主要な発見
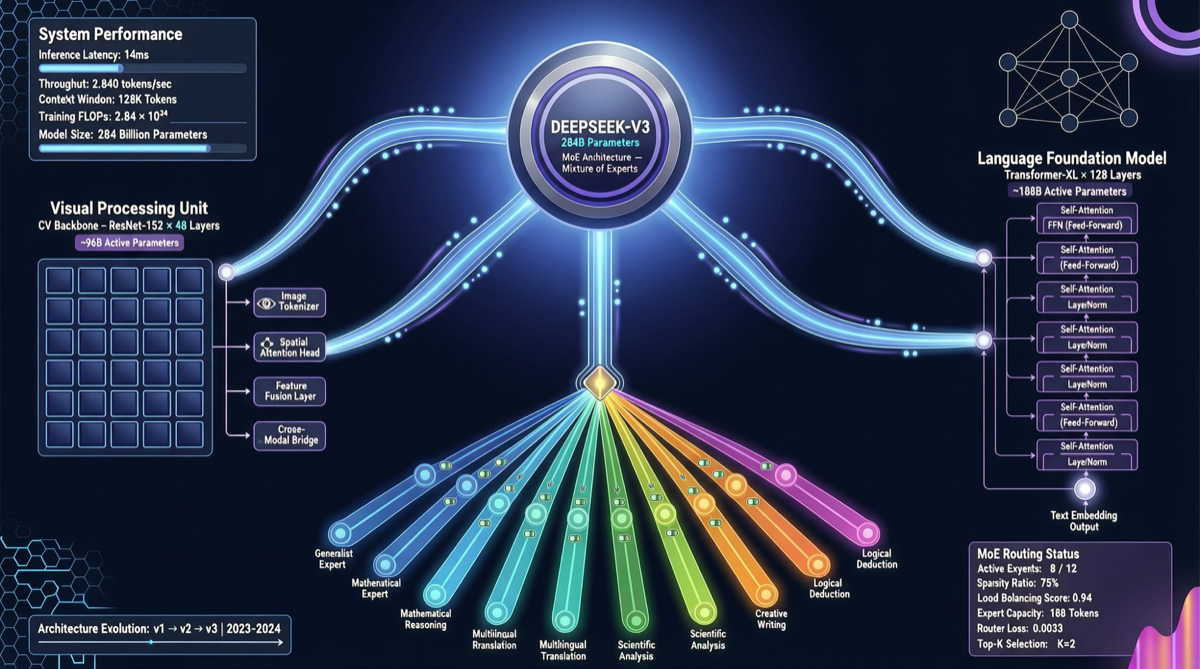
DeepSeekは4月末、マルチモーダル大規模言語モデルに関する論文『Thinking with Visual Primitives』を公開し、視覚と言語を統合するアーキテクチャの技術詳細を明らかにした。本モデルはDeepSeek-V4-Flash MoEを基盤とし(総パラメータ数284B、アクティブパラメータ数13B)、独自開発のDeepSeek-ViT視覚エンコーダーを搭載している。これは、中国国内のマルチモーダルモデルが「継ぎ接ぎ型アプローチ」から「ネイティブアーキテクチャ」へ移行する重要な転換点を示すものである。
技術アーキテクチャの詳細
| コンポーネント | 仕様 | 主要設計 |
|---|---|---|
| 言語基盤 | DeepSeek-V4-Flash | 総パラメータ284B / アクティブ13B、MoEアーキテクチャ |
| 視覚エンコーダー | DeepSeek-ViT | 14×14パッチ分割、3×3空間圧縮後にLLMへ入力 |
| モーダル融合 | ネイティブトークンアラインメント | 視覚特徴を直接言語トークンへマッピング、クロスモーダル投影層は不要 |
| 推論モード | thinking(思考)対応 | 視覚タスクでも思考連鎖(Chain of Thought)推論を有効化 |
視覚エンコーダーの主要なイノベーション
DeepSeek-ViTは従来のViTと同様に14×14のパッチ分割戦略を採用しているが、出力後に3×3の空間圧縮ステップを追加している。この設計により視覚トークン数が大幅に削減され、長序列推論時の計算ボトルネックが緩和される。これは特に高解像度画像を処理する際に極めて重要である。
主要な既存手法との比較:
| 手法 | 視覚エンコーディング戦略 | トークン圧縮率 | 推論レイテンシ |
|---|---|---|---|
| DeepSeek-ViT | 14×14パッチ + 3×3空間圧縮 | 高 | 低 |
| Qwen2-VL | 動的解像度 | 中 | 中 |
| LLaVA-OneVision | 固定パッチ | 低 | 高 |
| InternVL | マルチスケール特徴量 | 中 | 中 |
「Visual Primitives」とは何か?
論文タイトルにある「Visual Primitives」は、モデルが画像を単純に固定ベクトルへエンコーディングするのではなく、視覚情報を基本的な視覚ユニット(プリミティブ)に分解して思考を行うことを指す。この設計により、モデルは推論プロセス中で視覚特徴を細粒度で操作することが可能になる。これは、人間が画像を観察する際にまず基本的な要素(エッジ、形状、色など)を識別し、それらを組み合わせて高次の意味理解へとつなげる過程に類似している。
注目すべき理由
1. MoEマルチモーダルのパイオニア
大多数のオープンソースマルチモーダルモデルはDenseアーキテクチャを採用しているが、DeepSeekはMoEアーキテクチャのマルチモーダルシーンへの適用を初めて成功させた。総パラメータ284Bながらアクティブなのは13Bのみであり、強力な視覚理解能力を維持しつつ、推論コストを許容範囲内に抑えられることを意味する。
2. オープンソース路線の明確なシグナル
論文の公開は、DeepSeekが一貫して掲げるオープンソース戦略を継続していることを示す。今後モデルのウェイトが公開されれば、現時点で最大級のパラメータ数を持つオープンソースマルチモーダルMoEモデルの一つとなり、Qwen2-VLやInternVLのエコシステムポジションと直接競合することになる。
3. V4リリースのタイムラインとの関連性
DeepSeek V4テキストモデルは4月末にリリースされたものの、市場の反応は概ね落ち着いたものだった。本マルチモーダル論文の公開は、DeepSeekの製品ポートフォリオが単一テキストモデルからマルチモーダルへと拡大しつつあることを示唆しており、これは差別化競争戦略の一環である可能性がある。
実践的なアドバイス
- 研究者:論文の方法論セクション、特にマルチモーダルシーンにおける視覚トークン圧縮とMoEルーティングの設計に注目する
- 開発者:ウェイト公開後、同一ベンチマーク上でQwen2-VLとのパフォーマンスを比較検証する
- 企業ユーザー:現段階では様子見を推奨。コミュニティによる評価が成熟してから、本番環境への導入を検討する
DeepSeekが今回選んだ技術路線「MoE + ネイティブ視覚エンコーディング + オープンソース」が、実際に利用可能なモデルウェイトとして実装されれば、中国産マルチモーダルモデルの競争市場に大きな衝撃を与えることになるだろう。