核心发现
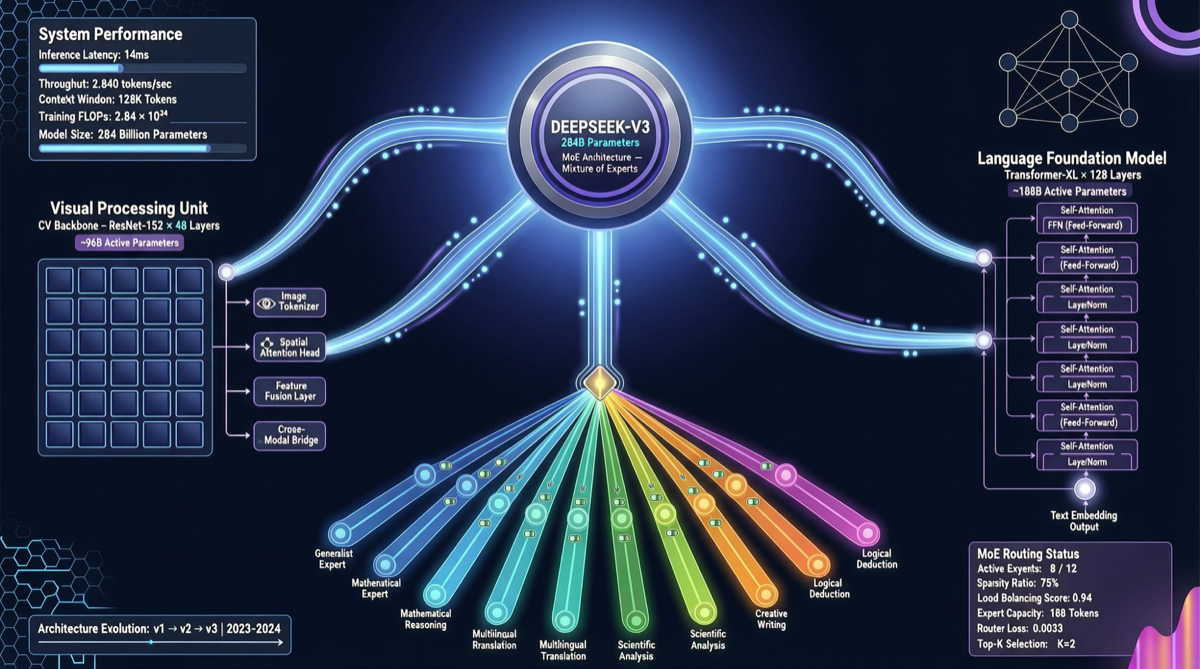
DeepSeek 于 4 月底公开了多模态大语言模型论文《Thinking with Visual Primitives》,揭开了其视觉-语言统一架构的技术细节。该模型基于 DeepSeek-V4-Flash MoE 底座(总参数 284B,激活参数 13B),搭载自研 DeepSeek-ViT 视觉编码器,代表了国内多模态模型从”拼接方案”向”原生架构”的重要转变。
技术架构拆解
| 组件 | 规格 | 关键设计 |
|---|---|---|
| 语言底座 | DeepSeek-V4-Flash | 284B 总参数 / 13B 激活,MoE 架构 |
| 视觉编码器 | DeepSeek-ViT | 14×14 patch 划分,3×3 空间压缩后接入 LLM |
| 模态融合 | 原生 token 对齐 | 视觉特征直接映射为语言 token,无需跨模态投影层 |
| 推理模式 | 支持 thinking | 视觉任务同样启用思维链推理 |
视觉编码器的关键创新
DeepSeek-ViT 采用 14×14 的 patch 划分策略,与传统 ViT 类似,但在输出后增加了一个 3×3 的空间压缩步骤。这一设计大幅降低了视觉 token 数量,缓解了长序列推理时的计算瓶颈——这在处理高分辨率图像时尤为关键。
对比主流方案:
| 方案 | 视觉编码策略 | Token 压缩比 | 推理延迟 |
|---|---|---|---|
| DeepSeek-ViT | 14×14 patch + 3×3 空间压缩 | 高 | 低 |
| Qwen2-VL | 动态分辨率 | 中 | 中 |
| LLaVA-OneVision | 固定 patch | 低 | 高 |
| InternVL | 多尺度特征 | 中 | 中 |
”Visual Primitives”是什么意思?
论文标题中的”Visual Primitives”指的是模型将视觉信息分解为基本视觉单元(primitive)进行思考,而非简单地将图像编码为固定向量。这种设计允许模型在推理过程中对视觉特征进行细粒度操作,类似于人类在观察图像时先识别基本元素(边缘、形状、颜色),再组合成高层语义理解。
为什么值得关注
1. MoE 多模态的先行者
大多数开源多模态模型采用 dense 架构,而 DeepSeek 首次将 MoE 架构成功应用到多模态场景。284B 总参数但仅激活 13B,意味着在保持强大视觉理解能力的同时,推理成本控制在可接受范围内。
2. 开源路线的信号
论文公开意味着 DeepSeek 延续了其一贯的开源策略。如果模型权重后续开放,将成为目前参数量最大的开源多模态 MoE 模型之一,直接竞争 Qwen2-VL 和 InternVL 的生态位。
3. 与 V4 发布时间线的关联
DeepSeek V4 文本模型已于 4 月底发布但市场反响平淡。这篇多模态论文的公开,暗示 DeepSeek 的产品矩阵正在从单一文本模型向多模态扩展——这可能是一种差异化竞争策略。
行动建议
- 研究者:关注论文方法部分,特别是视觉 token 压缩和 MoE 路由在多模态场景的设计
- 开发者:等待权重发布后,对比 Qwen2-VL 在相同 benchmark 上的表现
- 企业用户:当前阶段建议观望,等社区评测成熟后再考虑是否接入生产流程
DeepSeek 这次的技术路线选择——MoE + 原生视觉编码 + 开源——如果能落地为可用的模型权重,将在国产多模态模型竞争中投下一颗重磅炸弹。