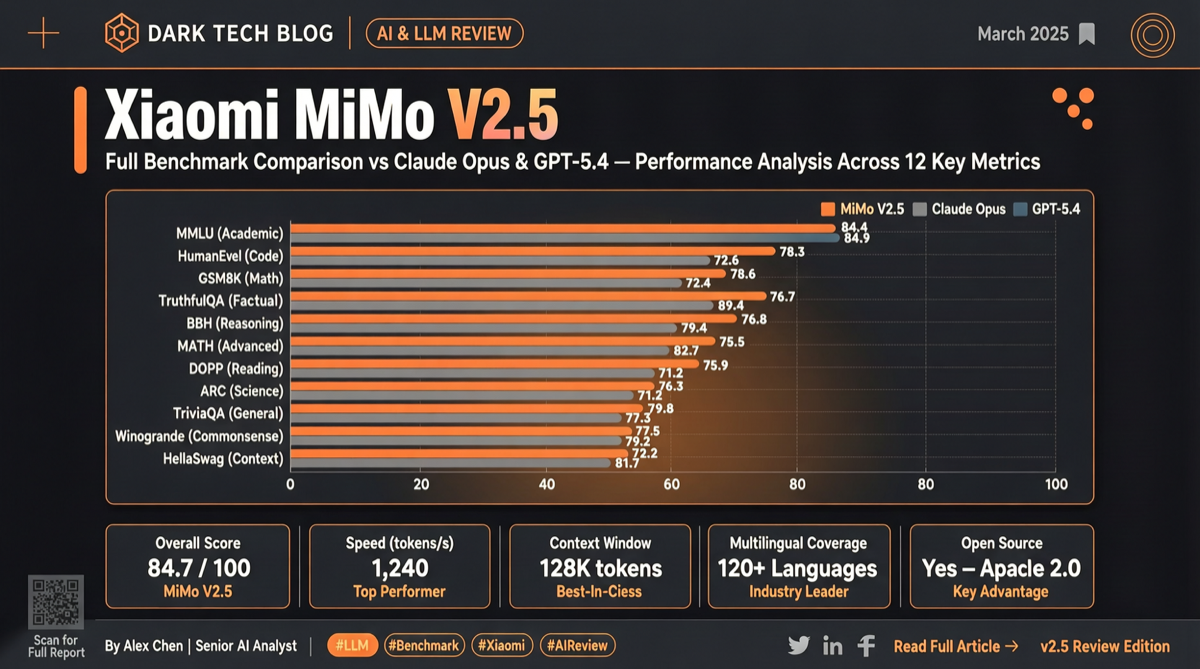
Xiaomi MiMo-V2.5 series officially open sourced early this morning. Specs and benchmarks are already available online. This article doesn’t pile up numbers — it answers one question:
Can an open-source model replace closed-source models in real-world tasks?
We tested across three dimensions: long-cycle programming, fuzzy instruction understanding, and voice capabilities. Bottom line first: it works, and in some scenarios, better than expected.
Long-Cycle Programming: 4 Hours Non-Stop, 672 Tool Calls
The core metric isn’t how fast code is written, but whether it can complete the full cycle without crashing, drifting, or forgetting.
Test 1: Building a complete compiler from scratch (Peking University SysY project)
This is a compiler course-level complex engineering task covering lexical analysis, syntax analysis, intermediate code generation, RISC-V backend, and performance optimization. MiMo-V2.5-Pro performance:
- Time: 4.3 hours
- Tool calls: 672
- Score: 233/233 perfect
- Non-stop, no human intervention
This means it maintains context coherence across over a thousand tool calls — many Agent models start “forgetting” previous decisions after dozens of rounds. MiMo-V2.5-Pro has solidly entered the first tier on this dimension.
Test 2: 4-hour macOS desktop system clone
React 18 + TypeScript + Zustand + Tailwind CSS + Vite, 68 components supporting 54 native applications. Including boot animation, user login, window management (drag/zoom/minimize/maximize/Traffic Lights logic), Dock scaling, Spotlight search, Launchpad, and even a working Safari simulator.
4 hours, no interruptions, no human takeover. This validates not “can it write code,” but can it maintain architectural consistency across a large project — state sharing across 54 apps, window layer management, animation synchronization. These require global vision, which is exactly where Agent models typically struggle.
Fuzzy Instruction Understanding: From One Sentence to a Complete Product
Beyond coding, fuzzy instruction following is another key upgrade of the MiMo-V2.5 series.
Test: Mountain-style healing digital journal
Given only one line:
Help me make a mountain-style healing website, like a travel journal, natural, quiet, with breathing room, the feeling of escaping the city into the wilderness.
No color scheme, no fonts, no layout, no animation specs. Like a product manager saying “I want a page with a vibe.”
MiMo-V2.5’s understanding and output:
- Earth-tone palette, handwritten-style fonts, ink-textured backgrounds
- Mountain parallax scrolling, depth from near-far layers
- Floating particles + mouse-following soft glow
- Checkbox bounce animations, element fade-in/fade-out
- Interactive features: pack equipment can be marked and selected
The value of this test: if your users can’t write prompts, MiMo-V2.5 can still reconstruct reasonable interaction, visual, and animation solutions from a vague description. This is critical for non-technical user scenarios.
Voice Capabilities: Full TTS + ASR Suite
The V2.5 series isn’t just a code model — it includes TTS (text-to-speech) and ASR (speech recognition).
- TTS: Supports text-based voice creation (no reference audio needed, generate voice directly from text description), zero-shot cloning. Three character voices tested (young rational female, middle-aged night market vendor, foodie teen) — each distinct, no bleed-over.
- ASR: SOTA-level for Chinese and English, supports Cantonese, Sichuanese, Wu dialect, Minnan dialect, can even transcribe lyrics with background music. Cantonese transcription accuracy: 99.999%.
Both models (Pro and standard) come with 1M context window.
Comparison with Closed-Source Models
| Dimension | MiMo-V2.5-Pro | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | ~Opus level | Baseline | Baseline | Behind |
| ClawEval Pass³ | 64% | Comparable | Comparable | - |
| Token per trajectory | ~70K | 120-180K | 120-180K | - |
| Context window | 1M | - | - | - |
| License | MIT open source | Closed | Closed | Closed |
Same Agent capability, MiMo uses 40%-60% fewer tokens. More task cycles on the same compute budget.
Recommendation
Use now if:
- Building Agent systems and need an open-source baseline
- Long-cycle programming tasks (compilers, large refactoring, multi-component systems)
- Non-technical user scenarios where fuzzy instruction understanding is essential
- Need full-stack voice synthesis + recognition
Wait and observe if:
- Real-world Chinese performance — benchmarks are English-heavy
- Actual deployment hardware requirements
- Independent community verification beyond vendor claims