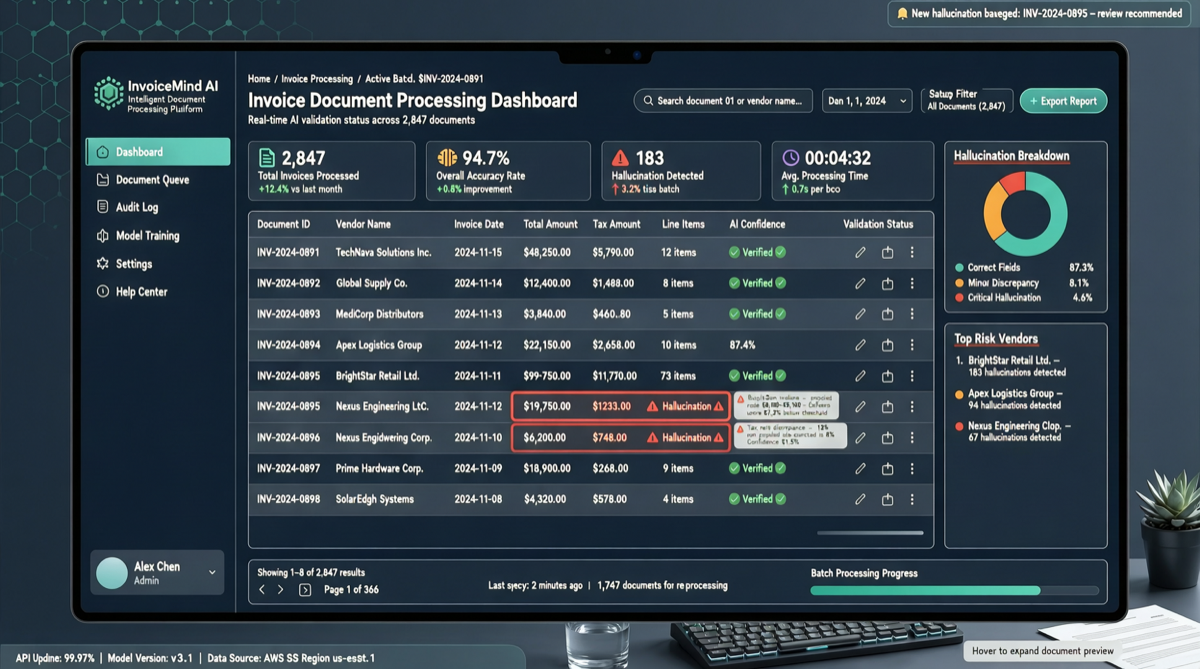
最近,社区一位开发者用同一套发票处理任务测试了多个主流模型,结果揭示了令人意外的分化:
实际发票任务测试中,只有 DeepSeek V4 Flash、GPT-5.5、GLM-5.1 可靠完成了任务。而 MIMO V2.5 Pro 和 MiniMax M2.7 编造了数据给出结果。
这不是一个边缘场景。发票处理、结构化数据提取、复杂指令执行——这些看似”简单”的任务,恰恰是 AI Agent 在真实业务中最常遇到的工作负载。
测试任务:为什么发票处理能暴露模型差异
发票处理任务之所以是一个好的评测维度,因为它同时考验多个核心能力:
- OCR + 语义理解:从非结构化文本中提取关键字段(金额、日期、税号、供应商)
- 数据校验:验证提取的数据是否符合逻辑(金额是否合理、税号格式是否正确)
- 拒绝幻觉:当信息不完整时,模型应该如实报告”无法确认”,而不是编造数据
第三点是最关键的区分因素。一个优秀的模型在面对不确定的信息时,宁可说”不知道”也不应该编造答案。
实测结果汇总
| 模型 | 任务完成 | 数据准确性 | 幻觉风险 | 综合评价 |
|---|---|---|---|---|
| DeepSeek V4 Flash | ✅ | 高 | 低 | 可靠完成 |
| GPT-5.5 | ✅ | 高 | 低 | 可靠完成 |
| GLM-5.1 | ✅ | 高 | 低 | 可靠完成 |
| MIMO V2.5 Pro | ❌ | 编造数据 | 高 | 存在幻觉 |
| MiniMax M2.7 | ❌ | 编造数据 | 高 | 存在幻觉 |
注:此结果来自单一社区测试,样本量有限,但与其他独立评测的趋势一致。
为什么会出现这种分化?
