技术报告核心发现
DeepSeek-V4 技术报告的发布,终于揭示了为什么这个模型能在保持低成本的同时达到旗舰级性能。报告中有两个技术层面的创新特别值得关注:
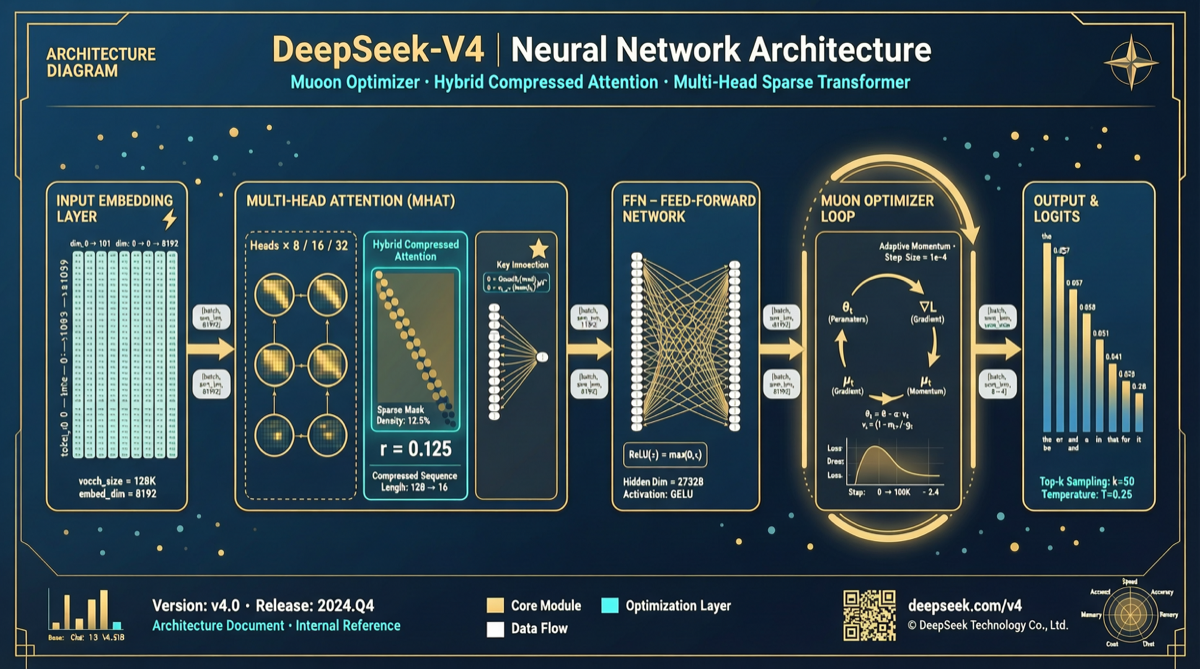
创新一:混合压缩注意力系统
痛点:标准 Attention 的计算瓶颈
在大规模语言模型训练中,标准的 Self-Attention 机制存在一个根本性问题:计算复杂度随序列长度呈平方级增长。
标准 Attention 复杂度: O(n² × d)
n = 序列长度, d = 特征维度当序列长度从 4K 扩展到 128K 时,Attention 的计算量增长 1024 倍。这直接导致:
- 训练时间暴增
- 显存占用爆炸
- 推理延迟不可接受
DeepSeek 的方案:混合压缩
DeepSeek-V4 没有简单地选择某一种注意力压缩技术(如 FlashAttention、滑动窗口、Linear Attention),而是采用了混合策略:
混合压缩注意力架构:
┌──────────────────────────────────────┐
│ 短距离上下文 → 标准 Attention (精确) │
│ 中距离上下文 → 滑动窗口 Attention │
│ 长距离上下文 → 压缩/线性 Attention │
│ 全局上下文 → 压缩 Token 摘要 │
└──────────────────────────────────────┘这种设计的关键优势:
| 维度 | 标准 Attention | 混合压缩方案 | 提升 |
|---|---|---|---|
| 计算复杂度 | O(n²) | O(n × log n) | ~10-100x |
| 显存占用 | 全量 KV Cache | 分层压缩 | 60-80% |
| 长程信息保留 | 100% | 95%+ | 损失 < 5% |
为什么这很重要?
