结论先行
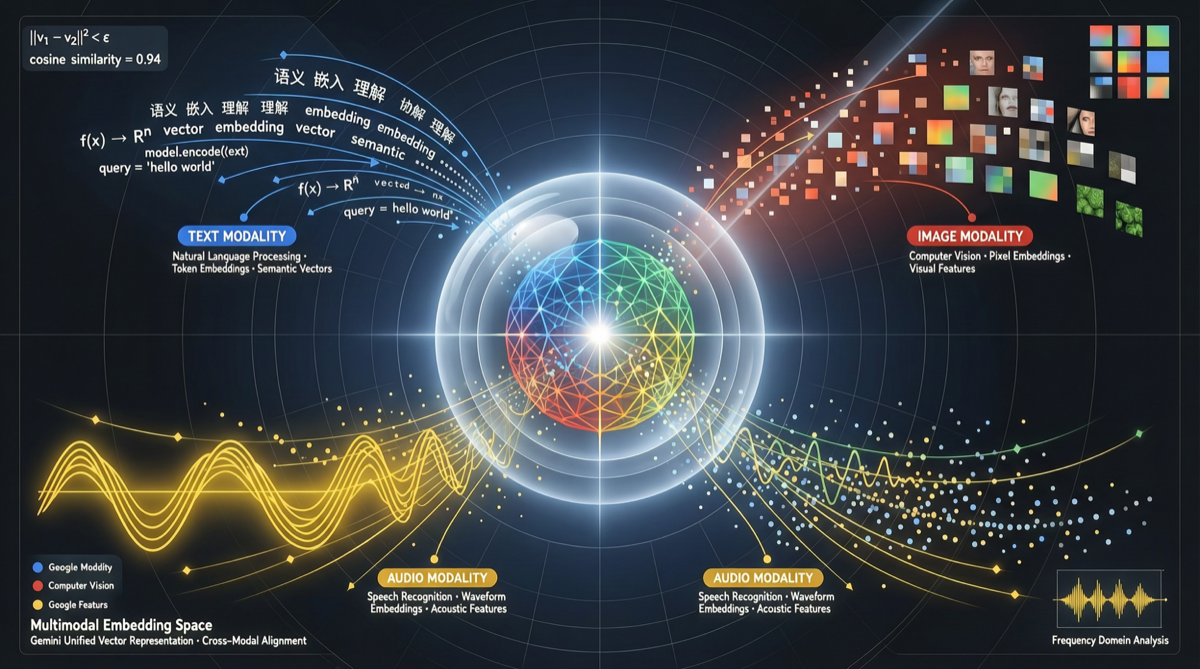
Google Gemini Embedding 2 解决了一个长期存在的工程痛点:不同模态的数据需要不同的 embedding 模型,导致检索系统无法在统一空间中做跨模态语义匹配。
现在,文本、图像、音频可以被编码到同一个向量空间——用自然语言搜图、用图搜相似图,第一次在语义层面而非关键词层面实现了。
发生了什么
Google AI 官方宣布 Gemini Embedding 2 正式发布,核心特性:
- 首个完全多模态 embedding 模型:基于 Gemini 架构构建,非简单的图+文拼接
- 统一向量空间:文本、图像、音频映射到同一语义空间
- 100+ 语言支持:覆盖主流语言,支持跨语言语义检索
- API 可用:通过 Gemini API 和 Google Cloud Vertex AI 提供预览访问
技术本质:不只是”拼接”
关键区别在于,这不是把图像 embedding 和文本 embedding 简单拼在一起的工程方案。Gemini Embedding 2 在模型架构层面实现了:
文本输入 → [Gemini Encoder] → 统一向量
图像输入 → [Gemini Encoder] → 统一向量
音频输入 → [Gemini Encoder] → 统一向量
↑
同一套编码权重这意味着一个自然语言查询(如”穿红色连衣裙的女孩在海边跑步”)和一张真实照片,在向量空间中具有可比性的语义距离——而不是分别在不同空间里做检索再做某种后期融合。
应用场景
RAG 知识库升级
传统 RAG 的局限:
- 文档检索只能处理文本
- 图片、表格、截图等非文本内容需要单独处理
- 跨模态检索(“找和这张架构图类似的文档”)几乎不可行
Gemini Embedding 2 带来的改变:
- 文档中的图片可以直接被 embedding 到同一知识库
- 自然语言查询可以同时召回相关文本和相关图片
- 多模态文档的语义完整性得到保持
以图搜图的语义跃升
过去的以图搜图:
- 基于视觉特征相似度(颜色、纹理、形状)
- “这张图看起来像什么”
Gemini Embedding 2 的以图搜图:
- 基于语义理解(图片内容、场景、关系)
- “这张图表达了什么意思”
跨语言内容检索
100+ 语言支持意味着:
- 用中文搜英文文档 → 向量空间天然对齐,无需翻译中间层
- 多语言混合知识库的统一索引成为可能
与竞品的对比
| 维度 | Gemini Embedding 2 | OpenAI text-embedding-3 | Cohere embed-v4 |
|---|---|---|---|
| 多模态 | ✅ 文本+图像+音频 | ❌ 仅文本 | ❌ 仅文本 |
| 统一向量空间 | ✅ | N/A | N/A |
| 语言支持 | 100+ | 100+ | 100+ |
| 可用方式 | Gemini API + Vertex AI | OpenAI API | Cohere API |
| 当前状态 | 预览 | GA | GA |
成本考量
目前 Gemini Embedding 2 处于预览阶段,Google 尚未公布最终定价。参考 Gemini 系列 API 的定价模式,预计:
- 预览期间可能有免费额度或折扣
- 正式版可能按每千次请求或每百万 token 计费
- Vertex AI 企业版可能包含在订阅计划中
行动建议
| 你的场景 | 建议 |
|---|---|
| 已有 RAG 系统、需要多模态支持 | 在测试环境接入 Gemini Embedding 2,对比现有纯文本检索的效果提升 |
| 图片/视频内容平台 | 用 Gemini Embedding 2 重建内容索引,实现语义级推荐和搜索 |
| 跨语言文档管理 | 利用统一向量空间特性,减少翻译中间层的成本和延迟 |
| 仅需要文本 embedding | 当前阶段可继续用成熟的 text-embedding-3,等待 Gemini Embedding 2 正式版发布后再评估迁移 |
值得关注的限制
预览阶段的已知约束:
- 多模态输入可能有尺寸/格式限制(具体参考官方文档)
- 向量维度需要适配现有向量数据库(Pinecone、Milvus、Qdrant 等)
- 批量 embedding 的吞吐量需要实测
Gemini Embedding 2 的发布,标志着多模态 AI 应用从”能用”走向”好用”的关键一步。对于需要处理混合内容类型的项目,这是值得立即评估的技术升级。