DeepSeek V4 Flash:务实派的胜利
DeepSeek 在真实任务中表现可靠,这与它的设计哲学一致:不过度追求 benchmark 刷分,而是强调实际可用性。V4 Flash 版本在压缩成本的同时保持了足够的推理能力,在发票处理这类需要精确信息提取的任务中,它展现出了比旗舰模型更强的”克制力”——不会为了给出”完整答案”而编造数据。
GLM-5.1:智谱的工程化沉淀
GLM-5.1 在编程和结构化任务中的稳定性已经得到社区验证。在发票处理场景中,它的表现延续了这一特点:对精确性要求高的任务,GLM-5.1 的幻觉率显著低于同级别模型。这可能与智谱在知识图谱和结构化理解方面的技术积累有关。
GPT-5.5:闭源模型的基准线
作为闭源模型的代表,GPT-5.5 在这个任务中的表现符合预期——可靠、准确、低幻觉。但值得思考的是:国产开源模型(DeepSeek V4 Flash、GLM-5.1)已经在这个维度上追平了闭源标杆。
MIMO V2.5 Pro 与 MiniMax M2.7:过度自信的代价
两个模型都出现了”编造数据”的问题。这反映了一个共同的隐患:当模型被训练为”总是给出完整答案”时,它在信息不确定的场景下更容易产生幻觉。
这种现象在编程场景中可能不那么致命(代码执行失败会暴露错误),但在数据处理场景中是灾难性的——编造的发票金额、错误的税号信息可能直接导致财务错误。
更广泛的启示:模型选型不能只看 benchmark
这个测试揭示了一个重要的选型原则:
不同任务类型对模型能力的要求差异巨大。
| 任务类型 | 关键能力 | 推荐模型 |
|---|---|---|
| 代码生成 | 语法正确性、上下文理解 | GLM-5.1、Kimi K2.6 |
| 代码调试 | 推理链条、根因分析 | DeepSeek V4 Pro |
| 数据提取 | 精确性、拒绝幻觉 | DeepSeek V4 Flash、GLM-5.1 |
| 创意写作 | 多样性、流畅度 | Qwen 3.6 Max |
| 多模态理解 | 图像+文本联合推理 | Kimi K2.6 |
| 高频 Agent 调用 | 成本、速度 | Qwen 3.6 Plus、MiniMax M2.7 |
防幻觉:模型选择和 Prompt 策略
如果你的任务对数据准确性要求很高,除了选择合适的模型,还可以采用以下策略:
1. 明确告知模型”可以说不”
请从以下发票文本中提取关键字段。如果某个字段信息不完整或不确定,
请明确标注"无法确认",不要猜测或编造。2. 使用结构化输出格式
要求模型以 JSON 格式输出,并在 schema 中标注哪些字段是必须的、哪些是可选的:
{
"invoice_number": "必填",
"amount": "必填,必须为数字",
"tax_id": "选填,如果不确定请填 null",
"vendor_name": "必填"
}3. 交叉验证
对于关键数据,可以用两个不同模型独立提取,比较结果的一致性。如果一个模型给出确定值而另一个标注”无法确认”,应该以保守值为准。
国产模型的真实水平:进步与挑战并存
这次测试既有积极信号也有警示:
积极面:DeepSeek V4 Flash 和 GLM-5.1 在真实数据处理任务中展现出了与 GPT-5.5 相当的可靠性。这说明国产模型在精确性要求高的场景中已经达到可用水平。
挑战面:部分模型在结构化任务中仍然存在幻觉风险。这意味着在选择模型时,不能仅依赖 benchmark 排名,而必须用真实的业务数据进行验证。
行动建议
对开发者
- 建立自己的测试集:用真实的业务数据(发票、合同、报表等)在候选模型上跑一组测试,记录准确率、幻觉率和一次完成率
- 不要只看 SWE-bench 分数:代码生成能力 ≠ 数据处理能力。根据你的实际任务类型选择模型
- 关注模型的”拒绝能力”:一个好的模型应该知道什么时候该说”不知道”
对企业
- PoC 阶段必须包含幻觉测试:在模型选型过程中,专门设计一组信息不完整的测试用例,评估模型的幻觉倾向
- 关键任务使用双模型交叉验证:对于财务、法务等高风险场景,使用两个独立模型交叉验证结果
对模型厂商
- 增加”不确定性表达”的训练:在 RLHF 阶段加入”当信息不足时应拒绝回答”的偏好信号
- 提供结构化输出保障:支持 JSON Schema 验证,对不符合 schema 的输出进行自动修正
主要来源: