核心结论
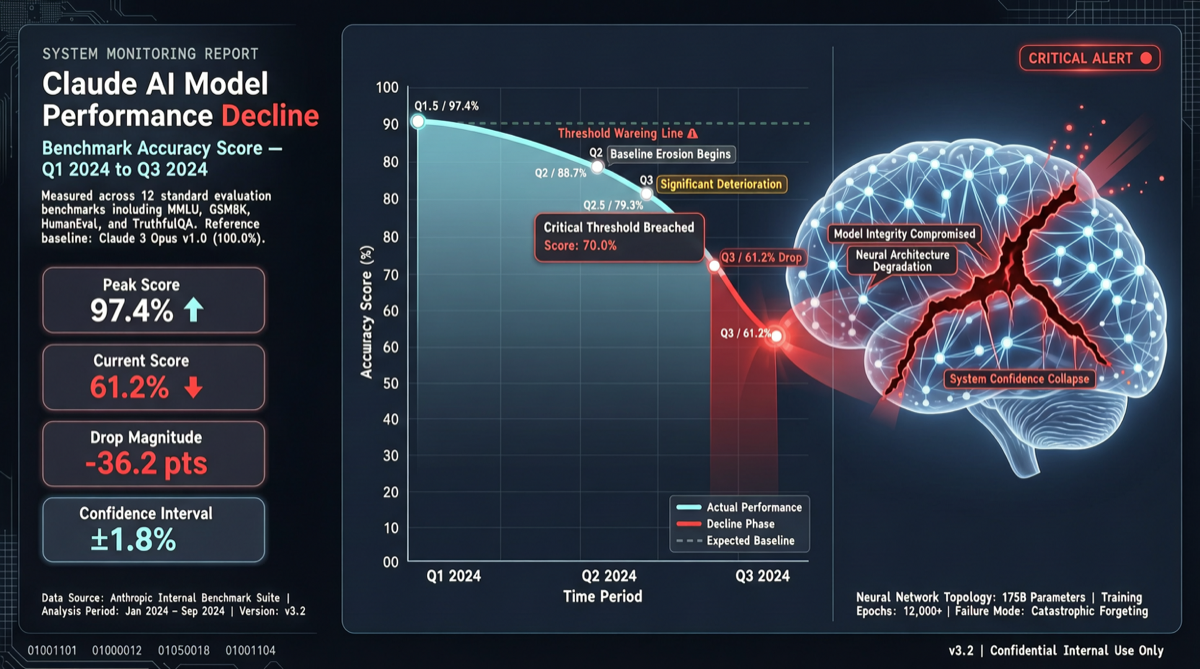
最新幻觉基准测试数据显示,Claude Opus 4.6 的准确率在一周内从 83.3% 暴跌至 68.3%,排名从全球第 2 位跌至第 10 位,跌出公认的”精英梯队”(前 5 名)。
对于依赖 Claude 进行事实密集型工作(法律、医疗、金融分析、学术研究)的用户来说,这是一个需要立即关注的信号。
数据对比
| 指标 | 上周 | 本周 | 变化 |
|---|---|---|---|
| 准确率 | 83.3% | 68.3% | -15.0% |
| 排名 | #2 | #10 | ↓ 8 位 |
| 梯队 | 精英 | 主流 | 降级 |
可能的原因分析
1. 基准测试方法更新
最可能的解释是测试方更新了评估方法学:
- 新增陷阱问题:引入了更隐蔽的”看似合理但实际错误”的测试用例
- 领域扩展:加入了之前未覆盖的领域(如最新事件、专业领域知识)
- 评分标准收紧:对”部分正确”的答案给予更低分数
这在基准测试领域并不罕见——随着模型能力提升,测试难度也需要相应提升以维持区分度。
2. 模型漂移(Model Drift)
另一种可能是模型本身发生了变化:
- API 端静默更新:Anthropic 可能在后端部署了新版本但未通知用户
- 服务降级:为了控制推理成本,可能降低了采样质量
- 缓存策略调整:增加了缓存命中率但牺牲了输出质量
此前 Claude Code 曾出现过因 SDK harness bug 导致的”降智”现象——用户以为是模型变差了,实际上是工具链的问题。
3. 数据集污染
- 训练数据中混入了错误信息
- 微调阶段引入了有偏差的人类反馈
对其他模型的影响
值得注意的是,如果排名下降是基准方法更新导致的,其他模型的分数可能也受到了影响:
| 模型 | 当前准确率 | 趋势 |
|---|---|---|
| GPT-5.5 | ~85% | 稳定 |
| Claude Opus 4.7 | ~87% | 新上榜 |
| Gemini 3.1 Pro | ~82% | 稳定 |
| DeepSeek-V4-Pro | ~80% | 上升 |
| Qwen3.6-Max | ~78% | 稳定 |
Opus 4.7(Claude 5 / Mythos 的迭代版本)的上榜意味着 Anthropic 已经推出了改进版,Opus 4.6 的性能下降可能是资源向新版本倾斜的结果。
用户保护策略
如果你依赖 Claude 进行严肃工作,以下是即时可用的防护措施:
短期应对
-
独立验证事实性声明
- 对日期、统计数据、法规条款等关键信息,用搜索引擎或专业数据库交叉验证
- 不要信任任何 AI 模型在事实问题上的”自信陈述”
-
切换到 Opus 4.7
- 如果可用,升级到 Opus 4.7(幻觉准确率 ~87%)
- 注意 Opus 4.7 已被 Anthropic 纳入 Pro 付费墙
-
添加系统提示约束
对于你不确定的事实,请明确标注"我不确定"而不是猜测。 给出具体数字或日期时,请说明来源。
长期策略
| 工作类型 | 推荐模型 | 原因 |
|---|---|---|
| 代码生成 | Claude Code / Codex | 代码可执行验证 |
| 事实检索 | GPT-5.5 + 搜索 | 较强的检索增强 |
| 创意写作 | Opus 4.6 仍可用 | 幻觉风险低 |
| 法律/医疗 | 多模型交叉 + 人工审核 | 高风险领域不依赖单一模型 |
格局判断
Anthropic 的策略信号
如果 Opus 4.6 的性能下降是 Anthropic 有意为之(将计算资源转移到 Opus 4.7/Mythos),这释放了一个明确信号:Anthropic 正在加速模型迭代周期,旧模型的维护优先级下降。
对于企业用户来说,这意味着:
- 锁定特定模型版本的能力变得更加重要
- API 合同中应包含性能 SLA 条款
- 需要建立自动化的模型性能监控
行业启示
幻觉基准的重要性正在上升。过去用户主要关注 LMSYS Arena 的综合排名,但现在:
- 幻觉率成为企业选型的关键指标
- 特定领域准确率(法律、医疗、金融)比通用排名更有参考价值
- 性能稳定性(波动幅度)成为新的评估维度