何があったか
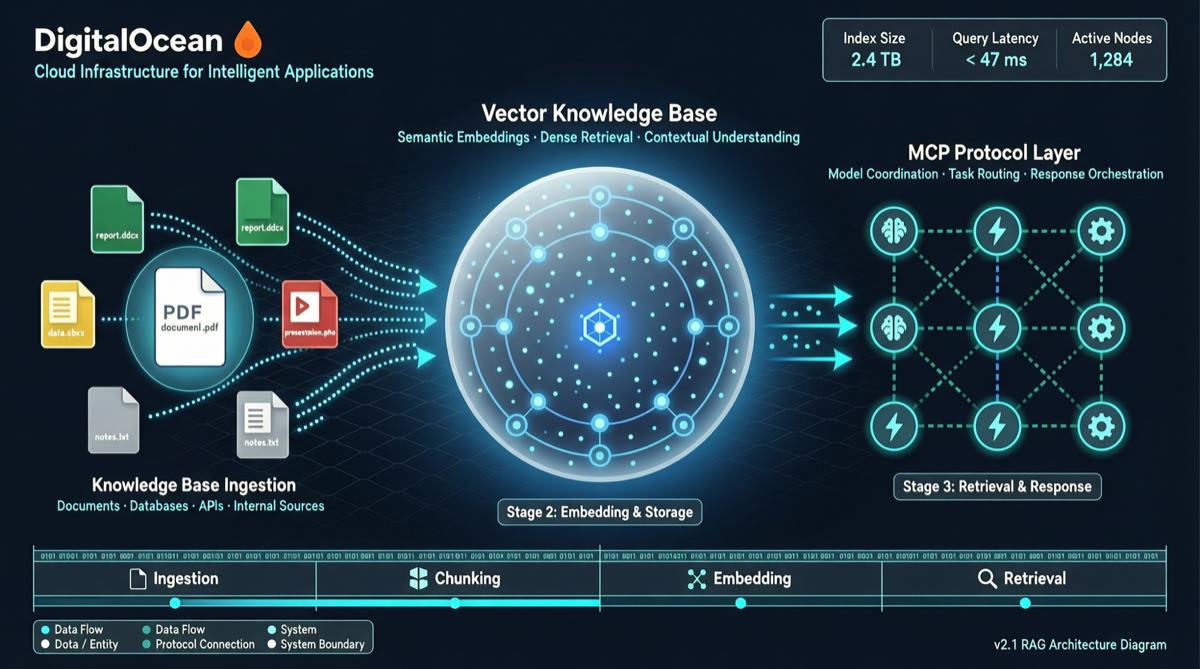
DigitalOceanはKnowledge Basesを正式にリリースした。これはフルマネージドのRAG(検索拡張生成)サービスで、データ取得から最終検索までのRAGパイプライン全体が管理される:
- データ取得:ドキュメントアップロード、Webスクレイピング、APIデータソースをサポート
- 自動チャンキング:インテリジェントなテキストチャンキング戦略
- 埋め込み生成:組み込みの埋め込みモデル、追加設定不要
- ベクトル検索:高性能ベクトルデータベース
- リランキング:検索精度を向上させる高度なリランキングアルゴリズム
コア機能のハイライト
| 機能 | 説明 |
|---|---|
| RAG Playground | 異なるチャンキング戦略、埋め込みモデル、検索パラメータをビジュアルにテスト |
| 高度なリランキング | 2段階検索(ベクトル検索+リランカー)、関連性を大幅に向上 |
| 2つの新しいOSSモデル | DigitalOcean専用の埋め込みモデルとリランキングモデル |
| MCP統合 | Model Context Protocol経由でClaude/Cursorなどのツールに直接接続 |
| フルマネージド | ベクトルデータベースや埋め込みサービスなどのインフラ維持が不要 |
なぜ注目すべきか
RAGは常にAIアプリケーションにおいて最も複雑なインフラピースの一つだった。典型的な自建セットアップには以下が必要:
- ベクトルデータベースの選択(Pinecone / Milvus / Weaviate / pgvector)
- 埋め込みモデルの選択(OpenAI / Cohere / オープンソース)
- チャンキング戦略の実装
- リランキングの実装
- 検索APIの構築
- モニタリングとメンテナンス
DigitalOcean Knowledge Basesは上記すべてをクリックして使えるサービスにパッケージ化した。中小チームにとって、これはRAGアプリケーションの参入障壁を大幅に下げる。
MCP統合の意義
MCP統合により、Knowledge BasesはClaude Desktop、Cursor、OpenClawなどのツールの直接のデータソースとして機能する。これは以下を意味する:
- Claude Desktopでエンタープライズナレッジベースを直接クエリ
- Cursorで内部ドキュメントに基づいたコーディング質問にAIが回答
- エージェントフレームワークで関連ナレッジを自動検索
競合比較
| 項目 | DigitalOcean KB | Pinecone | Weaviate Cloud | Milvus Cloud |
|---|---|---|---|---|
| フルマネージド | はい | はい | はい | はい |
| 組み込み埋め込み | はい | いいえ | 設定が必要 | 設定が必要 |
| 組み込みチャンキング | はい | いいえ | いいえ | いいえ |
| 組み込みリランキング | はい | いいえ | いいえ | いいえ |
| MCP統合 | はい | いいえ | いいえ | いいえ |
| RAG Playground | はい | いいえ | いいえ | いいえ |
| 価格体系 | 使用量ベース | ベクトル数 | ノード単位 | ノード単位 |
DigitalOceanの優位性はエンドツーエンドのRAGパイプラインにあり、単なるベクトルデータベースではない。競合は同等の機能を実現するために複数のサービスを組み合わせる必要がある。
アクション提言
- 既にDOインフラを利用中のチーム:既存アカウントで直接有効化、追加ベンダー不要
- 迅速なプロトタイピング:RAG Playgroundでブラウザ上で異なる設定をテスト、高速イテレーション
- 中小チームの本番環境:フルマネージドモデルで運用コストを削減
- 個人開発者:価格詳細に注目。使用量ベースのモデルは低トラフィックシナリオに優しい
注意点
- 新サービスのため、本番レベルの安定性とSLAは未検証
- 2つの新しいオープンソースモデルの性能はコミュニティのベンチマークテストが必要
- 超大規模ナレッジベース(百万級ドキュメント)の処理能力は観察待ち