Заключение
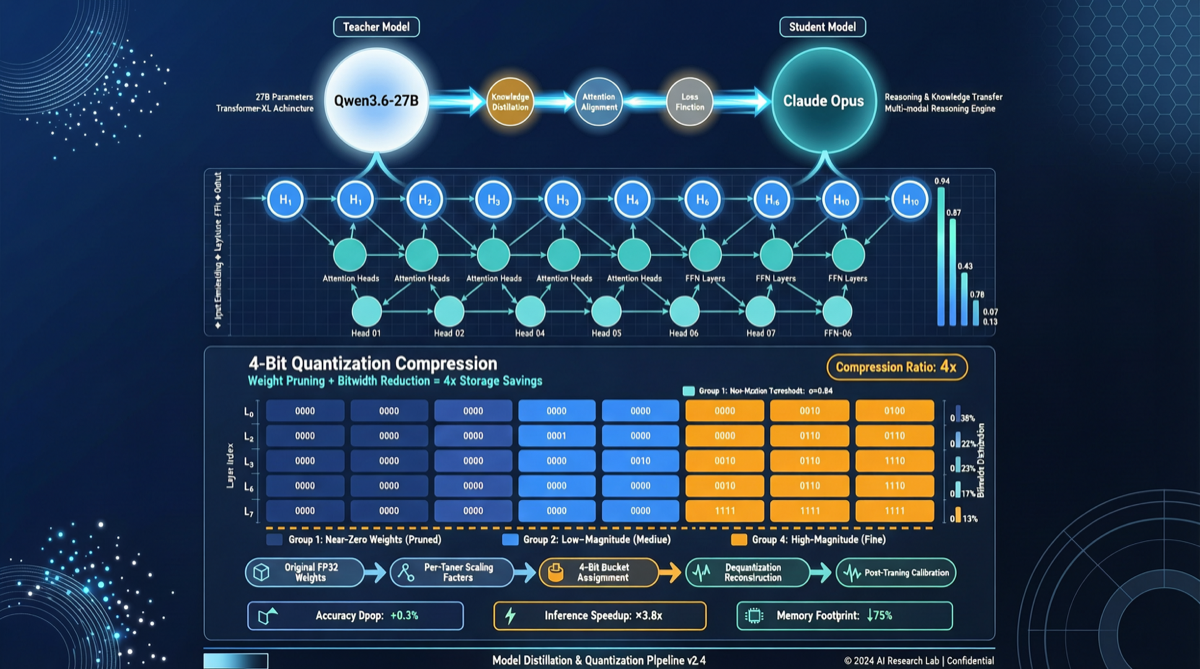
Модель с открытым исходным кодом на 27 миллиардов параметров упаковывает способности рассуждения, которые раньше принадлежали исключительно флагманским моделям с закрытым кодом, в 4-битную квантованную версию, помещающуюся на потребительских GPU — появление Qwen3.6-27B-Claude-Opus-Reasoning-Distill-v2-int4-AutoRound в сообществе Hugging Face вызвало более 4000 просмотров и 67 закладок. Сигнал за этим ясен: барьер входа для открытых моделей рассуждения значительно снижается.
Что именно было дистиллировано
Основная идея модели проста, но эффективна:
- База: Qwen3.5 (оптимизированная для рассуждений версия серии Tongyi Qianwen от Alibaba), 27 млрд параметров
- Источник дистилляции: Цепочки рассуждений (reasoning traces) Claude Opus (флагманская модель Anthropic)
- Квантизация: Схема int4-квантизации фреймворка AutoRound
Дистилляция — это не простое «имитирование вывода». Это изучение путей рассуждения Opus в сложных задачах: как разбивать проблему на части, как пошагово проверять, как выражать степень уверенности в условиях неопределённости.
Процесс обучения выглядит примерно так:
- С помощью Claude Opus генерируется большое количество высококачественных образцов рассуждений (математическое рассуждение, рассуждение в коде, логические цепочки)
- На Qwen3.5 проводится обучение, выравнивая его скрытые состояния с промежуточными представлениями Opus
- Применяется 4-битная квантизация через AutoRound, сжатие до размера, запускаемого на 24 ГБ видеопамяти
Почему 27B + 4 бит — ключевые цифры
Эта комбинация не случайна. После 4-битной квантизации модель с 27 млрд параметров требует лишь около 13–14 ГБ видеопамяти для весов. С учётом KV-кэша потребительский GPU на 24 ГБ (RTX 3090/4090) может полностью загрузить и запустить её.
Сравним ключевые цифры:
| Модель | Параметры | VRAM после квантизации | Уровень рассуждений |
|---|---|---|---|
| Claude Opus 4 | ~тысячи B | Невозможно запустить локально | Флагманский |
| Qwen3.5-72B | 72B | 48 ГБ+ (FP16) | Сильные рассуждения |
| Qwen3.6-27B-int4 | 27B | ~14 ГБ | Близко к Opus |
Это означает: индивидуальные разработчики впервые могут локально запустить модель со способностями рассуждения, приближающимися к Opus.
Реакция сообщества
Пост в X/Twitter собрал 75 лайков и 67 закладок — высокое соотношение вовлечённости для постов о моделях ИИ. Основные мнения из комментариев:
- “Это продвинутое текстовое и визуальное рассуждение, сжатое в 4-битный квантованный пакет” — способности текстового и визуального рассуждения сжаты в 4-битный квантованный пакет
- Внимание сосредоточено на практичности потребительских GPU и разрыве качества рассуждений по сравнению с оригинальным Opus
- Некоторые пользователи уже развернули и протестировали модель локально, сообщая, что «производительность в задачах математического рассуждения и генерации кода превзошла ожидания»
Значение для экосистемы китайских моделей
Серия Qwen всегда следовала пути «открытый код + сильные рассуждения». Появление этой дистиллированной версии имеет знаковое значение в нескольких аспектах:
- Разрыв монополии закрытых моделей рассуждения: Способности рассуждения уровня Opus впервые появляются в форме с открытым кодом на масштабе 27B
- Снижение порога локального развёртывания: Запуск на 24 ГБ VRAM охватывает аппаратные условия подавляющего большинства индивидуальных разработчиков
- Валидация технологии дистилляции: Доказано, что обучение небольших открытых моделей на выводах закрытых флагманов — это осуществимый путь скачка способностей
Как это можно использовать
- Локальное тестирование инференса: Если у вас есть GPU с 24 ГБ VRAM, скачайте модель и протестируйте её напрямую. Загрузка через Ollama или vLLM возможна
- Интеграция с агентными фреймворками: Агентные фреймворки, такие как Hermes Agent и OpenClaw, поддерживают пользовательские эндпоинты моделей — эту модель можно использовать как бэкенд рассуждений
- Сравнительная оценка: Запустите бенчмарки на тех же задачах, что и модели DeepSeek V4 и GLM-5.1, чтобы проверить, соответствуют ли эффекты дистилляции ожиданиям
Риски и ограничения
Дистиллированные модели — не панацея:
- Ограничение знаний: Обучающие данные дистиллированной модели зависят от окна знаний Opus на момент обучения
- Смещение доменов: В вертикальных доменах, где Opus не силён, эффекты дистилляции могут снизиться
- Потери при квантизации: 4-битная квантизация оказывает определённое влияние на точность сложных цепочек рассуждений; для критических сценариев рекомендуется использовать версию FP16
Одним словом
Появление дистиллированной версии Qwen3.6-27B сигнализирует о том, что открытые модели рассуждения совершают скачок от «пригодных к использованию» к «хорошо работающим» — и это «хорошо работающее» уже уместилось в видеопамять потребительского GPU.