結論ファースト
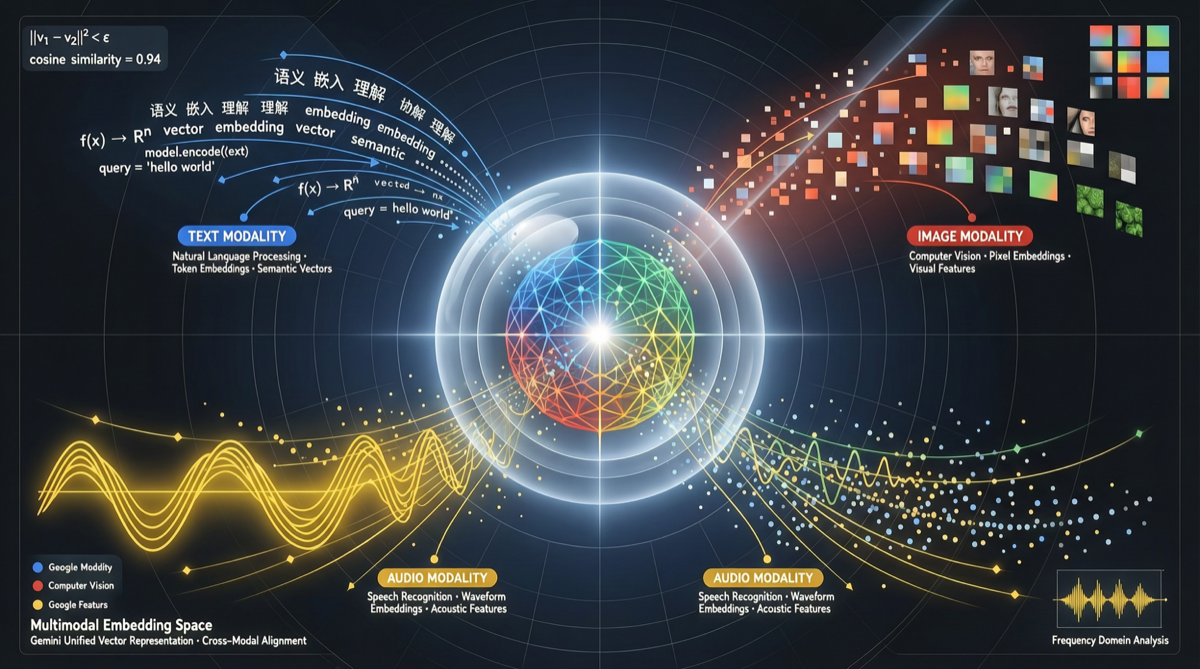
Google Gemini Embedding 2は長年存在したエンジニアリングの痛点を解決する:異なるモダリティのデータには異なるembeddingモデルが必要で、检索システムが統一空間で跨モーダルセマンティックマッチングを行うことができなかった。
今や、テキスト、画像、音声を同一ベクトル空間にエンコード可能——自然言語で画像を検索、画像で類似画像を検索することが、初めてセマンティックレベルで実現された。
技術的本質:単なる「拼接」ではない
重要なのは、画像embeddingとテキストembeddingを単純に拼接するエンジニアリングアプローチではないこと。Gemini Embedding 2はモデルアーキテクチャレベルで実現:
テキスト入力 → [Geminiエンコーダ] → 統一ベクトル
画像入力 → [Geminiエンコーダ] → 統一ベクトル
音声入力 → [Geminiエンコーダ] → 統一ベクトル
↑
同一エンコード重みアプリケーションシナリオ
RAGナレッジベースのアップグレード
従来のRAGの限界:
- ドキュメント検索はテキストのみ処理可能
- 画像、表、スクリーンショットなどの非テキストコンテンツは個別処理が必要
- 跨モーダル检索(「このアーキテクチャ図に類似したドキュメントを探す」)はほぼ不可能
Gemini Embedding 2がもたらす変化:
- ドキュメント内の画像を直接同一ナレッジベースにembedding可能
- 自然言語クエリで関連テキストと関連画像を同時に召回可能
- マルチモーダルドキュメントのセマンティック完全性が保持される
画像検索のセマンティック躍升
過去の画像検索:
- 視覚特徴の類似度ベース(色、テクスチャ、形状)
- 「この画像は何に似ているか」
Gemini Embedding 2の画像検索:
- セマンティック理解ベース(画像内容、シーン、関係)
- 「この画像は何を表現しているか」
アクション推奨
| あなたの状況 | 推奨 |
|---|---|
| 既存RAGシステム、マルチモーダルサポート必要 | テスト環境でGemini Embedding 2を接続、既存の純テキスト検索との効果向上を比較 |
| 画像/動画コンテンツプラットフォーム | Gemini Embedding 2でコンテンツインデックスを再構築、セマンティックレベルの推薦と検索を実現 |
| 跨言語ドキュメント管理 | 統一ベクトル空間特性を活用、翻訳中間層のコストと遅延を削減 |
| テキストembeddingのみ必要 | 当面は成熟したtext-embedding-3を継続使用、Gemini Embedding 2正式版リリース後に移行を評価 |
Gemini Embedding 2のリリースは、マルチモーダルAIアプリケーションが「使える」から「使いやすい」への重要な一歩を印す。混合コンテンツタイプを扱うプロジェクトにとって、即時評価すべき技術アップグレードである。