Проблема стоимости оценки Agent
Production AI Agent нуждается в постоянной оценке и guardrails: нужно обнаруживать hallucinations, предотвращать действия вне полномочий и следить за корректным форматом вывода. Многие команды используют LLM-as-Judge: большая модель, например GPT-5, оценивает качество ответа другого Agent.
У этого подхода есть две проблемы: высокая стоимость и заметная задержка. Кроме того, сама большая модель может пропускать важные ошибки.
Vibe Training от Plurai предлагает другой путь: не просить большую модель оценивать каждый ответ, а обучить специализированный оценщик через описание того, как должно выглядеть хорошее поведение.
Как работает метод
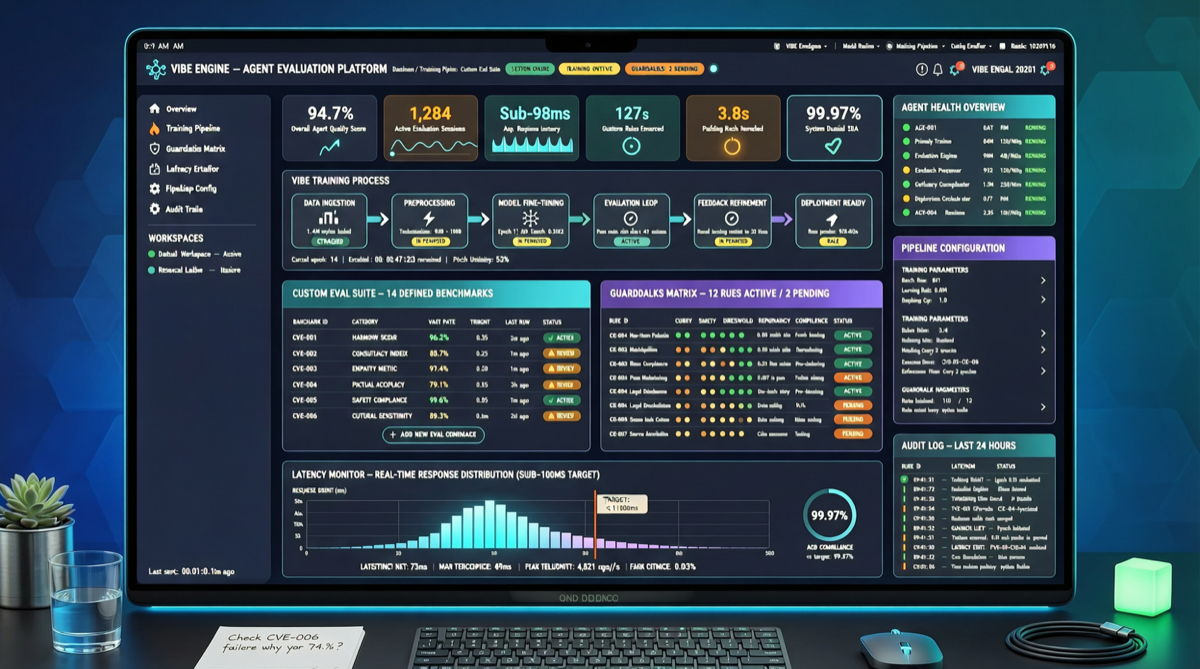
Workflow Vibe Training состоит из трёх шагов:
- Описание поведения: команда на естественном языке описывает, что Agent должен делать, например «не выдумывать API endpoints» или «явно отмечать неопределённую информацию».
- Калибровка примеров: система выбирает из production logs примеры, лучше всего отражающие эти признаки, а команда подтверждает выбор.
- Деплой endpoint для оценки: создаётся специализированный endpoint с задержкой ниже 100 мс, который можно встроить в runtime pipeline Agent.
Главное отличие от LLM-as-Judge в том, что оценщик адаптирован под конкретного Agent и конкретное поведение, а не пытается универсальной моделью покрыть все сценарии.
Данные Plurai
По опубликованным данным Plurai:
- Стоимость: в 8 раз ниже, чем использование GPT-5-mini как judge model
- Failure rate: примерно на 43% ниже базовой линии
- Задержка: меньше 100 мс, подходит для realtime interception
- Время внедрения: минуты вместо недель написания правил
Эти данные получены в собственных тестах Plurai и пока не имеют независимого воспроизведения. Командам стоит сначала проверять подход на малом трафике.
Сравнение с традиционными подходами
| Критерий | LLM-as-Judge | Rule Engine | Vibe Training |
|---|---|---|---|
| Стоимость | Высокая, платёж за каждый вызов | Низкая после разработки | Средняя, затем дешёвый inference |
| Задержка | 2-10 секунд | <10 мс | <100 мс |
| Точность | Большая модель тоже ошибается | Точно, но покрытие ограничено | Оптимизировано под сценарий |
| Поддержка | Prompt tuning | Постоянное обновление правил | Периодическая калибровка |
| Скорость внедрения | Быстро | Недели | Минуты |
Где подходит
Подход полезен для команд с production logs, realtime guardrails, дорогим LLM-as-Judge и желанием быстро запустить оценку Agent.
Ограничения
Нужно достаточно данных реальных взаимодействий. Для нового Agent без истории эффект ограничен. Интерпретируемость ниже, чем у явных правил, а независимая валидация пока отсутствует.