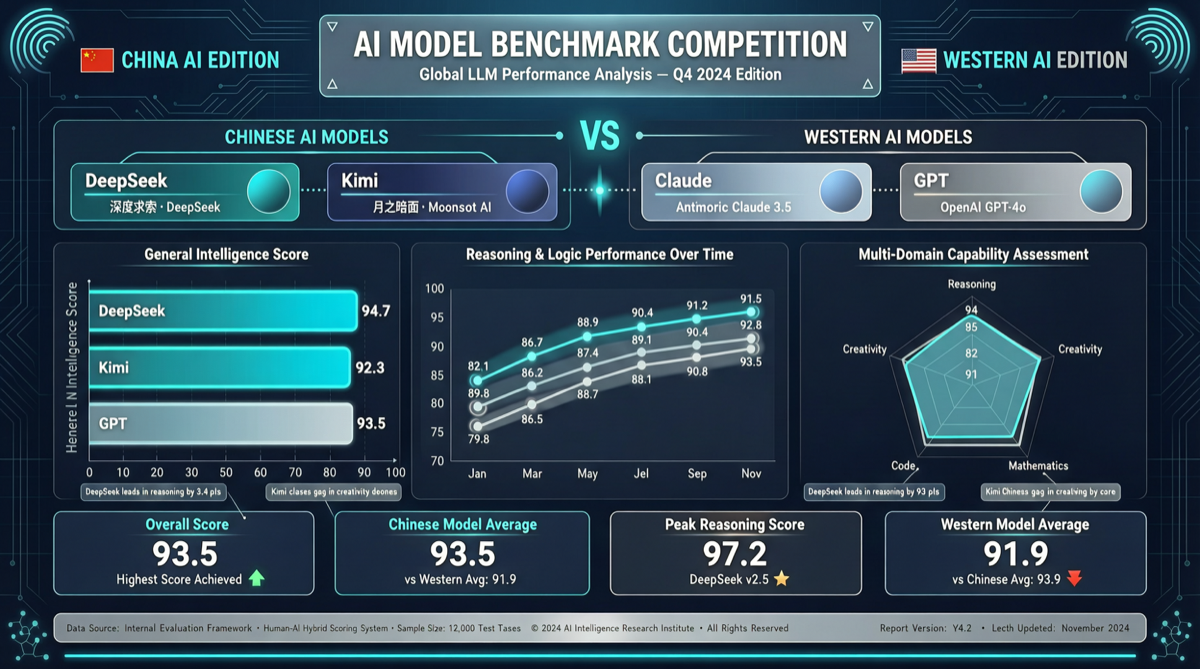
核心发现
“中国 AI 落后两年”的说法,在 2026 年 5 月的数据面前站不住脚了。
State of AI May 2026 报告揭示了一组让西方科技圈沉默的数据:
DeepSeek V4 和 Kimi K2.6 在 SWE-Bench Pro 上的得分,已经与 Claude Opus 4.7、GPT-5.5 拉平。而推理成本,只有后者的三分之一。
数据对比
| 模型 | SWE-Bench Pro | FrontierSWE | 推理成本(相对) |
|---|---|---|---|
| Claude Opus 4.7 | ~58 | ~38 | 1.0x(基准) |
| GPT-5.5 | ~58 | ~40 | 1.0x |
| DeepSeek V4 | ~57 | ~28 | 0.33x |
| Kimi K2.6 | ~56 | ~25 | 0.30x |
| Gemini 3.1 | ~57 | ~35 | 0.70x |
关键洞察:
- SWE-Bench Pro 已不再是区分器。中国开源模型在这个基准上已经追平甚至略微超越部分美国前沿模型
- FrontierSWE 才是新的分水岭。这是一个测量长程、多步骤真实工程任务的基准。在这里,Claude 和 GPT-5.5 仍然领先中国模型 10-15 个百分点
- 成本优势是结构性的。DeepSeek V4 采用 MoE(混合专家)架构,活跃参数少,推理效率显著高于稠密模型
网络攻击能力:每 4 个月翻倍
报告的另一条警示线更令人不安:
前沿模型的网络攻击能力正在以每 4 个月翻倍的速度增长。
Anthropic 的 Claude Mythos Preview 和 OpenAI 的 GPT-5.5 都通过了英国 AISI 的完整 32 步企业网络入侵模拟(无防御方)。这意味着:
- 一个前沿 AI 可以在无人干预的情况下,完成从初始渗透到域控提升的完整攻击链
- 这个能力的增长速度,远超防御工具和安全培训的迭代速度
格局判断
中国模型的突破点
DeepSeek V4 和 Kimi K2.6 的 SWE-Bench Pro 成绩并非偶然。它们的设计哲学与 Claude/GPT 不同:
- 大规模蒸馏 + 开源权重:通过从更强模型蒸馏知识,快速追赶基准表现
- MoE 架构的成本优势:在相同预算下可以处理更多 token,对开发者更友好
- 敏捷迭代:DeepSeek 在 2026 年已经完成了多次快速版本更新
美国模型的护城河
FrontierSWE 的差距说明了一个关键事实:短程编码能力已经收敛,真正的竞争在长程工程能力。
Claude Opus 4.7 和 GPT-5.5 在以下方面仍有明显优势:
- 跨模块架构理解
- 长达数十步的任务规划
- 错误恢复和自我调试
行动建议
| 你的场景 | 推荐方案 |
|---|---|
| 日常编码 / 快速原型 | DeepSeek V4(MIT 许可,成本极低,SWE-Bench Pro 表现一流) |
| 复杂系统重构 | Claude Opus 4.7 / GPT-5.5(FrontierSWE 领先,长程任务更可靠) |
| 成本敏感的批量任务 | Kimi K2.6(0.3x 成本,SWE-Bench Pro 追平) |
| 企业安全评估 | 立即启动 AI 攻击面审计,网络攻击能力正在指数增长 |
“落后”的叙事需要更新了。真正的竞争已经从”谁能跑通基准测试”转向了”谁能处理真实世界中的长程工程任务”。