大多数模型在”压缩注意力”和”保留信息”之间做权衡。DeepSeek 的思路是让模型自己决定在不同距离使用不同的注意力机制——这不是固定的规则,而是训练过程中学到的自适应行为。
对于编程场景,这意味着:
- 函数体内的代码(短距离)用精确 Attention 处理
- 同一文件中的其他函数(中距离)用滑动窗口
- 跨文件的依赖关系(长距离)用压缩注意力
创新二:Muon 优化器
背景:Adam 的局限
过去几年,Adam 及其变体(AdamW、AdamW8bit)几乎是大语言模型训练的默认优化器选择。但随着模型规模突破千亿参数,Adam 的问题逐渐暴露:
- 内存开销大:需要为每个参数维护两个动量状态(一阶和二阶)
- 训练后期不稳定:在 fine-tuning 阶段容易振荡
- 超参数敏感:学习率的微小变化可能导致训练崩溃
Muon 的核心思路
Muon(Matrix-oriented Optimizer)采用了完全不同的优化方向:
Adam: 逐元素 (element-wise) 的自适应学习率
Muon: 基于矩阵结构 (matrix-structured) 的优化方向具体来说,Muon 将权重矩阵视为整体进行优化,而不是逐个元素调整。这带来了三个直接好处:
| 优化维度 | Adam | Muon |
|---|---|---|
| 训练速度 | 基准 | 更快 |
| 训练稳定性 | 中等 | 更高 |
| 超参数敏感度 | 高 | 低 |
训练速度提升
技术报告显示,在同等硬件条件下,Muon 优化器使 DeepSeek-V4 的训练速度显著提升。虽然报告没有给出精确的百分比数字,但社区根据训练日志推测提速在 15-25% 之间。
对于需要数万 GPU-hour 的训练任务来说,20% 的速度提升意味着:
- 节省数千 GPU 小时
- 降低数万美元的算力成本
- 更快的迭代周期
创新三:改进的层间连接
技术报告还提到了一个容易被忽视但影响深远的改进:层间连接(inter-layer connections)的重新设计。
传统 Transformer 的层间信息流动是线性的:
Layer 1 → Layer 2 → Layer 3 → ... → Layer NDeepSeek-V4 引入了更复杂的连接模式,允许信息在不同层之间”跳跃”传播:
Layer 1 ─→ Layer 2 ─→ Layer 3 ─→ Layer 4
↓ ↑ ↓ ↑
Layer 5 ←── Layer 6 ←── Layer 7 ←── Layer 8这种设计直接提升了模型处理复杂多步推理任务的能力——因为推理过程本质上需要在不同抽象层次之间来回切换。
这些创新对开发者的实际意义
1. API 使用
如果你正在使用 DeepSeek V4-Pro API(目前有 75% 折扣),了解这些技术细节可以帮助你更好地设计 prompt:
- 长上下文任务:混合压缩注意力意味着模型在 128K 上下文下的表现不会像传统模型那样急剧衰减。可以放心地传入大量上下文。
- 复杂推理任务:改进的层间连接让 V4 在多步推理上更强。对于需要”先分析、再规划、最后执行”的任务,可以尝试让模型输出完整的思考链。
2. 开源部署
如果 DeepSeek-V4 开源(目前 V4 技术报告的发布通常是开源的前兆),混合压缩注意力意味着:
- 显存需求更低:KV Cache 压缩减少了推理时的显存压力
- 可以在更便宜的 GPU 上运行:60-80% 的显存节省意味着原本需要 8 张 A100 的模型,现在可能只需要 4 张
3. 对比竞品
| 技术特性 | DeepSeek V4 | Qwen 3.6 | Claude Opus 4.7 |
|---|---|---|---|
| 注意力机制 | 混合压缩 | 标准 + RoPE | 未公开 |
| 优化器 | Muon | AdamW 变体 | 未公开 |
| 层间连接 | 改进型 | 标准 | 未公开 |
| 长上下文 | 128K+ | 256K+ | 200K+ |
DeepSeek 的优势在于:用更少的算力达到相近的效果。
总结
DeepSeek-V4 技术报告的价值不仅在于揭示了一个高性能模型的技术细节,更在于它提供了一条不同于”堆参数、堆算力”的技术路线。
混合压缩注意力 + Muon 优化器 + 改进层间连接,这套组合拳的核心逻辑是:在架构层面创新,而非在规模层面竞赛。
对于预算有限但需要旗舰级性能的团队来说,DeepSeek-V4 的技术路线可能代表了一个更可持续的发展方向。