发生了什么
2026 年 5 月的国产 AI 模型阵营,正在经历从”单一追赶叙事”到”差异化竞争格局”的关键转折。多个独立信号指向同一个结论:国产模型不再是 GPT 的”便宜替代品”,而是在不同维度上建立了各自的竞争优势。
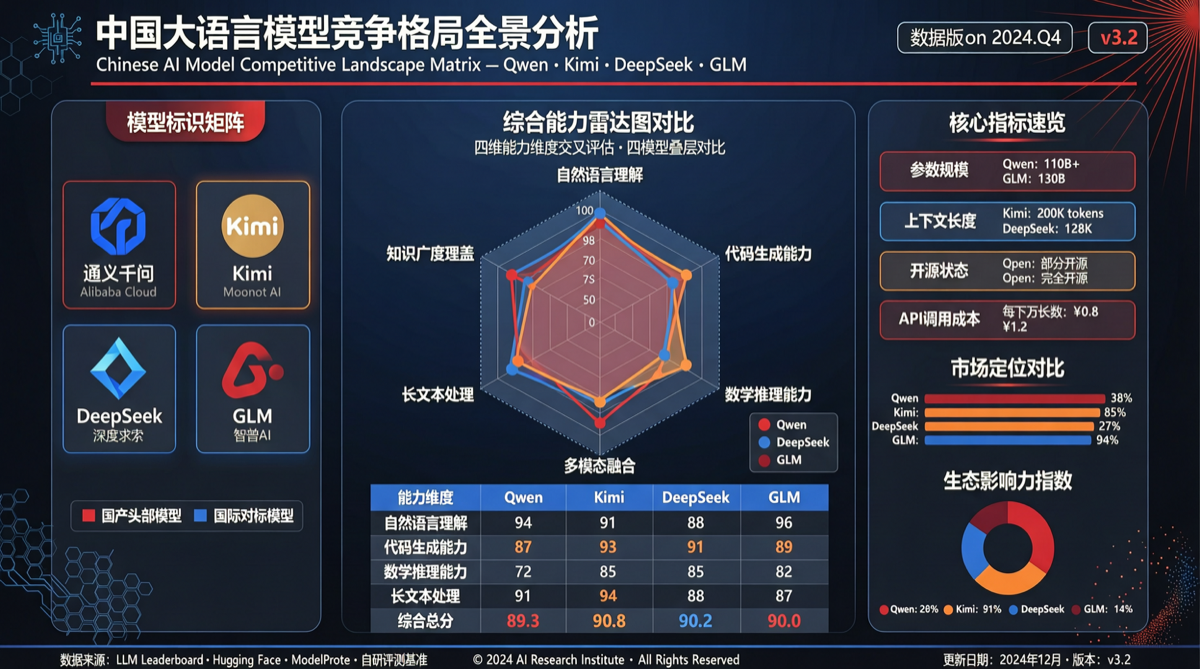
各模型定位矩阵
| 模型 | 核心优势 | 定价策略 | 典型场景 | 竞争对标 |
|---|---|---|---|---|
| Qwen3.6-Plus | 性价比 + 开源生态 | 约为 Claude Opus 的 1/5 | 80% 日常 Agent 工作负载 | Claude Sonnet |
| Kimi K2.6 | 设计和创意能力 | 中端定价 | Arena Design 榜单冠军级表现 | GPT-4o |
| GLM-5.1 | 编码能力 | 高端定价 | 编码 Arena 超越 GPT-5.5 High | GPT-5.5 |
| DeepSeek V4 Pro | 特定评测表现 | 高性价比 | FoodTruck Bench 超越 GPT-5.2 | GPT-5.2 |
| MiniMax M3 | 即将发布,定位待观察 | 待定 | 待定 | Claude Sonnet 4.8 |
关键转折信号
信号一:GLM-5.1 编码能力超越 GPT-5.5 High
智谱 GLM-5.1 在编码 Arena 排行榜上超越了 GPT-5.5 High,这是一个标志性事件。它意味着国产模型在编码领域已经从”追赶者”变为”领先者”。对于主要将 AI 用于编程的团队,GLM-5.1 不再是一个”够用就好”的替代选项,而是一个在某些场景下的首选。
信号二:Qwen3.6-Plus 的 Agent 性价比
社区基准测试显示,Qwen3.6-Plus 以大约 Claude Opus 五分之一的价格处理 80% 的日常 Agent 工作负载。其技术架构——混合稀疏 MoE + 原生 100 万上下文 + 内置工具路由——专门为 Agent 场景优化。
对于需要大量运行 Agent 工作流的团队,这是一个成本效益显著的选择。
信号三:Kimi K2.6 的创意优势
月之暗面 Kimi K2.6 在 Arena Design 榜单上展现出冠军级表现。这反映了国产模型在非编码能力上的差异化——Kimi 在视觉理解、创意设计、内容生成等场景的表现正在超越部分美国模型。
信号四:DeepSeek V4 Pro 的垂直评测优势
DeepSeek V4 Pro 在 FoodTruck Bench 等特定评测中的表现超越了 GPT-5.2。这揭示了一个趋势:在垂直场景下,中国模型可能比通用模型表现更好。
架构差异:为什么国产模型开始差异化
国产模型的差异化不是偶然,而是架构选择和训练策略的结果:
| 模型 | 架构特点 | 差异化来源 |
|---|---|---|
| Qwen3.6 | 混合稀疏 MoE + 1M 上下文 | 为 Agent 场景深度优化,工具调用效率突出 |
| Kimi K2.6 | 继承 DeepSeek V3 设计 + Moonshot Muon 优化器 | 多模态和创意能力强化 |
| GLM-5.1 | 大规模编码数据训练 | 编码专项能力突出 |
| DeepSeek V4 | 推理链优化 + 视觉原语 | 推理和视觉理解能力 |
格局判断
国产模型阵营正在形成差异化优势矩阵,而非单一地追求”全面超越”。这对开发者的模型选型反而更有利——不同任务选不同模型,而非一家独大。
这种格局对美国模型的冲击不在于”某个国产模型全面击败 GPT”,而在于**“每个国产模型在特定场景下都比 GPT 更合适”**。当企业可以根据任务类型选择最优模型时,美国模型的”默认选项”地位就被削弱了。
行动建议
- 模型选型策略:放弃”用一个模型解决所有问题”的思路。为不同任务类型(编码、创意、Agent、推理)选择最适合的模型,可以获得更好的性价比。
- Qwen3.6-Plus 适合:需要大规模运行 Agent 工作流的团队、成本敏感的部署场景、需要开源模型自定义的团队。
- GLM-5.1 适合:以编程为主要用途的团队、需要超越 GPT-5.5 编码能力的场景。
- Kimi K2.6 适合:创意内容生成、视觉理解、设计辅助场景。
- DeepSeek V4 Pro 适合:需要高性价比推理能力的场景、特定垂直领域的深度应用。
- 关注 MiniMax M3:即将发布,可能填补当前国产模型在对话和通用能力上的空白。